Índice
- O Que é LSTM (Long Short-Term Memory)?
- Como Funciona a LSTM?
- Quando Usar a LSTM?
- Como Instalar a NeuralForecast Com e Sem Suporte a GPU
- Como Preparar os Dados Para a LSTM
- Modelagem Automática com AutoLSTM
- Código de Treinamento da LSTM em Python
- LSTM com Variáveis Adicionais
- Baseline Simples Com Sazonalidade
- Loss Function Personalizada com PyTorch (WMAPE)
O Que é LSTM (Long Short-Term Memory)?
LSTM é um tipo de rede neural recorrente (RNN).
Ela é capaz de manter um vetor interno de informações (o “estado”) por períodos de tempo mais longos que as redes neurais recorrentes primitivas.
Montar as estruturas dessas redes neurais do zero é muito trabalhoso, mas temos bibliotecas que nos ajudam fazendo a maior parte do trabalho.
Vamos usar a biblioteca NeuralForecast, que além de implementar as estruturas mais comuns de redes neurais recorrentes, também implementa a busca automática por hiperparâmetros.
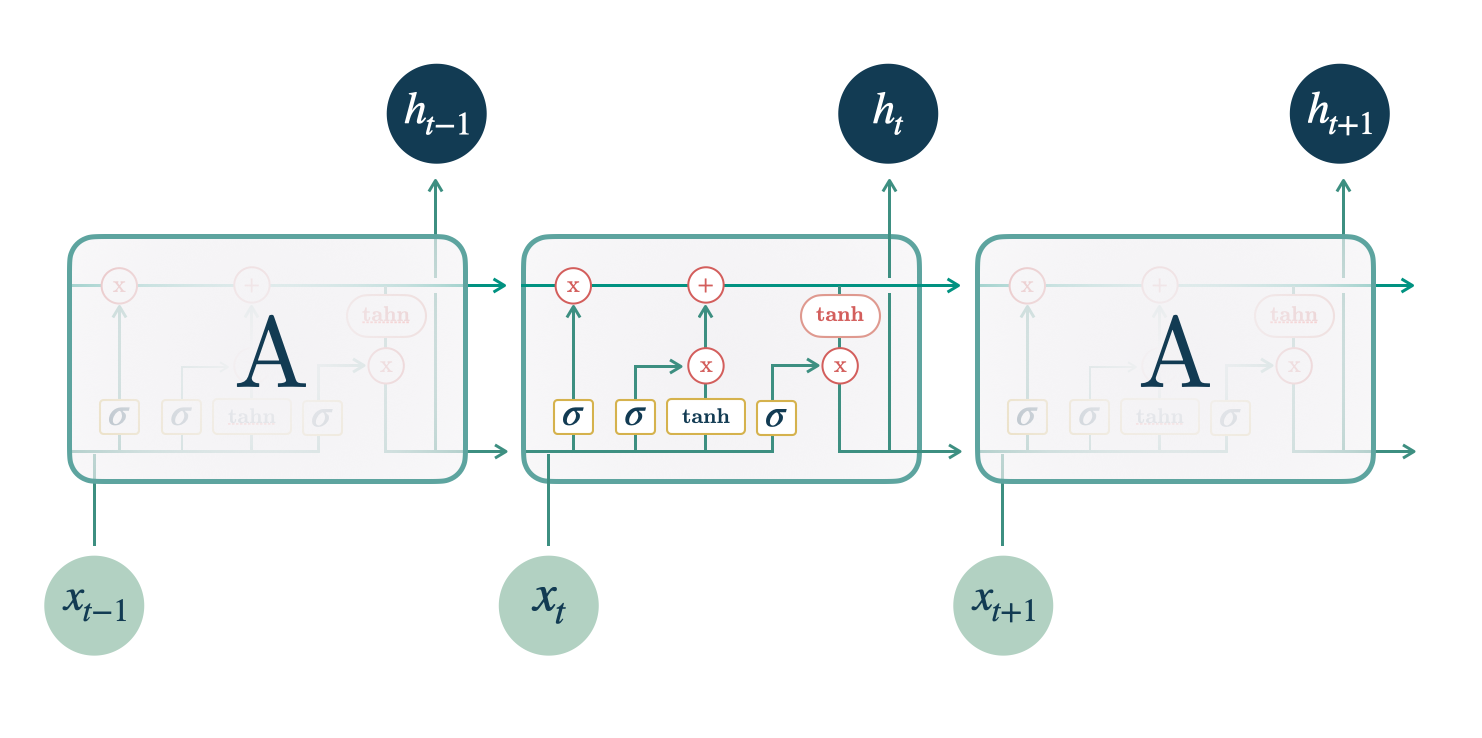
Como Funciona a LSTM?
A LSTM vai processar um passo da sequência de dados de cada vez, ou seja, uma observação da série temporal de cada vez.
 créditos: https://nixtla.github.io/neuralforecast/models.lstm.html
créditos: https://nixtla.github.io/neuralforecast/models.lstm.html
Apesar disso, ela mantém um estado interno que contém informações sobre os passos que ela já processou.
Esse estado interno, que pode ser pensado como a memória da LSTM, é uma matriz.
Os dados de entrada são tanto as observações da série temporal quanto uma representação interna (oculta) do processamento das observações anteriores.
Essa representação é diferente do estado interno.
Temos então 3 elementos principais: o estado interno, a representação oculta e as observações da série temporal.
O estado interno e a representação oculta são zerados no primeiro passo da sequência.
