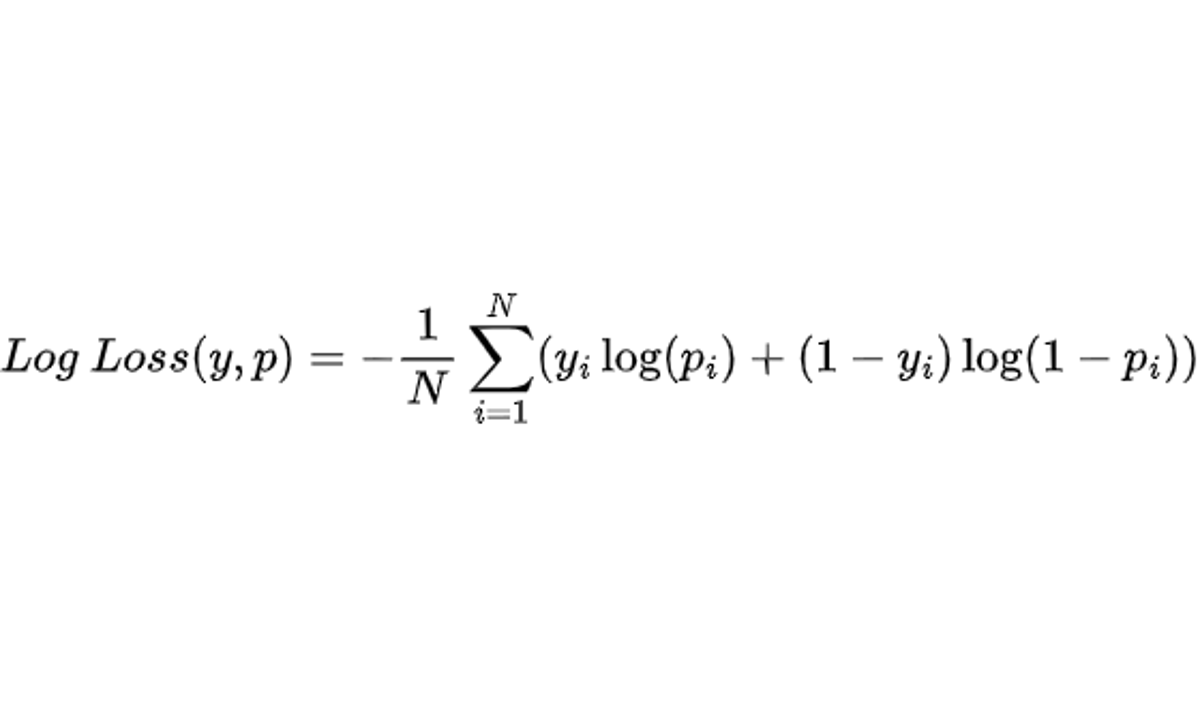
Índice
- O Que é Log Loss (Perda Logarítmica) e Como Interpretá-la?
- Qual a Fórmula da Log Loss?
- Log Loss Durante o Treino vs Validação
- Como Calcular Log Loss Usando Scikit-learn em Python
- Como Calcular Log Loss Em R
- Diferenças Entre Log Loss e ROC AUC
O Que é Log Loss (Perda Logarítmica) e Como Interpretá-la?
Log loss (ou perda logarítmica) é uma métrica de avaliação de modelos de classificação em machine learning, tanto binários quanto multiclasse.
Ela brilha em casos em que é importante que as probabilidades emitidas pelo modelo estejam alinhadas com a proporção real de ocorrências do alvo.
Para ficar mais claro, imagine que você esteja criando um modelo para prever se vai chover ou não em um determinado dia.
O modelo faz uma previsão em forma de probabilidade, ou seja, ele diz que há uma determinada porcentagem de chance de chover no dia.
Otimizando a log loss, você estará otimizando o modelo para que as previsões se aproximem da porcentagem real de dias chuvosos.
Por exemplo, se você pegar 100 dias em que o modelo disse que havia 30% de chance de chuva, em aproximadamente 30 deles terá chovido.
