
Índice
- O Que É ROC AUC?
- Como Interpretar ROC AUC?
- Como Calcular ROC AUC Com Scikit-learn Em Python?
- Como Calcular ROC AUC Em R?
- Como Usar ROC AUC Com Mais de Duas Classes?
- Diferença Entre ROC AUC e Acurácia
- Diferença Entre ROC AUC e F1 Score
- Diferença Entre ROC AUC e Log Loss
O Que É ROC AUC?
ROC AUC é uma métrica de avaliação em machine learning usada para avaliar o desempenho de modelos de classificação.
Seu nome significa Área Sob A Curva Característica de Operação do Receptor.
Parece complicada, mas vou te explicar de maneira simples.
Pense nesta curva como um gráfico que mostra a fração de positivos verdadeiros no eixo Y e a fração de falsos positivos no eixo X para diferentes pontos de corte da previsão atribuída pelo modelo aos exemplos.
O AUC é a área sob esta curva.

Como Interpretar ROC AUC?
O ROC AUC indica o quão bom seu modelo é em ranquear exemplos positivos acima dos exemplos negativos.
A analogia que vou te contar abaixo me ajudou a entender de uma vez por todas como interpretar um valor de ROC AUC.
Imagine que você tenha duas caixas, uma com um cartão para cada um de seus exemplos positivos e outra com um cartão para cada um de seus exemplos negativos.
Em cada cartão está escrito a pontuação que o modelo atribuiu deste exemplo ser positivo.
Este número pode ser a probabilidade, mas isso não é obrigatório, já que a ROC AUC é uma medida mais preocupada com o ranqueamento de exemplos do que com a precisão matemática.
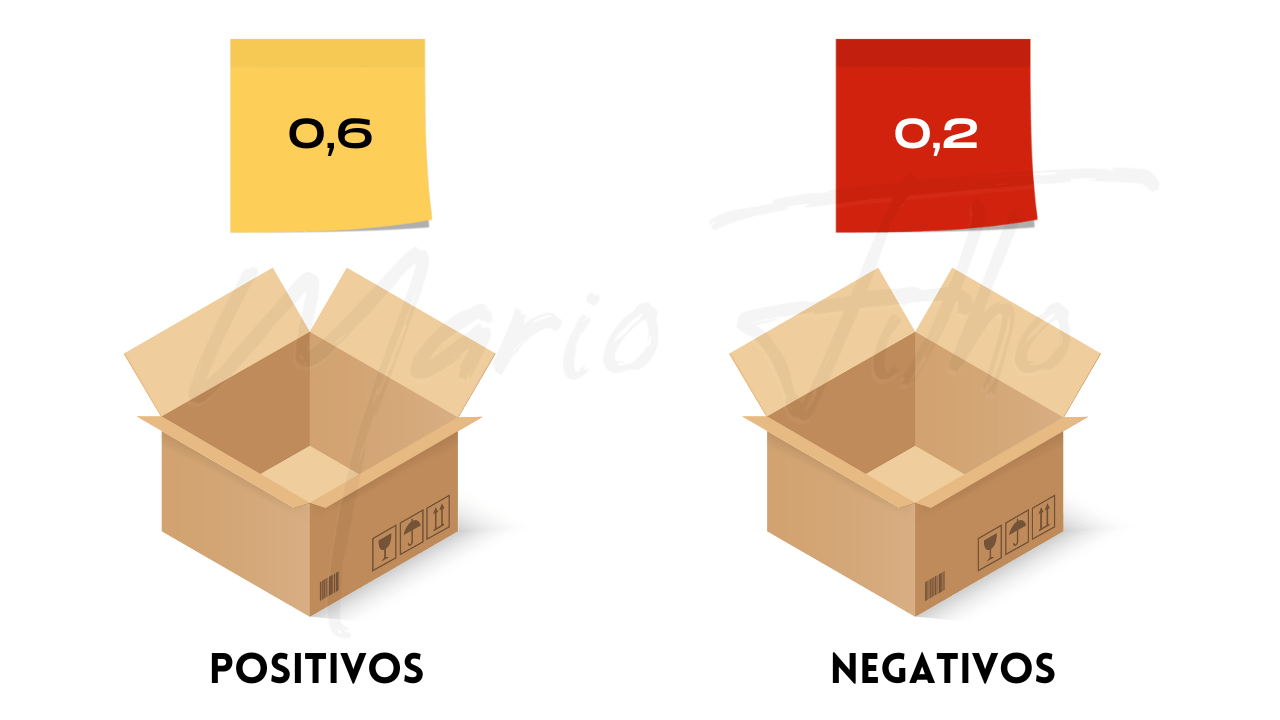
Você decide sortear um cartão positivo e um negativo por 5 vezes, sempre recolocando os cartões sorteados de volta nas caixas.