A primeira etapa da LSTM ao receber dados de uma sequência é decidir quais informações serão descartadas do estado interno atual.
Ela usa um “portão de esquecimento” para decidir isso.
Este portão é uma multiplicação dos dados de entrada com uma matriz, transformados por uma função sigmóide.
A segunda etapa é a atualização do estado interno da LSTM com novas informações.
Ela usa um “portão de entrada”, similar ao portão de esquecimento, para definir quais informações serão adicionadas ao estado interno.
A terceira etapa é combinar as informações do estado interno atual com as novas informações para criar um novo estado interno.
Na quarta etapa, a LSTM usa um “portão de saída” para criar a representação oculta a ser passada ao próximo passo baseada no estado interno atual.
Então tudo começa novamente usando essa representação oculta, o estado interno atualizado e uma nova observação da série temporal.
Quando Usar a LSTM?
A LSTM é muito útil na previsão de dados sequenciais, como séries temporais.
Um exemplo fora de séries temporais é no processamento de linguagem natural, pois podemos pensar em texto como uma sequência de palavras e processá-lo usando uma LSTM.
Outro exemplo é o processamento de vídeos, já que um vídeo é apenas uma sequência de imagens.
Então, se você tem dados que podem ser pensados como uma sequência, vale a pena testar uma LSTM para modelá-los.
Como Instalar a NeuralForecast Com e Sem Suporte a GPU
Por usar métodos de redes neurais, se você tiver uma GPU, é importante ter o CUDA instalado para que os modelos rodem mais rápido.
Para verificar se você tem uma GPU instalada e configurada corretamente com PyTorch (backend da biblioteca), execute o código abaixo:
import torch
print(torch.cuda.is_available())
Esta função retorna True se você tem uma GPU instalada e configurada corretamente, e False caso contrário.
Caso você tenha uma GPU, mas não tenha o PyTorch instalado com suporte a ela, veja no site oficial do PyTorch como instalar a versão correta.
Recomendo que você instale o PyTorch primeiro!
O comando que usei para instalar o PyTorch com suporte a GPU foi:
conda install pytorch pytorch-cuda=11.7 -c pytorch -c nvidia
Se você não tem uma GPU, não se preocupe, a biblioteca funciona normalmente, só não fica tão rápida.
Instalar essa biblioteca é muito simples, basta executar o comando abaixo:
pip install neuralforecast statsforecast matplotlib "ray[tune]"
ou se você usa o Anaconda:
conda install -c conda-forge neuralforecast statsforecast matplotlib "ray-tune"
Para reproduzir todos os blocos deste artigo, você também vai precisar do statsforecast para a baseline simples, do matplotlib para os gráficos e do ray-tune para a busca automática do AutoLSTM.
Se você estiver reproduzindo este exemplo hoje, prefira criar um ambiente com Python 3.9 a 3.12. Algumas versões mais novas do Python ainda podem não ter wheels disponíveis para todas as dependências usadas pela busca automática.
Como Preparar os Dados Para a LSTM
Vamos usar dados reais de vendas da rede de lojas Favorita, do Equador.
Temos dados de vendas de 2013 a 2017 para diversas lojas e categorias de produtos.
Nossos dados de treino cobrirão o ano todo de 2013, os dados de validação serão os 3 primeiros meses de 2014.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def wmape(y_true, y_pred):
return np.abs(y_true - y_pred).sum() / np.abs(y_true).sum()
Para medir o desempenho do modelo, vamos usar a métrica WMAPE (Weighted Mean Absolute Percentage Error).
Ela é uma adaptação do erro percentual que resolve o problema de dividir por zero.
data = pd.read_csv('train.csv', index_col='id', parse_dates=['date'])
data2 = data.loc[(data['store_nbr'] == 1) & (data['family'].isin(['MEATS', 'PERSONAL CARE'])), ['date', 'family', 'sales', 'onpromotion']]
Para simplificar, vamos usar apenas os dados de uma loja e duas categorias de produto.
As colunas são:
date: data do registrofamily: categoria do produtosales: número de vendasonpromotion: a quantidade de produtos daquela categoria que estavam em promoção naquele dia
oil = pd.read_csv('oil.csv', index_col='date', parse_dates=['date'])
data2 = data2.merge(oil, how='left', left_on='date', right_index=True).fillna(0.0)
weekday = pd.get_dummies(data2['date'].dt.weekday)
weekday.columns = ['weekday_' + str(i) for i in range(weekday.shape[1])]
data2 = pd.concat([data2, weekday], axis=1)
Além das vendas, vamos criar variáveis adicionais do dia da semana e do preço do barril de petróleo.
O dia da semana pode ser tratado como uma variável ordinal ou categórica, mas aqui vou usar a abordagem categórica que é mais comum.
Em geral, usar informações adicionais que sejam relevantes para o problema pode melhorar o desempenho do modelo.
O Equador é um país que depende muito do petróleo (40% das exportações), por isso esses dados foram fornecidos durante a competição original da Corporación Favorita no Kaggle.
O barril do petróleo mais caro pode indicar mais dinheiro entrando no país, o que afetaria as vendas.
Variáveis específicas da estrutura temporal, como dias da semana, meses, dias do mês são importantes para capturar padrões sazonais.
