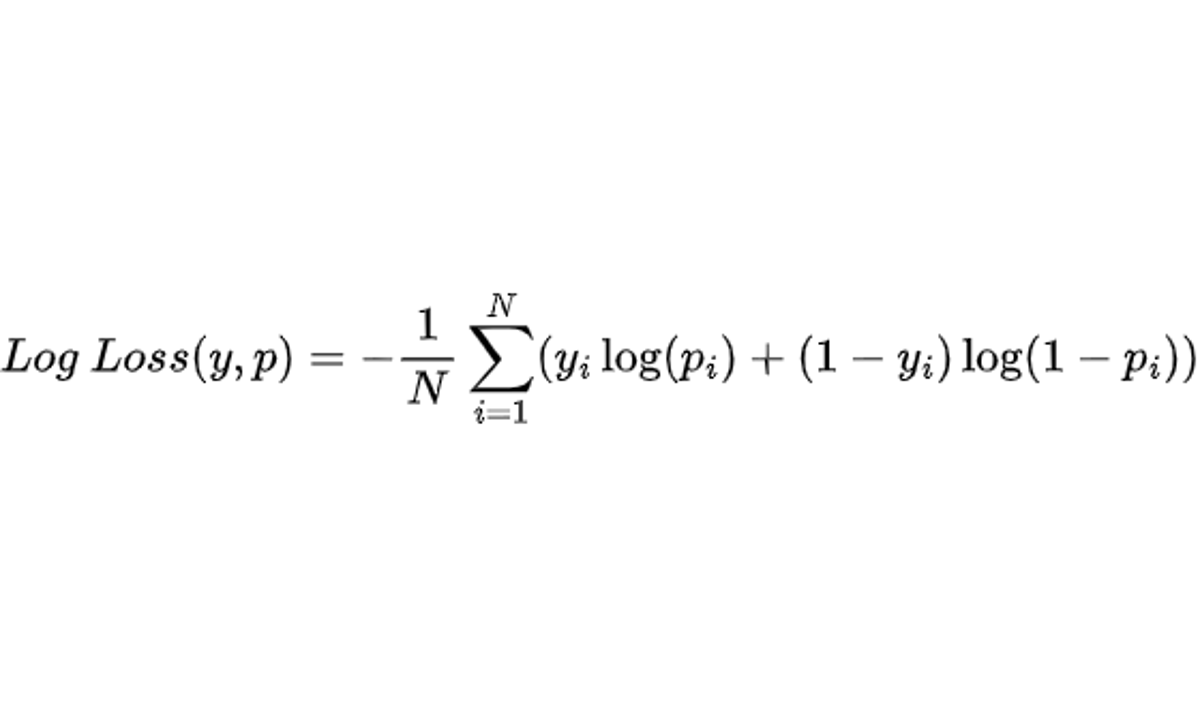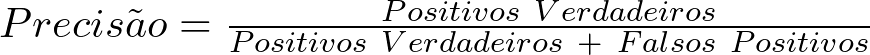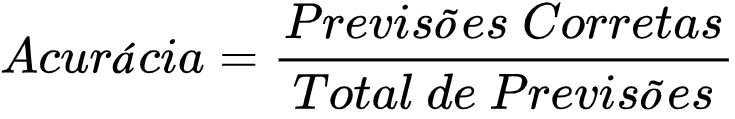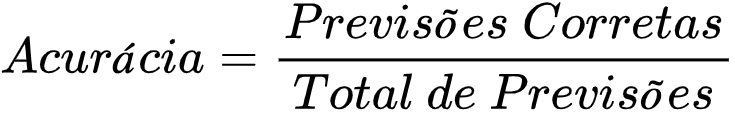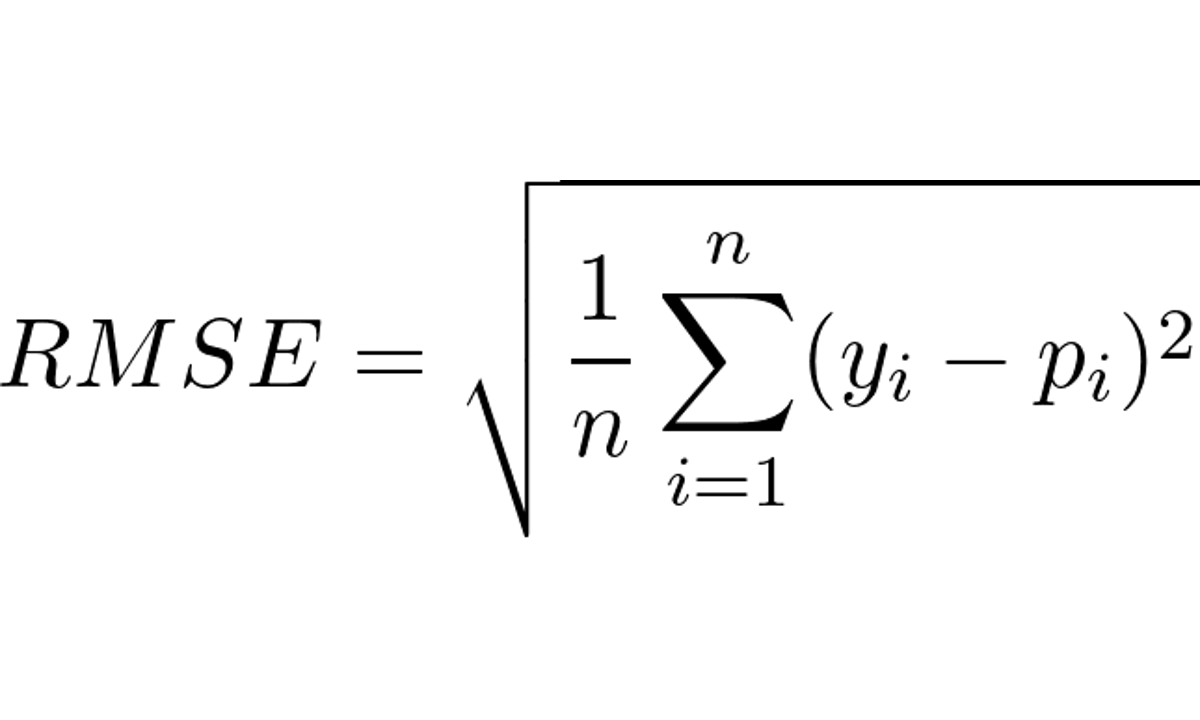
RMSE (Raiz Do Erro Quadrático Médio) Em Machine Learning
Índice O Que é RMSE? Qual a Fórmula do RMSE? Como Interpretar o RMSE? Quanto Menor o RMSE Melhor? Como Calcular o RMSE Usando Scikit-learn em Python? Como Calcular o RMSE em R? Diferença Entre RMSE e MSE Diferença Entre RMSE e MAE Diferença Entre RMSE e MAPE Diferença Entre RMSE e R-quadrado Como o RMSE é Afetado Por Outliers? O RMSE Pode Ser Usado Para Avaliar Modelos De Classificação?...