Após o sorteio, você faz uma tabela, indicando as probabilidades dos cartões sorteados cada vez que você os retirou das caixas.
Lembrando que as probabilidades não precisam somar um porque estamos falando de dois exemplos separados e não da probabilidade do mesmo exemplo ser da classe positiva ou negativa.
| Sorteio | Exemplo Positivo | Exemplo Negativo |
|---|---|---|
| 1 | 0,6 | 0,2 |
| 2 | 0,8 | 0,4 |
| 3 | 0,7 | 0,8 |
| 4 | 0,9 | 0,5 |
| 5 | 0,5 | 0,3 |
Agora você conta quantas vezes o exemplo positivo tinha uma pontuação maior do que o negativo e divide pelo número total de sorteios.
Neste caso 4/5 = 0,8. Este é o valor do ROC AUC.
Em resumo, quanto maior o valor do ROC AUC, melhor o modelo está ranqueando exemplos positivos acima dos negativos.
Ele costuma variar de 0,5 (significa que o modelo não tem qualquer poder preditivo) a 1,0 (significa que o modelo prevê as classes perfeitamente).
Na prática você encontra números menores que 0,5, indicando algum problema grave nos dados ou no algoritmo que você treinou.
Como Calcular ROC AUC Com Scikit-learn Em Python?
Para calcular ROC AUC sobre suas previsões usando scikit-learn basta usar a função roc_auc_score
from sklearn.metrics import roc_auc_score
y_true = [0, 0, 1, 1]
y_pred = [0.1, 0.4, 0.35, 0.8]
roc = roc_auc_score(y_true, y_pred)
print(roc)
Seguindo o padrão do scikit-learn, você deve passar os rótulos corretos no primeiro argumento (y_true) e as previsões da classe positiva do modelo no segundo argumento (y_pred).
Preste atenção que o y_pred não deve ser apenas zeros e uns.
A função até consegue calcular se você passar as classes previstas, mas o valor estará incorreto.
Pense no y_pred como uma pontuação (que pode ser uma probabilidade) que quanto maior o valor, maior a chance do exemplo pertencer à classe positiva.
Como Calcular ROC AUC Em R?
Para calcular o ROC AUC na linguagem R, vamos usar as funções auc e roc da biblioteca pROC.
Assim como no scikit-learn, a função roc requer dois argumentos: y_true é o vetor com os rótulos verdadeiros para cada exemplo e y_pred é um vetor com as pontuações da chance do exemplo pertencer à classe positiva.
Depois de criado o objeto roc_obj, basta passa-lo à função auc para obter o valor da área sob a curva ROC.
library(pROC)
y_true <- c(0, 0, 1, 1)
y_pred <- c(0.1, 0.4, 0.35, 0.8)
roc_obj <- roc(y_true, y_pred)
# Para obter a pontuação ROC AUC, use a função auc do objeto roc criado
roc_auc <- auc(roc_obj)
# Imprima a pontuação ROC AUC
print(roc_auc)
Como Usar ROC AUC Com Mais de Duas Classes?
Podemos expandir essa métrica para avaliar mais de uma classe.
Quando eu trabalhava na Upwork eu usava uma estratégia “um contra todos” para monitorar o ROC AUC de cada classe nos modelos de ranqueamento de freelancers.
Você pode fazer a média dos valores, ponderada ou não, para resumir tudo em apenas um número, mas eu recomendo que você observe cada classe separadamente.