Existe uma infinidade de outras informações que poderíamos adicionar, como a temperatura, chuva, feriados, etc.
data2 = data2.rename(columns={'date': 'ds', 'sales': 'y', 'family': 'unique_id'})
A biblioteca neuralforecast espera que as colunas sejam nomeadas dessa forma:
ds: data do registroy: variável alvo (número de vendas)unique_id: identificador único da série temporal (categoria do produto)
O unique_id pode ser qualquer identificador que separe suas séries temporais.
Se quiséssemos modelar a previsão de vendas de todas as lojas, poderíamos usar o store_nbr junto com a family como identificadores.
train = data2.loc[data2['ds'] < '2014-01-01']
valid = data2.loc[(data2['ds'] >= '2014-01-01') & (data2['ds'] < '2014-04-01')]
h = valid['ds'].nunique()
Este é o formato final da tabela:
| ds | unique_id | y | onpromotion | dcoilwtico | weekday_0 | weekday_1 | weekday_2 | weekday_3 | weekday_4 | weekday_5 | weekday_6 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2013-01-01 00:00:00 | MEATS | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2013-01-01 00:00:00 | PERSONAL CARE | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2013-01-02 00:00:00 | MEATS | 369.101 | 0 | 93.14 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
Separamos os dados em treino e validação com uma divisão temporal simples entre passado e futuro.
A variável h é o horizonte, o número de períodos que queremos prever no futuro.
Neste caso, é o número de datas únicas na validação (90).
Vamos para a modelagem.
Modelagem Automática com AutoLSTM
A forma mais simples e rápida de criar uma LSTM é usando a classe AutoLSTM.
Ela empacota tanto a arquitetura da rede quanto a busca por hiperparâmetros.
Neste primeiro experimento, vou configurá-la sem variáveis adicionais para manter a comparação inicial estritamente univariada.
Nas versões atuais da biblioteca, a AutoLSTM também pode receber variáveis adicionais via config, assim como a LSTM manual.
Também vou deixar o scaling dos dados para a etapa seguinte, para separar melhor o efeito dos hiperparâmetros do efeito das variáveis exógenas e do pré-processamento.
Com isso, primeiro usamos a AutoLSTM para achar bons hiperparâmetros em um cenário mais simples e depois reaproveitamos esse aprendizado em modelos mais ricos.
Na prática você pode usar AutoLSTM direto para otimizar com as variáveis exógenas: apenas farei assim aqui para efeitos didáticos.
Arquitetura da LSTM
A arquitetura da rede usa um encoder (codificador) e um decoder (decodificador), uma arquitetura de muito sucesso em várias aplicações.
O encoder aprenderá a transformar a sequência de entrada em uma representação compacta adequada para o alvo que queremos prever.
A tarefa do encoder pode ser vista como a extração das features mais importantes da série temporal.
O decoder receberá essas features (representação do encoder) e fará a previsão das observações futuras.
O encoder é uma LSTM e o decoder é uma rede neural feedforward (MLP).
Busca Automática por Hiperparâmetros
A busca por hiperparâmetros é feita usando o ray-tune, que é uma biblioteca de busca por hiperparâmetros da Ray.
Ela possui várias estratégias como busca aleatória (random search), busca por grade (grid search), otimização bayesiana (bayesian optimization), etc.
Você pode especificar a estratégia desejada usando o parâmetro search_alg.
Por padrão a busca é aleatória, mas você pode instalar bibliotecas extras para usar otimização bayesiana, que é a minha favorita.
A busca aleatória já será suficiente para achar bons hiperparâmetros.
Você pode modificar os intervalos de hiperparâmetros sugeridos, mas eu recomendo que você use os valores padrões, principalmente se você não tem muita experiência com redes neurais.
input_size
Controla o tamanho da sequência de entrada da rede.
Neste artigo eu vou testar janelas de 30, 60, 90, 120, 180 e 270 dias.
Quanto maior o input_size, mais histórico a rede consegue observar antes de prever o futuro.
Valores muito grandes aumentam o custo de treinamento e podem desperdiçar capacidade do modelo em padrões antigos que já não ajudam tanto.
encoder_hidden_size
Controla o número de unidades (neurônios) da representação interna (oculta) do encoder (codificador), que pode ser 50, 100, 200 ou 300.
Quanto maior, mais capacidade de aprender padrões complexos, mas também mais chances de overfitting.
encoder_n_layers
Controla o número de camadas no encoder. É um número inteiro entre 1 e 4.
Assim como o tamanho da representação interna, quanto maior o número de camadas, mais capacidade de aprender padrões complexos, mas também mais chances de overfitting.
As camadas especificadas terão todas o mesmo tamanho, dado pelo parâmetro encoder_hidden_size.
decoder_hidden_size
Controla o número de unidades (neurônios) das representações internas do decoder (decodificador), que pode ser 64, 128, 256 ou 512.
O decoder é uma rede neural comum feed-forward (MLP) com duas camadas de representação internas (hidden layers).
learning_rate
Um dos hiperparâmetros mais importantes de qualquer rede neural.
Controla o tamanho do passo que o algoritmo de otimização dará para atualizar os pesos da rede.
Se for muito grande, o algoritmo pode divergir e nunca achar uma solução boa. Se for muito pequeno, o algoritmo pode demorar muito para convergir.
É um número aleatório gerado a partir de uma distribuição log-uniforme entre 1e-4 e 1e-1.
max_steps
Controla o número máximo de passos de treinamento, que pode ser 500 ou 1000.
Este parâmetro determina quantas vezes o algoritmo de otimização irá atualizar os pesos da rede.
Quanto menor a learning_rate, mais passos serão necessários para convergir.
