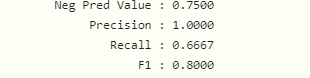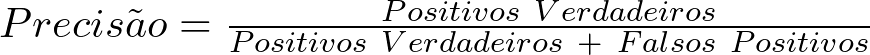
Se você está começando a trabalhar com machine learning, é importante saber como avaliar o desempenho dos seus modelos.
Existe uma infinidade de métricas de avaliação e neste artigo, vamos nos concentrar em três das mais populares para avaliar modelos de classificação: precisão, recall e F1 score.
A precisão mede a quantidade de vezes que o seu modelo acerta em relação ao total de vezes que ele tenta acertar.
O recall mede a quantidade de vezes que o seu modelo acerta em relação ao total de vezes que ele deveria ter acertado.
O F1 Score é uma métrica que combina precisão e recall de maneira equilibrada.
Neste artigo, vou explicar o que cada uma dessas métricas significa, como calcular usando a biblioteca Scikit-learn em Python e na linguagem R.
Ficou animado para aprender mais sobre essas métricas fundamentais do machine learning? Então, vamos lá!
Índice
- O Que É Precisão?
- Qual A Fórmula Da Precisão Na Matriz De Confusão?
- Como Calcular Precisão Com Scikit-learn Em Python
- Como Calcular Precisão Em R
- O Que É Recall?
- Qual A Fórmula Do Recall Na Matriz De Confusão?
- Como Calcular Recall Com Scikit-learn Em Python
- Como Calcular Recall Em R
- O Que É F1 Score?
- Qual A Fórmula Do F1 Score?
- Por Que O F1 Score Usa A Média Harmônica?
- Como Calcular F1 Score Com Scikit-learn Em Python