Veja abaixo como fazer este cálculo usando o scikit-learn.
Imagine que temos 6 exemplos e 3 classes: 0, 1 e 2.
from sklearn.metrics import roc_auc_score
# Cada linha da y_pred se refere à probabilidade do exemplo pertencer às classes 0, 1 e 2
y_true = [0, 0, 1, 1, 2, 2]
y_pred = [[0.1, 0.7, 0.2],
[0.1, 0.8, 0.1],
[0.3, 0.1, 0.6],
[0.3, 0.2, 0.5],
[0.7, 0.1, 0.2],
[0.8, 0.1, 0.1]]
# Calcule a pontuação ROC AUC para cada classe usando o parâmetro average=None
roc_auc_scores = roc_auc_score(y_true, y_pred, average=None, multi_class='ovr')
# Calcule a média simples das pontuações ROC AUC usando o parâmetro average=macro
roc_auc_mean = roc_auc_score(y_true, y_pred, average='macro', multi_class='ovr')
As classes estão ordenadas na lista y_true apenas para ficar mais fácil de entender, mas elas podem estar em qualquer ordem, desde que alinhadas às posições dos exemplos correspondentes.
Na primeira chamada da função roc_auc_score o parâmetro average é definido como None para que a métrica seja mostrada para cada classe individualmente.
O parâmetro multi_class é definido como 'ovr' (um contra o resto) para que ela seja calculada usando uma classe selecionada como positiva e as outras como negativas.
Isso é feito uma vez para cada classe, para simular problemas binários e poder calcular a métrica mesmo com mais de duas classes.
A função retorna uma array do Numpy com as pontuações ROC AUC para cada classe, armazenada na variável roc_auc_scores (preste atenção ao “s” no final do nome da variável!).
In [4]: roc_auc_scores
Out[4]: array([0. , 0.375, 0.25 ])
Ignore o fato dos valores serem menores que 0,5, isso acontece porque temos apenas dois exemplos em cada classe para facilitar a explicação. Num caso real, os números fariam mais sentido.
Depois, a função roc_auc_score é chamada novamente, mas desta vez o parâmetro average é definido como 'macro' para retornar a média simples da array acima.
In [5]: roc_auc_mean
Out[5]: 0.20833333333333334
Novamente, ignore o valor abaixo de 0,5.
Vou ficar devendo o exemplo em R porque é muito complicado (surpresa!) para mim que não uso a linguagem fora de tutoriais há muitos anos! 😄
Diferença Entre ROC AUC e Acurácia
A acurácia é uma métrica muito mais simples: a porcentagem de classificações corretas feitas pelo modelo.
Para calculá-la, você precisa definir um ponto de corte para a probabilidade de um exemplo pertencer a uma das classes.
Geralmente esse ponto de corte é 0,5, ou seja, todos os exemplos com previsões acima de 0,5 são considerados da classe positiva, enquanto os que estiverem abaixo, são atribuídos à classe negativa.
Quando você usa a função predict do scikit-learn em casos binários, ele esconde esse passo e atribui automaticamente a classe positiva para os exemplos com probabilidade maior que 0,5.
Dependendo do ponto de corte escolhido, sua acurácia vai parecer melhor ou pior, sem qualquer mudança no modelo que gerou as previsões.
A ROC AUC, por outro lado, não requer um ponto de corte.
Em vez disso, ela mede a capacidade do modelo de distinguir entre as duas classes em todos os pontos de corte possíveis.
Isso significa que ela é uma métrica mais robusta da performance do modelo do que a acurácia, pois ela avalia o modelo sem depender de escolher o ponto de corte ideal.
Pela mesma razão, a ROC AUC é uma métrica melhor para casos em que as classes são bastante desbalanceadas (por exemplo, 10% de positivos e 90% de negativos).
Nestes casos geralmente nos importamos em prever corretamente a classe minoritária e a ROC AUC é justamente calculada sobre as taxas de positivos verdadeiros e falsos.
Ou seja, no exemplo acima, se você prever que todos os exemplos de seus dados de validação são negativos, sua acurácia será 90% mas seu ROC AUC será 0,5, mostrando que o modelo não está verdadeiramente bom.