Soluções com muitos passos e uma learning_rate baixa demoram para treinar, mas tendem a ter maior estabilidade e desempenho.
batch_size
Controla o número de exemplos que serão considerados para calcular o gradiente na hora de atualizar os pesos da rede.
Pode ser 16 ou 32.
Quanto mais memória tiver sua GPU, maior pode ser o batch size. Quanto maior o batch size, mais estável é a estimativa do gradiente.
random_seed
Controla a semente aleatória que é usada para inicializar os pesos da rede, que pode ser um número inteiro entre 1 e 20.
Eu acho engraçado que a random_seed esteja no meio dos hiperparâmetros, mas acredito que seja apenas uma maneira de garantir que a busca retorne um modelo reprodutível.
Os pesos iniciais influenciam bastante o desempenho da rede, mas ajustar a random_seed em busca do “melhor valor” é igual ter números da sorte para jogar na loteria.
Código de Treinamento da LSTM em Python
from ray import tune
from neuralforecast import NeuralForecast
from neuralforecast.auto import AutoLSTM
search_config = {
'input_size': tune.choice([30, 60, 90, 120, 180, 270]),
'inference_input_size': -1,
'encoder_hidden_size': tune.choice([16, 32, 64, 128]),
'encoder_n_layers': tune.randint(1, 4),
'decoder_hidden_size': tune.choice([16, 32, 64, 128]),
'learning_rate': tune.loguniform(1e-4, 1e-1),
'max_steps': tune.choice([500, 1000]),
'batch_size': tune.choice([16, 32]),
'random_seed': tune.randint(1, 20),
}
models = [AutoLSTM(h=h,
config=search_config,
num_samples=30,
loss=WMAPE())]
model = NeuralForecast(models=models, freq='D')
Precisamos das classes NeuralForecast e AutoLSTM para treinar a rede.
A classe NeuralForecast é uma classe utilitária para facilitar a interação com os modelos de redes neurais.
A classe AutoLSTM é a classe que implementa a busca automática pelo modelo baseado em LSTM.
Primeiro criamos uma lista com os modelos que queremos treinar, nesse caso apenas a AutoLSTM.
A classe AutoLSTM possui muitos argumentos, mas vamos usar apenas os seguintes:
h: horizonte, número de passos no futuro que queremos preverconfig: espaço de busca dos hiperparâmetrosnum_samples: número de combinações de hiperparâmetros que a busca automática irá testarloss: função de perda que será usada para otimizar os pesos da rede
Por experiência, testar 30 combinações de hiparparâmetros já vai te dar um modelo bom com pouco risco de overfitting na validação.
Criei uma função loss personalizada para otimizar o WMAPE diretamente, mas você pode usar as funções disponíveis no PyTorch como MAE e MSE.
Neste caso eu também defini o config manualmente para fazer a busca testar janelas de entrada entre 30 e 270 dias.
No fim do artigo eu mostro a implementação dessa função personalizada.
Por fim passamos a lista de modelos para a classe NeuralForecast e definimos a frequência dos dados como D (diários).
model.fit(train, val_size=h)
p = model.predict().reset_index()
p = p.merge(valid[['ds','unique_id', 'y']], on=['ds', 'unique_id'], how='left')
print(wmape(p['y'], p['AutoLSTM']))
Usamos o método fit para treinar o modelo, passando como argumentos o conjunto de treinamento e o tamanho da validação interna da busca automática.
Esta é uma validação interna, separada dos dados que armazenamos na variável valid.
Como nosso horizonte é de 90 dias, usamos val_size=h para que a validação interna também tenha 90 dias. Nas versões mais novas da biblioteca, o val_size precisa ser 0 ou maior ou igual ao horizonte.
Antes de iniciar a busca, o NeuralForecast separa os últimos 90 dias do conjunto de treinamento para medir o desempenho do modelo fora dos dados usados para treinar e otimizar os hiperparâmetros com base nesse número, já que o modelo com menor loss nos dados de treino não necessariamente será o melhor modelo fora desta amostra.
Caso você não especifique os períodos no val_size, ele usará o tamanho do horizonte h.
Caso você receba o erro ModuleNotFoundError: No module named 'ray', instale o pacote ray-tune com o comando abaixo:
conda install "ray-tune" -c conda-forge
Há um argumento refit_with_val no objeto AutoLSTM que retreina o modelo com os melhores hiperparâmetros usando todos os dados disponíveis ao terminar a busca, mas eu não recomendo usá-lo fora de competições porque pode te dar um modelo com performance diferente do que você esperava.
O método predict retorna um DataFrame com as previsões para o horizonte h, as datas logo após o término dos dados de treinamento.