- Como Calcular F1 Score em R
O Que É Precisão?
A precisão mede o quanto podemos confiar num modelo quando ele prevê que um exemplo pertence a uma determinada classe.
Pense num caso de classificação binária, onde temos apenas duas classes, positiva e negativa, para ficar mais fácil entender.
A precisão é o número de exemplos que seu modelo previu como positivos e acertou dividido pelo número total de exemplos que ele previu como positivos.
Ou seja, dos que ele previou como positivos, quantos ele acertou.
Imagine que você tem um modelo de machine learning que tenta prever se uma pessoa tem ou não uma doença rara.
Nos dados de avaliação seu modelo previu que 80 pessoas têm a doença, mas apenas 60 delas realmente tinham a doença, então a precisão dele é de 60/80 = 75%.
No futuro, podemos esperar que, se o modelo prever que uma pessoa tem a doença, em 75% dos casos ele estará certo.
Qual A Fórmula Da Precisão Na Matriz De Confusão?
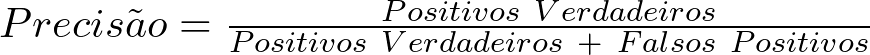
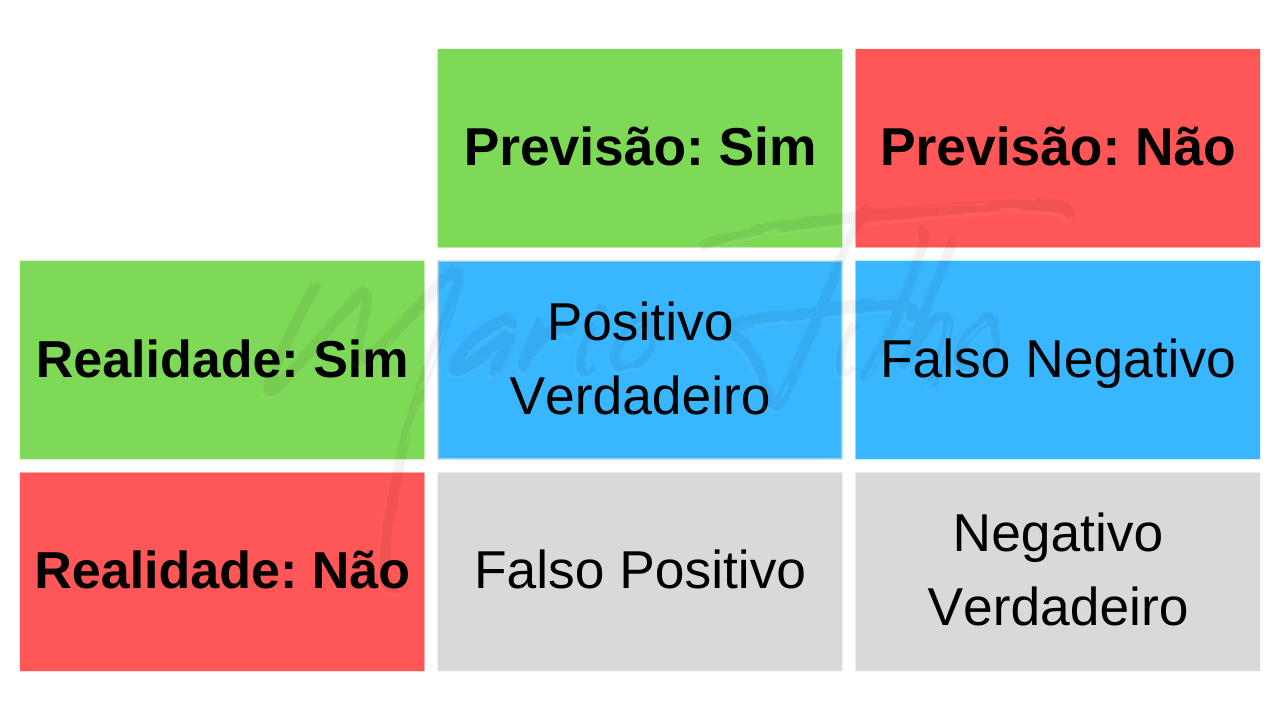
Colocando em termos técnicos, a precisão é a razão entre o número de verdadeiros positivos e o número total de previsões positivas feitas pelo modelo (verdadeiros positivos e falsos positivos).
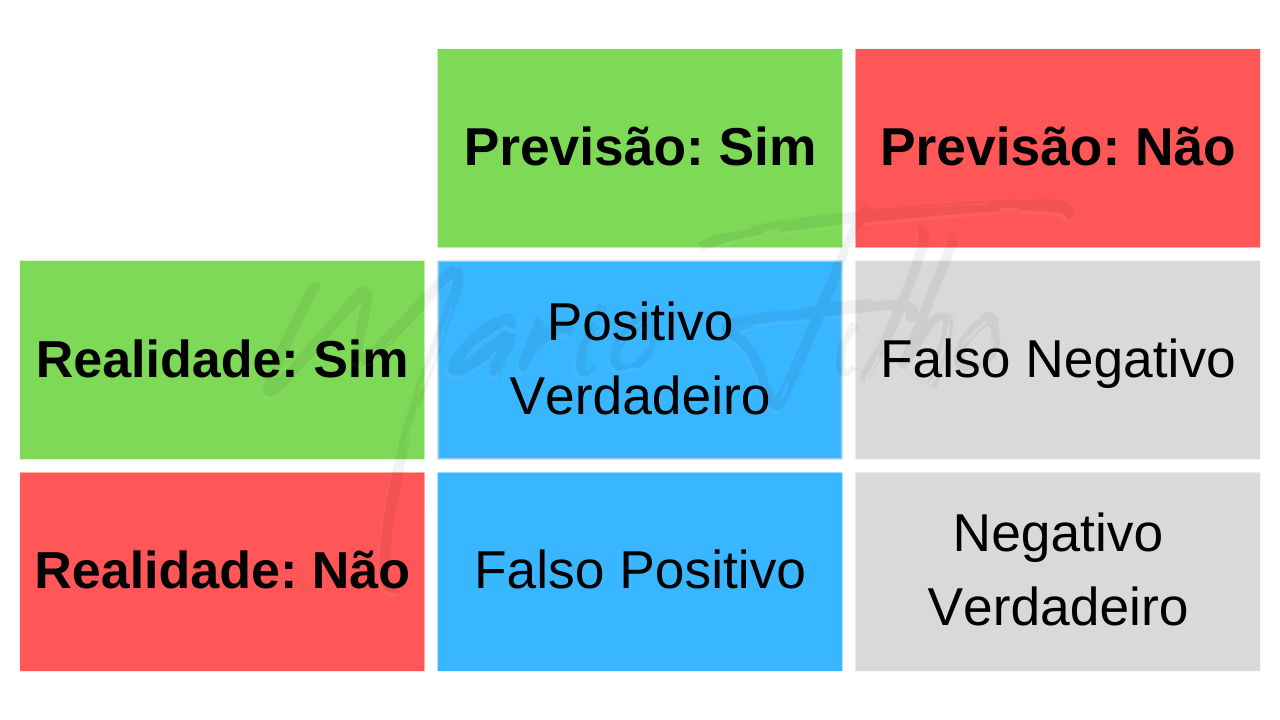
Você pode extrair estes elementos da coluna referente à classe desejada na matriz de confusão (indicada pelas células azuis no diagrama abaixo).