Isso é o que chamamos de modelo calibrado: as probabilidades previstas se aproximam das probabilidades reais dos eventos acontecerem.
Ela é uma métrica negativa, ou seja, quanto menor, melhor. Ela varia entre 0 (previsões perfeitas) e ∞ (previsões completamente erradas).
Lembrando que, se seu modelo faz previsões perfeitas nos dados de validação, provavelmente tem algo errado na forma como você está avaliando os resultados.😉
Qual a Fórmula da Log Loss?
Classificação Binária
A fórmula da log loss para casos de classificação binária é a seguinte:
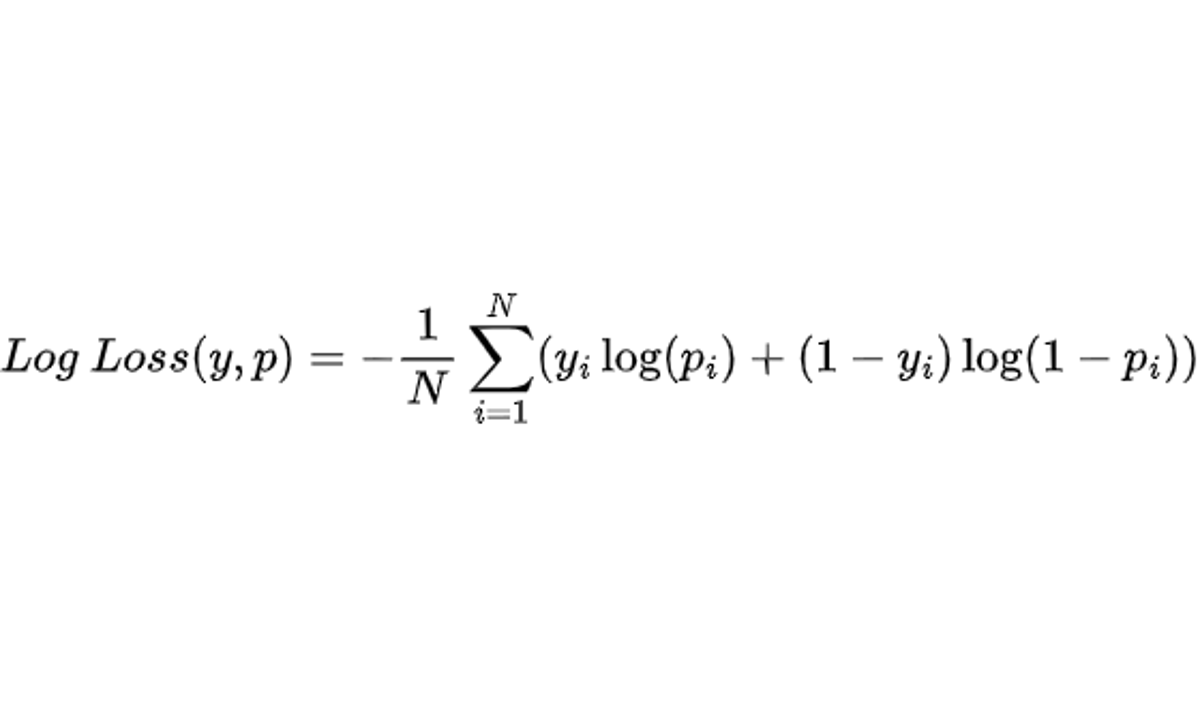
onde:
- n é o número de amostras
- y é a classe real (0 ou 1)
- p é a probabilidade prevista pelo modelo (entre 0 e 1)
Primeiro você calcula o valor da log loss para cada exemplo, depois você faz a média de todos os exemplos nos quais você está avaliando o modelo e por fim multiplica por -1 para ter um número positivo que você possa minimizar.
Note que a penalidade para previsões erradas não é linear, mas cresce exponencialmente quanto mais confiante o modelo está numa previsão errada.