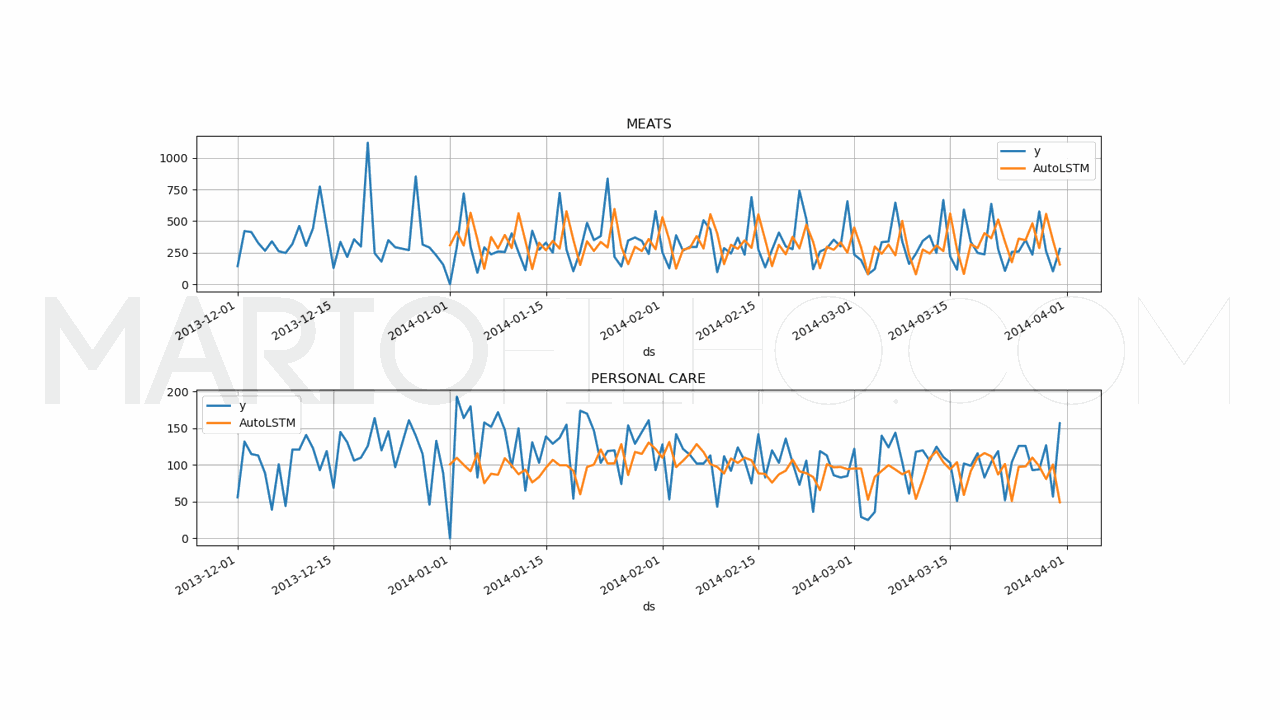
Para avaliar a performance do modelo, eu fiz o merge dos alvos com as previsões e calculei o WMAPE, que ficou em 51,62%.
| unique_id | ds | AutoLSTM | y |
|---|---|---|---|
| MEATS | 2014-01-01 00:00:00 | 299.982 | 0 |
| MEATS | 2014-01-02 00:00:00 | 360.606 | 298.455 |
| MEATS | 2014-01-03 00:00:00 | 387.701 | 718.094 |
Melhor do que ter apenas um número, vamos plotar as previsões para cada unique_id e ver se as previsões fazem sentido.
fig, ax = plt.subplots(2, 1, figsize = (1280/96, 720/96))
fig.tight_layout(pad=7.0)
for ax_i, unique_id in enumerate(['MEATS', 'PERSONAL CARE']):
plot_df = pd.concat([train.loc[train['unique_id'] == unique_id].tail(30),
p.loc[p['unique_id'] == unique_id]]).set_index('ds')
plot_df[['y', 'AutoLSTM']].plot(ax=ax[ax_i], linewidth=2, title=unique_id)
ax[ax_i].grid()
Análise dos Resultados da Busca Automática
Você pode acessar os resultados da busca automática com o atributo results do modelo ajustado.
Nas versões atuais da biblioteca, depois do fit, o AutoLSTM treinado fica dentro de model.models[0].
results_df = model.models[0].results.get_dataframe().sort_values('loss')
Ele retornará um DataFrame com os resultados de cada passo da busca, ordenados pelo loss (menor para maior).
Estas são as 5 melhores configurações encontradas:
| loss | config/input_size | config/encoder_n_layers | config/learning_rate | config/max_steps |
|---|---|---|---|---|
| 0.251536 | 30 | 1 | 0.00801247 | 1000 |
| 0.253291 | 120 | 2 | 0.000438376 | 500 |
| 0.253350 | 30 | 1 | 0.00510586 | 500 |
| 0.254070 | 30 | 3 | 0.00126524 | 1000 |
| 0.257002 | 180 | 1 | 0.000645069 | 1000 |
Isso é bom para você entender como cada hiperparâmetro afeta o desempenho do modelo.
Por exemplo, note como 3 das 5 melhores configurações usam input_size=30, o que sugere que neste conjunto janelas curtas de histórico funcionaram melhor do que janelas mais longas.
A tabela completa mostra todos os hiperparâmetros testados, mas aqui limitei a 5 colunas para facilitar a visualização.
Tendo um conjunto de hiperparâmetros que funcionam bem, você pode usar o modelo treinado ou usá-los para treinar um modelo com variáveis adicionais.
Essa é uma maneira de economizar tempo e recursos computacionais, já que você não precisa fazer novamente a busca do zero.
Se você quiser fazer a busca automática já com variáveis adicionais, nas versões atuais da biblioteca basta incluí-las no config:
search_config_with_exog = {
**search_config,
'scaler_type': 'robust',
'futr_exog_list': ['onpromotion', 'weekday_0',
'weekday_1', 'weekday_2', 'weekday_3', 'weekday_4',
'weekday_5', 'weekday_6', 'dcoilwtico'],
}
Neste artigo, vou seguir com a LSTM manual para deixar essa segunda etapa mais explícita e reaproveitar diretamente o best_config.
