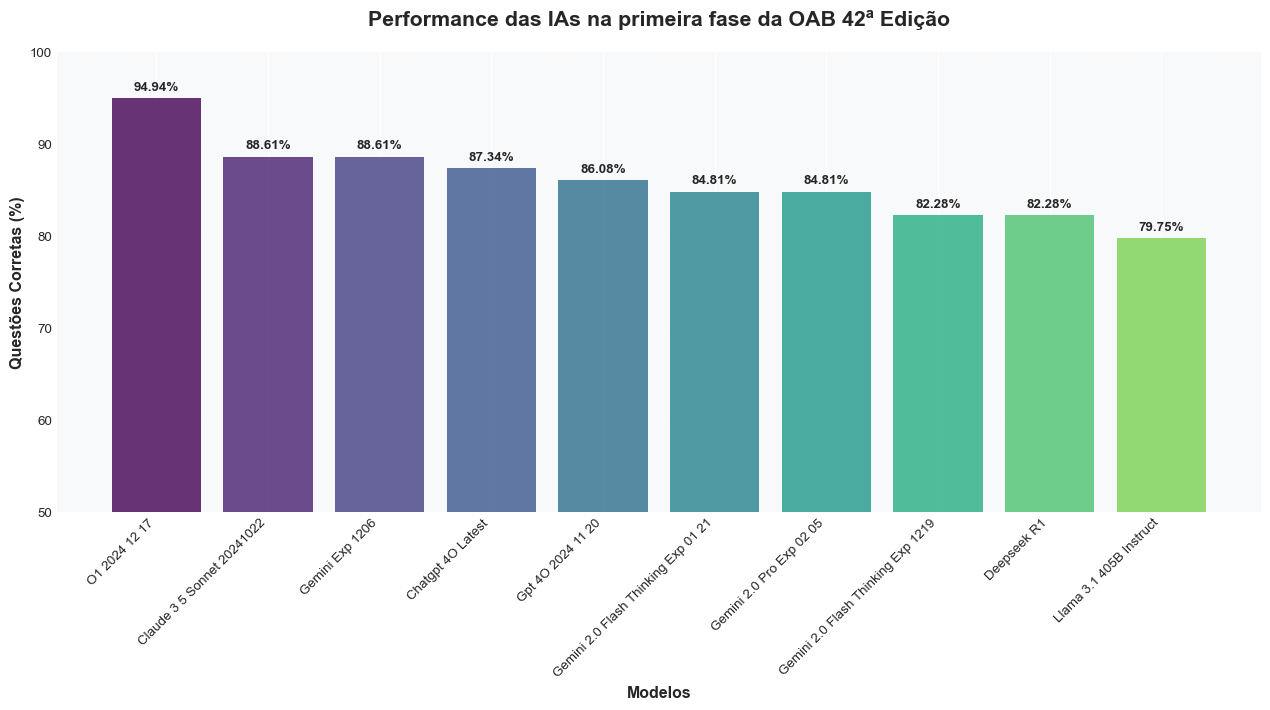
Can you read this page? This page was written in a Portuguese parish in 1693. It holds three baptism records in running cursive, densely abbreviated. The first child was baptized “aos 30 de agosto de 1693 annos” — on August 30, 1693. The second, “aos 2 de 7.bro” — 7bre being the period abbreviation for September. The third entry records only one parent, and the ink has faded to the edge of legibility....