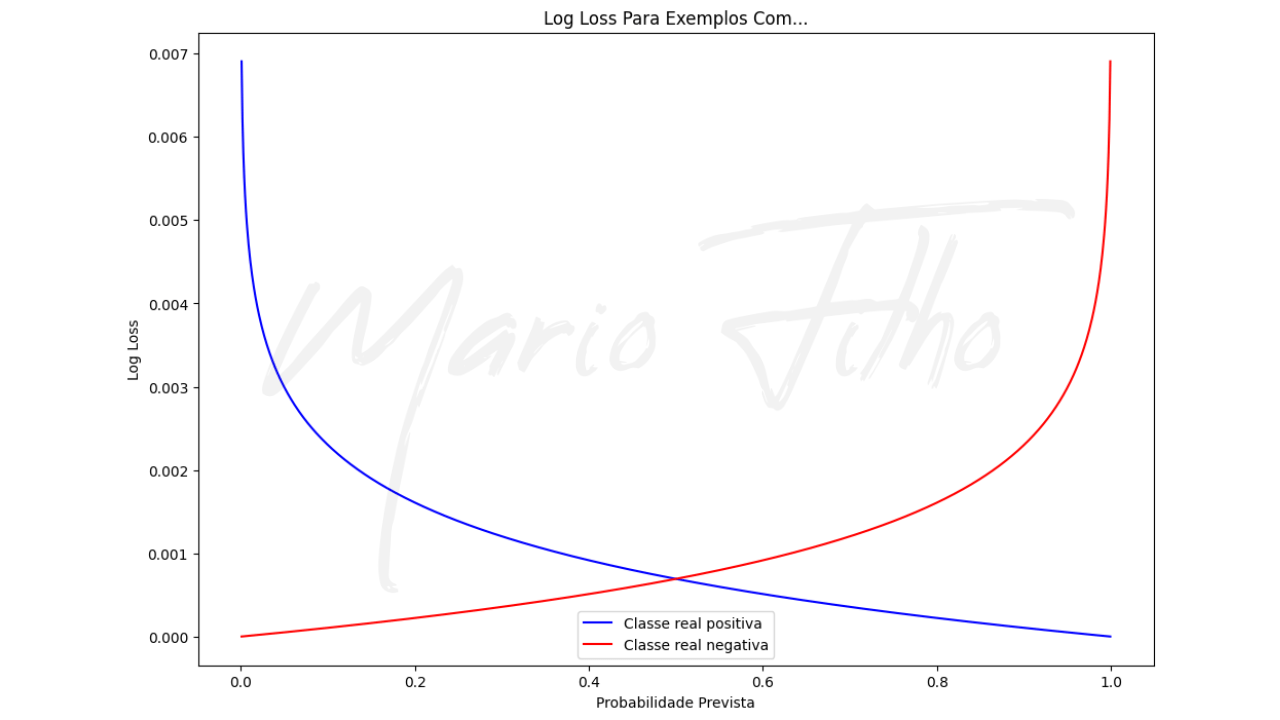
Se a classe real for positiva e a probabilidade prevista estiver próxima de zero, a penalização será enorme para puxar essa previsão para longe de zero.
Se a classe real for negativa e a probabilidade prevista estiver próxima de um, a penalização também será enorme para puxar essa previsão na direção do zero.
Classificação Multiclasse
É muito fácil expandi-la para casos em que você tem mais de duas classes.
Não importa quantas classes você tenha, considere apenas a probabilidade prevista pelo modelo para a classe real de cada exemplo.