LSTM com Variáveis Adicionais
O objeto AutoLSTM também armazena os melhores hiperparâmetros encontrados na busca automática.
Para acessá-los, use o método get_best_result do atributo results.
best_config = model.models[0].results.get_best_result().metrics['config'].copy()
As chaves e valores exatos variam conforme a versão da biblioteca e a busca automática.
Como o espaço de busca já foi definido com input_size no máximo igual a 270, dá para reaproveitar esse dicionário diretamente em um LSTM treinado manualmente.
Se quiser visualizar só os hiperparâmetros principais, você pode imprimir um subconjunto do dicionário:
{key: best_config[key] for key in [
'h',
'input_size',
'encoder_hidden_size',
'encoder_n_layers',
'decoder_hidden_size',
'learning_rate',
'max_steps',
'batch_size',
'random_seed',
]}
Agora, vamos treinar um modelo com esses hiperparâmetros e as variáveis adicionais.
from neuralforecast import NeuralForecast
from neuralforecast.models import LSTM
models = [LSTM(scaler_type='robust',
futr_exog_list=['onpromotion', 'weekday_0',
'weekday_1', 'weekday_2', 'weekday_3', 'weekday_4', 'weekday_5',
'weekday_6', 'dcoilwtico'],
**best_config)]
model = NeuralForecast(models=models, freq='D')
model.fit(train)
valid['dcoilwtico'] = train['dcoilwtico'].iloc[-1]
p = model.predict(futr_df=valid).reset_index()
p = p.merge(valid[['ds','unique_id', 'y']], on=['ds', 'unique_id'], how='left')
fig, ax = plt.subplots(2, 1, figsize = (1280/96, 720/96))
fig.tight_layout(pad=7.0)
for ax_i, unique_id in enumerate(['MEATS', 'PERSONAL CARE']):
plot_df = pd.concat([train.loc[train['unique_id'] == unique_id].tail(30),
p.loc[p['unique_id'] == unique_id]]).set_index('ds') # Concatenate the train and forecast dataframes
plot_df[['y', 'LSTM']].plot(ax=ax[ax_i], linewidth=2, title=unique_id)
ax[ax_i].grid()
print(wmape(p['y'], p['LSTM']))
Existem poucas diferenças deste código para o código anterior.
Agora vamos usar o objeto LSTM ao invés do AutoLSTM.
Esta classe é usada internamente pelo AutoLSTM, mas neste caso não queremos fazer a busca automática e sim treinar um modelo diretamente.
Passamos o argumento scaler_type para que o objeto faça o scaling dos dados antes de treinar o modelo.
Em geral é um passo necessário para ajudar qualquer rede neural a convergir mais rápido e para uma solução melhor.
Existem dois scalers disponíveis: standard e robust. O primeiro usa a média e o desvio padrão enquanto o segundo usa a mediana e o desvio absoluto da mediana.
Teste ambos e também nenhum (None) e veja qual funciona melhor em seus dados específicos. Nestes dados o robust funcionou melhor.
Você também pode usar scalers externos como os disponíveis no scikit-learn ou fazer o seu próprio.
Além disso, passamos o argumento futr_exog_list para indicar os nomes das variáveis adicionais que queremos usar e os hiparâmetros otimizados armazenados no dicionário best_config.
Caso você queira adicionar variáveis externas estáticas (por exemplo, o código do produto), você pode usar o argumento stat_exog_list.
Desta vez o método fit recebe apenas o conjunto de treinamento, pois não vamos fazer a busca automática.
O método predict recebe o conjunto de validação contendo as variáveis adicionais com seus valores para as datas futuras.
No caso dos dias da semana isso é simples, mas e no caso do preço do petróleo?
Para usar essa variável na prática precisaríamos ter a estimativa dele para cada dia futuro, o que pode ser bem complicado.
Para deixar esse exemplo realista, vamos usar o último valor do conjunto de treinamento para preencher os valores futuros.
Afinal, não podemos usar os preços reais do futuro durante o desenvolvimento do modelo se não vamos ter a mesma informação em produção.
Caso você faça isso, seu modelo parecerá muito melhor do que realmente será em produção.
O resultado deste modelo foi um WMAPE de 32,80%, bem melhor do que a AutoLSTM do primeiro experimento, que foi configurada sem variáveis adicionais.
Aqui o ganho não vem só do modelo em si: ele também está usando variáveis exógenas e scaler_type='robust'.