Como Calcular Precisão Com Scikit-learn Em Python
Veja abaixo como você pode usar o scikit-learn, a biblioteca mais popular de Python para machine learning, para calcular facilmente a precisão de seu modelo.
from sklearn.metrics import precision_score
# Suponha que você tenha os seguintes rótulos verdadeiros e previstos pelo modelo:
y_true = [0, 1, 1, 0, 1, 0, 1, 0, 0, 1]
y_pred = [0, 0, 1, 0, 1, 0, 1, 1, 0, 1]
# Para calcular a precisão, basta chamar a função "precision_score" passando os rótulos verdadeiros e previstos como argumentos:
precision = precision_score(y_true, y_pred)
# A precisão será um valor entre 0 e 1:
print(precision)
No caso, as arrays y_true e y_pred devem vir de seus dados e seu modelo.
y_true deve ter os alvos (ou rótulos) verdadeiros para cada exemplo previsto e y_pred deve ter as previsões de seu modelo no formato da classe atribuída.
No exemplo acima temos apenas as classes 0 e 1.
Uma dica: em todas as funções de métricas de avaliação no scikit-learn, os valores reais do alvo (y_true) são o primeiro argumento e as previsões (y_pred) são o segundo.
Como Calcular Precisão Em R
Se você estiver usando a linguagem R, a ideia é similar, mudando apenas a sintaxe e a biblioteca utilizada.
Neste caso vamos usar a biblioteca caret.
library(caret)
# Suponha que você tenha os seguintes rótulos verdadeiros e previstos pelo modelo (em formato numérico):
y_true <- c(0, 1, 1, 0, 1, 0, 1, 0, 0, 1)
y_pred <- c(0, 0, 1, 0, 1, 0, 1, 1, 0, 1)
# Para converter os rótulos em fatores, basta utilizar a função "as.factor":
y_true <- as.factor(y_true)
y_pred <- as.factor(y_pred)
# Agora você pode calcular a precisão utilizando a função "precision":
precision <- caret::precision(y_true, y_pred)
# A precisão será um valor entre 0 e 1:
print(precision)
Preste atenção se suas variáveis y_true e y_pred são do tipo “factor” ou você receberá um erro desta função.
O Que É Recall?
Continuando nosso exemplo de um modelo de machine learning que tenta prever se uma pessoa tem ou não uma doença rara:
O recall é o número de pessoas que o modelo identificou corretamente como tendo a doença dividido pelo número total de pessoas que realmente têm a doença nos seus dados.
Ou seja, de todas as pessoas que ele poderia classificar como positivas, quantas ele acertou.
Por isso esta métrica também é conhecida como taxa de detecção: de todos os exemplos que o modelo poderia detectar, quantos ele realmente conseguiu.
No nosso exemplo numérico: se tínhamos 100 pessoas com a doença nos dados de avaliação e modelo identificou 60 delas corretamente, o recall é 60/100 = 60%.
Qual A Fórmula Do Recall Na Matriz De Confusão?
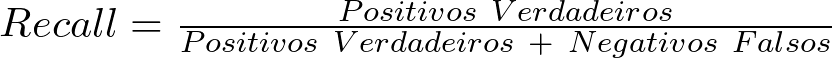
Em termos técnicos da matriz de confusão, o recall é a razão entre o número de verdadeiros positivos e o número total de casos positivos.
Você pode extrair estes elementos da linha referente à classe desejada na matriz de confusão (indicada pelas células azuis no diagrama abaixo).
Como Calcular Recall Com Scikit-learn Em Python
Veja abaixo como usar o scikit-learn para calcular facilmente o recall de seu modelo.