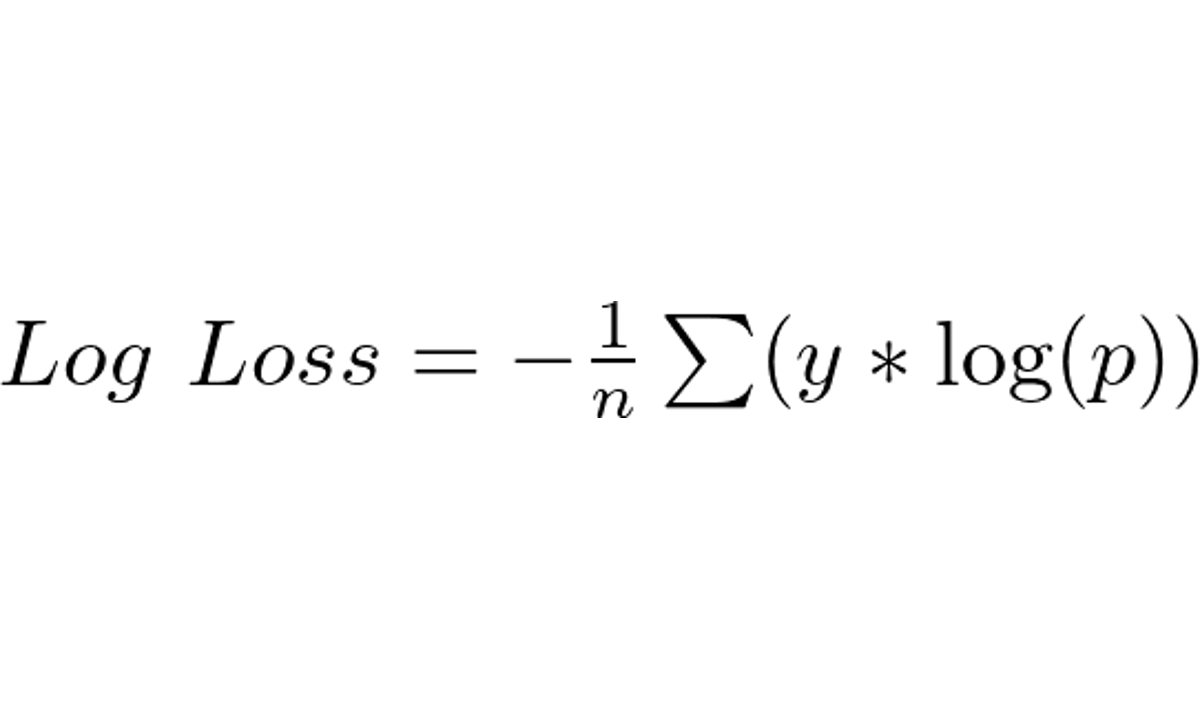
Onde:
- n é o número de amostras
- y é igual a 1 para a classe real e 0 para as outras (ou seja, podemos ignorar as probabilidades delas)
- p é a probabilidade prevista pelo modelo para a classe real da amostra
Na prática, isso significa que basta calcular o logaritmo da probabilidade prevista para a classe real para cada amostra.
Em seguida, você deve somar todos os valores obtidos e dividir pela quantidade de amostras.
Log Loss Durante o Treino vs Validação
A Log loss, diferente de outras métricas como acurácia e ROC AUC, pode ser usada tanto para otimizar o modelo durante o treino quanto para selecionar hiperparâmetros na validação.
Ela é a métrica padrão para otimizar modelos de classificação nas bibliotecas mais populares como o scikit-learn.
Durante o treino, a log loss geralmente é usada com gradiente descendente para ajustar os parâmetros internos do modelo.
Na validação, ela é usada para avaliar o desempenho do modelo treinado e selecionar os melhores hiperparâmetros.
Ou seja, você pode usá-la tanto diretamente na otimização do modelo sobre os dados de treino quanto na avaliação do modelo de treino em dados fora da amostra inicial.
Como Calcular Log Loss Usando Scikit-learn em Python?
Para calcular a log loss usando o scikit-learn em Python, você pode usar a função log_loss do módulo metrics.
Como é padrão do scikit-learn, ela recebe dois argumentos: o primeiro são os rótulos verdadeiros (y_true) e o segundo são as probabilidades previstas pelo modelo (y_pred).
from sklearn.metrics import log_loss
# Rótulos verdadeiros
y_true = [1, 0, 1, 1, 0]
# Probabilidades previstas pelo modelo
y_pred = [[0.9, 0.1], [0.8, 0.2], [0.3, 0.7], [0.1, 0.9], [0.7, 0.3]]
# Calcula a log loss
loss = log_loss(y_true, y_pred)
print(loss) # Imprime a log loss
Apesar do y_pred do exemplo ter as probabilidades para as duas classes, no caso de classificação binária você pode passar apenas a probabilidade da classe positiva que a função toma conta de fazer a subtração e calcular a probabilidade da classe negativa.