Um truque simples para melhorar imediatamente seu ROC AUC ao treinar modelos do scikit-learn sobre classes desbalanceadas é usar o argumento class_weight=’balanced’.
Isso faz com que o modelo dê mais peso aos erros cometidos na classe minoritária durante o treinamento e puxe a previsão desses exemplos para cima, ranqueando-os acima dos negativos.
Diferença Entre ROC AUC e F1 Score
O F1 Score é uma métrica que equilibra a precisão (proporção de previsões corretas) e o recall (proporção de instâncias positivas identificadas corretamente).
Apesar de também focar bastante na classe positiva e ser mais útil em casos de classes desbalanceadas do que a acurácia, ele também sofre do problema de precisar de um ponto de corte definido previamente.
Por isso eu prefiro usar a ROC AUC para otimizar o modelo e, depois de maximizá-lo, escolher o ponto de corte adequado para a taxa de positivos verdadeiros e falsos adequada à aplicação.
Diferença Entre ROC AUC e Log Loss
Log Loss é uma métrica muito comum para otimizar e avaliar modelos de classificação mas serve um propósito diferente.
A ROC AUC mede a capacidade do modelo de ranquear exemplos da classe positiva acima dos exemplos da negativa, enquanto a Log Loss mede a qualidade do modelo em estimar a probabilidade correta de um exemplo pertencer a uma classe.
A Log Loss penaliza modelos que são muito confiantes em suas previsões erradas (probabilidades próximas de 0 ou 1).
A ROC AUC não se importa com estes números, desde que os exemplos positivos estejam com valores maiores que os negativos.
A Log Loss é essencial quando você precisa de probabilidades calibradas à realidade.
Essa diferença fica mais clara com um exemplo sobre apostas em futebol (ignorando empates).
Imagine que você é um apostador e seu modelo diz que o time da casa tem uma probabilidade de 60% de vencer.
Neste caso, você quer maximizar a sua expectativa de ganho ao longo do tempo, então você precisa avaliar o valor esperado da aposta para decidir se deve fazê-la.
O valor esperado de uma aposta é dado pelo seguinte cálculo:
Valor esperado = (Probabilidade de ganhar * Valor ganho na vitória) - (Probabilidade de perder * Valor perdido na derrota)
Se você tiver probabilidades bem calibradas, o valor esperado de cada aposta será mais preciso e você poderá tomar decisões mais informadas, o que aumenta seu lucro ao longo do tempo.
Para simplificar, vamos considerar que você ganha ou perde o mesmo valor, 100 reais, de acordo com o resultado da aposta.
Com base nas probabilidades, o valor esperado da aposta seria:
Valor esperado = (0,6 * 100 reais) - (0,4 * 100 reais) = 20 reais
Ou seja, você ganhará em média 20 reais por aposta se a probabilidade de 60% estiver correta.
No entanto, se as probabilidades estiverem mal calibradas, o valor esperado da aposta pode ser diferente e isso pode afetar o seu lucro ao longo do tempo.
Imagine que probabilidade real do time da casa ganhar seja de 40% em vez de 60%.
Ou seja, se esse mesmo jogo acontecer 100 vezes, o time da casa ganhará cerca de 40 jogos e perderá 60.
O valor esperado da aposta seria:
Valor esperado = (0,4 * 100 reais) - (0,6 * 100 reais) = -20 reais
Agora, em vez de ganhar, você perderá em média 20 reais por aposta!
Neste caso a probabilidade de seu modelo não está alinhada com a proporção real de vitórias do time da casa, ela não está bem calibrada.
Em resumo, otimizar a log loss vai puxar suas previsões para perto das proporções reais da classe positiva acontecer, enquanto a ROC AUC estará apenas preocupada em ranquear os exemplos positivos acima dos negativos, não importando se os valores específicos das previsões estão alinhados com a realidade.
Ou seja, se apenas a ordem dos exemplos importa, use ROC AUC.
Se a probabilidade específica atribuída a um exemplo é mais importante, use Log Loss.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.