Ela segue o mesmo padrão das funções de métricas de avaliação do scikit-learn: rótulos verdadeiros (y_true) no primeiro argumento e previsões (y_pred) no segundo.
from sklearn.metrics import recall_score
# Suponha que você tenha os seguintes rótulos verdadeiros e previstos pelo modelo:
y_true = [0, 1, 1, 0, 1, 0, 1, 0, 0, 1]
y_pred = [0, 0, 1, 0, 1, 0, 1, 1, 0, 1]
# Para calcular o recall, basta chamar a função "recall_score" passando os rótulos verdadeiros e previstos como argumentos:
recall = recall_score(y_true, y_pred)
# O recall será um valor entre 0 e 1:
print(recall)
Como Calcular Recall Em R
Para calcular o recall na linguagem R vamos utilizar novamente a biblioteca caret.
library(caret)
# Suponha que você tenha os seguintes rótulos verdadeiros e previstos pelo modelo (em formato numérico):
y_true <- c(0, 1, 1, 0, 1, 0, 1, 0, 0, 1)
y_pred <- c(0, 0, 1, 0, 1, 0, 1, 1, 0, 1)
# Para converter os rótulos em fatores, basta utilizar a função "as.factor":
y_true <- as.factor(y_true)
y_pred <- as.factor(y_pred)
# Agora você pode calcular o recall utilizando a função "recall":
recall <- caret::recall(y_true, y_pred)
# O recall será um valor entre 0 e 1:
print(recall)
O Que É F1 Score?
Agora que você já sabe a diferença entre precisão e recall, o que você deve fazer se tanto precisão quanto recall forem igualmente importantes para o problema que você quer resolver?
Neste caso, você pode usar o F1 Score.
Ele é a média harmônica entre a precisão e o recall.
Qual A Fórmula Do F1 Score?
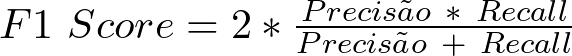
É uma fórmula bastante simples que inclui as duas métricas explicadas acima com a mesma importância: precisão e recall.
Por Que O F1 Score Usa A Média Harmônica?
A média harmônica é usada porque ela dá mais importância a valores baixos.
Isso faz sentido neste contexto, pois um valor muito mais baixo de precisão ou recall indica que o modelo não está equilibrando bem essas duas métricas, quando queremos dar importância igual às duas.
Voltando ao nosso exemplo de classificação binária, suponha que o modelo tem uma precisão de 0,9 (90%) e um recall de 0,1 (10%).
Se o F1 score utilizasse a média aritmética teríamos:
F1 Score = (0,9 + 0,1) / 2 = 0,5
Isso indica que o modelo tem um desempenho mediano tanto no acerto quanto na detecção de casos positivos.
No entanto, essa conclusão é enganosa, já que o modelo está com muito mais dificuldades em detectar os exemplos positivos (recall) do que acertá-los (precisão).
Agora, calculando o F1 score corretamente, com a média harmônica:
F1 Score = 2 * (0,9 * 0,1) / (0,9 + 0,1) = 0,18
Ele reflete melhor o fato de que o modelo tem uma precisão alta mas um recall baixo, o que pode ser um problema quando não queremos sacrificar uma métrica pela outra.
Como Calcular F1 Score Com Scikit-learn Em Python
Calcular o F1 score usando scikit-learn é tão simples quanto usar as funções de precisão e recall.
from sklearn.metrics import f1_score
y_true = [0, 1, 1, 0, 1, 0, 1, 0, 0, 1]
y_pred = [0, 0, 1, 0, 1, 0, 1, 1, 0, 1]
# Calcular o F1 score para as previsões do modelo
f1 = f1_score(y_true, y_pred)
# Exibir
print(f1)
Novamente, y_true é uma lista ou array com os rótulos verdadeiros das classes para cada exemplo da base de dados e y_pred é uma lista ou array com as previsões do modelo para os mesmos exemplos.
Como Calcular F1 Score em R
Para calcular o F1 score na linguagem R, vamos utilizar novamente a biblioteca caret.
library(caret)
# Vetores de rótulos verdadeiros e previsões
y_true = c(0, 1, 0, 1, 0, 1)
y_pred = c(0, 0, 0, 1, 0, 1)
# Converter vetores para fatores
y_true = as.factor(y_true)
y_pred = as.factor(y_pred)
# Calcular a pontuação F1 para as previsões do modelo
confusion_matrix <- confusionMatrix(y_pred,y_true, mode="everything", positive="1")
# Exibir a pontuação F1
print(confusion_matrix)
Essa função retornará várias métricas, incluindo precisão, recall e acurácia.
Basta verificar o valor do F1 score na lista de resultados.