Expandir para mais de duas classes é trivial:
from sklearn.metrics import log_loss
# Rótulos verdadeiros
y_true = [2, 0, 1, 1, 2]
# Probabilidades previstas pelo modelo
y_pred = [[0.1, 0.3, 0.6], [0.8, 0.1, 0.1], [0.1, 0.8, 0.1], [0.1, 0.7, 0.2], [0.8, 0.1, 0.1]]
# Calcula a log loss
loss = log_loss(y_true, y_pred)
print(loss) # Imprime a log loss
Neste exemplo, temos três classes (0, 1 e 2), então cada amostra tem três probabilidades previstas pelo modelo.
Como Calcular Log Loss Em R?
Em R, você pode usar a função LogLoss do pacote MLmetrics.
Assim como o scikit-learn, ela recebe dois argumentos: os rótulos verdadeiros (y_true) e as probabilidades previstas pelo modelo (y_pred).
Mas preste atenção porque o y_pred é o primeiro argumento neste caso.
Para classificação binária, passamos apenas as probabilidades da classe positiva:
library(MLmetrics)
# Rótulos verdadeiros
y_true = c(1, 0, 1, 1, 0)
# Probabilidades previstas pelo modelo
y_pred = c(0.1, 0.2, 0.7, 0.9, 0.3)
# Calcula a log loss
loss = LogLoss(y_pred, y_true)
print(loss) # Imprime a log loss
Para calcular a log loss num caso multiclasse, use a função MultiLogLoss:
library(MLmetrics)
# Rótulos verdadeiros (vetor numérico)
y_true = c(2, 0, 1, 1, 2)
# Probabilidades previstas pelo modelo
y_pred = matrix(c(0.1, 0.8, 0.1, 0.1, 0.8, 0.3, 0.1, 0.8, 0.7, 0.1, 0.6, 0.1, 0.1, 0.2, 0.1), nrow = 5, ncol = 3)
# Calcula a log loss
loss = MultiLogLoss(y_pred, y_true)
print(loss) # Imprime a log loss
Diferenças Entre Log Loss e ROC AUC
A ROC AUC é uma métrica mais adequada do que a log loss quando você se importa mais com a capacidade do modelo ranquear exemplos positivos acima dos negativos do que com a probabilidade específica atribuída a cada exemplo.
Imagine que você esteja criando um sistema de recomendação de filmes para uma plataforma de streaming.
Seu alvo é separar os filmes entre os que usuário vai assistir até o fim (classe positiva) e filmes que o usuário não vai assistir ou deixará pela metade (classe negativa).
Mesmo que a probabilidade de um filme ser assistido até o fim seja pequena, você se importa mais com a capacidade do modelo de ranquear os filmes que o usuário provavelmente assistirá até o fim acima dos filmes que ele provavelmente não assistirá ou deixará pela metade, do que com a probabilidade específica atribuída a cada filme.
Assim você pode mostrar uma lista de filmes otimizada na próxima vez que o usuário acessar o serviço.
No mundo ideal, a log loss faria o ranqueamento perfeito ao otimizar a probabilidade real de cada exemplo mas, na prática, isso não acontece.
Neste caso, a ROC AUC é uma métrica mais adequada do que a log loss.
Diferente da log loss, a ROC AUC é uma métrica que varia de 0,5 a 1 e quanto maior o valor, melhor.
A ROC AUC é menos sensível às diferenças em probabilidades muito pequenas e é menos afetada pelo desbalanceamento de classes do que a log loss.
Isso é crucial em problemas de ranqueamento, como o problema de recomendação de filmes descrito no texto.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.