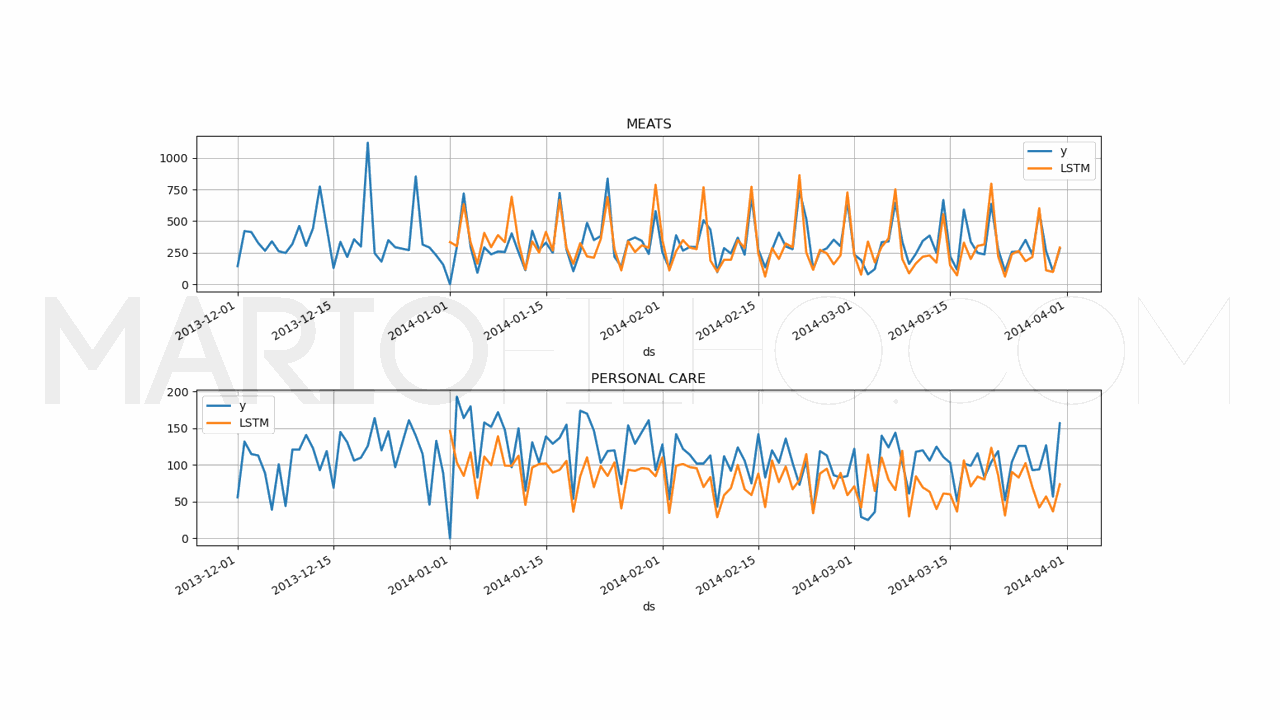
Perceba como os picos se alinham melhor aos dados históricos com essas variáveis sazonais.
Por curiosidade (e experiência), decidi rodar o modelo com as variáveis de dia da semana e promoção, mas sem o preço do petróleo, já que ele não varia nos dados de validação.
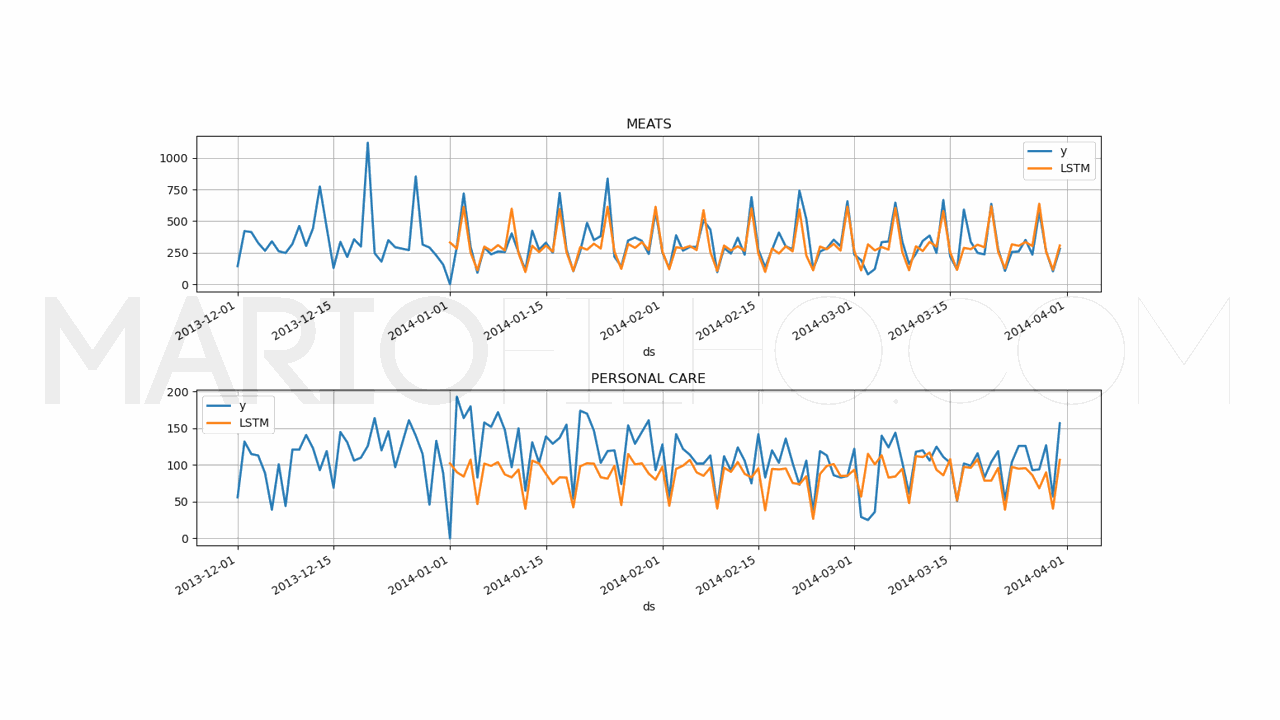
O resultado foi um WMAPE de 32,22%, ligeiramente melhor do que a versão com petróleo!
Isso serve de lição para que você não use variáveis adicionais sem testar o impacto real delas no modelo.
Outro teste que fica como lição de casa é rodar o modelo com a variável de dia da semana no formato ordinal ao invés de one-hot encoding.
Baseline Simples Com Sazonalidade
Para saber se vale a pena colocar um modelo mais complexo em produção, é importante ter um baseline simples para comparar.
Isso pode ser a solução atual usada em sua empresa ou uma solução simples como a média dos valores passados no mesmo período.
Neste caso, vou usar o objeto SeasonalNaive da biblioteca statsforecast que faz a previsão baseado neste método.
from statsforecast import StatsForecast
from statsforecast.models import SeasonalNaive
model = StatsForecast(models=[SeasonalNaive(season_length=7)], freq='D', n_jobs=-1)
model.fit(train)
forecast_df = model.predict(h=h, level=[90])
forecast_df = forecast_df.reset_index().merge(valid, on=['ds', 'unique_id'], how='left')
wmape_ = wmape(forecast_df['y'], forecast_df['SeasonalNaive'])
print(f'WMAPE: {wmape_:.2%}')
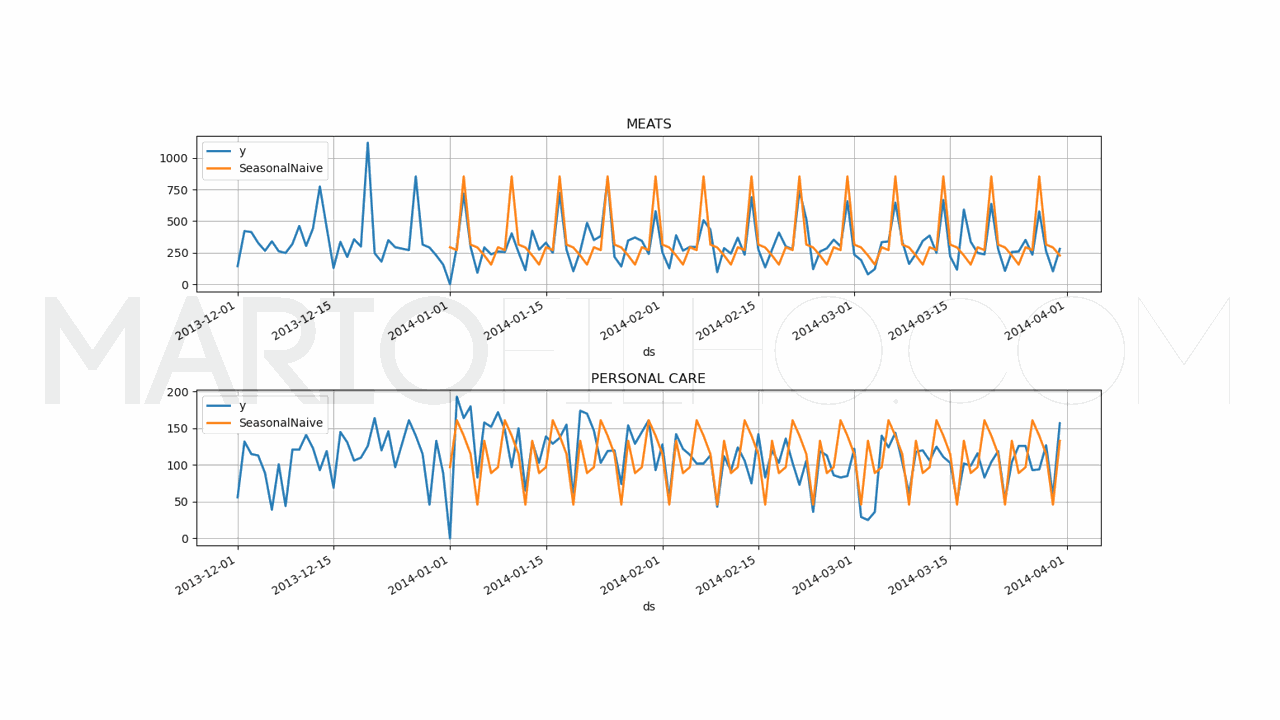
Esta baseline retornou um WMAPE de 33,69%, melhor do que a AutoLSTM do primeiro experimento, mas pior do que as duas versões da LSTM com variáveis exógenas.
Então, neste conjunto de testes, a melhor combinação foi usar os hiperparâmetros encontrados pela busca automática junto com variáveis adicionais e scaling, especialmente na versão sem petróleo.
Leia este artigo para saber mais sobre previsão de séries temporais com a biblioteca statsforecast.
Loss Function Personalizada com PyTorch (WMAPE)
Como o PyTorch não tem uma loss function para WMAPE, eu criei a seguinte, baseada na interface atual das losses de ponto do neuralforecast.
import torch
from typing import Union
from neuralforecast.losses.pytorch import BasePointLoss, _divide_no_nan, _weighted_mean
class WMAPE(BasePointLoss):
def __init__(self, horizon_weight=None):
super(WMAPE, self).__init__(
horizon_weight=horizon_weight,
outputsize_multiplier=1,
output_names=[""],
)
def __call__(
self,
y: torch.Tensor,
y_hat: torch.Tensor,
mask: Union[torch.Tensor, None] = None,
y_insample: Union[torch.Tensor, None] = None,
):
scale = _divide_no_nan(torch.ones_like(y, device=y.device), torch.abs(y))
losses = torch.abs(y - y_hat) * scale
weights = self._compute_weights(y=y, mask=mask) * torch.abs(y)
return _weighted_mean(losses=losses, weights=weights)