Ao usar machine learning para prever séries temporais, você não pode simplesmente dividir seus dados entre treino e validação com um split aleatório.
Se você fizer isso, seu modelo vai aprender a prever o passado com base no futuro e te dar uma estimativa altamente otimista (e errada) da performance em dados nunca vistos.
Em praticamente todos os projetos reais de machine learning você terá uma dimensão temporal e jamais deve ignorá-la.
As mudanças podem acontecer em nanossegundos ou séculos, mas elas acontecem e tudo o que interessa é o que o modelo ainda não viu.
Mesmo em casos que parecem estar congelados no tempo, como detecção de objetos em imagens, sofrem com mudanças sutis como a resolução das câmeras que melhora com o tempo.
Neste artigo você aprenderá três métodos para validar séries temporais corretamente e reduzir ao máximo as chances de ser pego de surpresa pela performance do seu modelo em produção.
Índice
- Validação Temporal Simples Com Ponto Fixo
- Validação Temporal Com Janela Deslizante
- Validação Temporal Com Janela Expansiva
- Validação Temporal Com Censura Entre Passado e Futuro
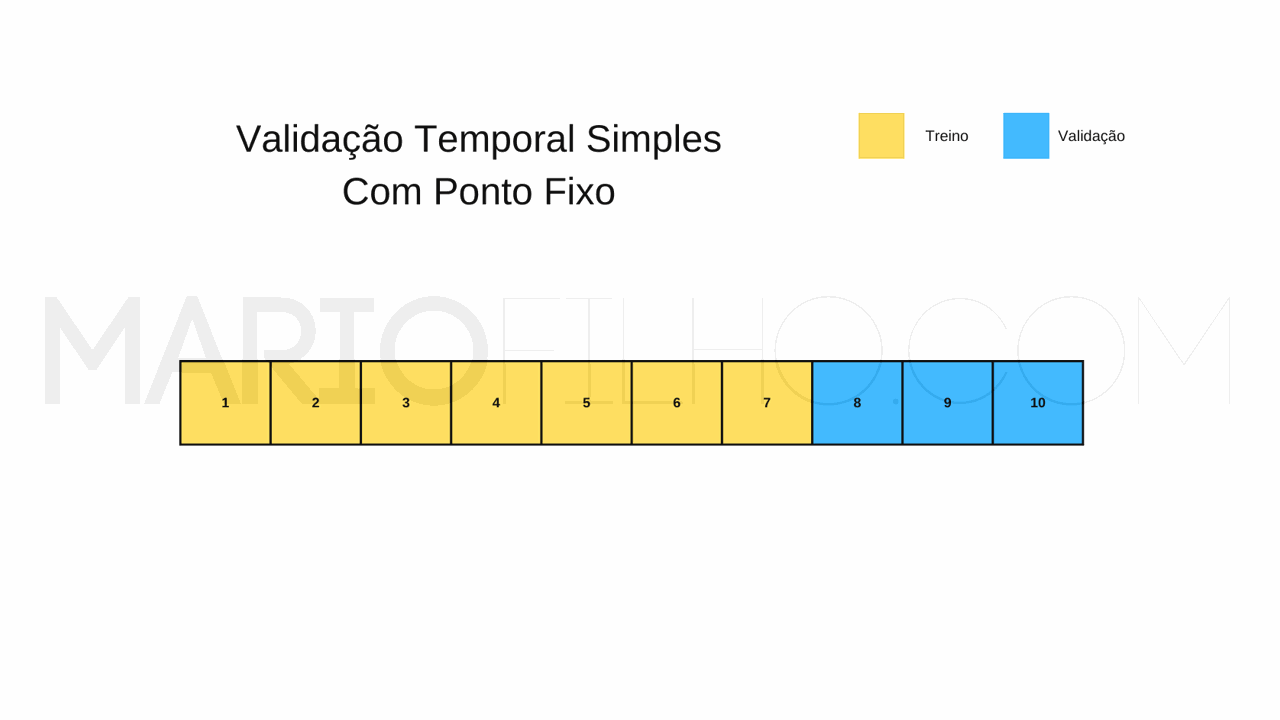
Validação Temporal Simples Com Ponto Fixo

Neste método você seleciona um ponto fixo (uma data ou timestamp) no tempo e coloca todas as observações anteriores a ele no conjunto de treino e todas as observações posteriores no conjunto de validação.
Eu recomendo deixar pelo menos 50% dos dados para treino.
import pandas as pd
import numpy as np
series = pd.Series(np.random.uniform(0,1,365),
index=pd.date_range('2021-01-01', '2021-12-31', freq='D'))
train = series.loc['2021-01-01':'2021-07-31']
valid = series.loc['2021-08-01':'2021-12-31']
É muito importante fazer isso ANTES de qualquer pré-processamento ou feature engineering para garantir que você não use os dados do futuro acidentalmente.
Desta maneira você simulará muito precisamente o que acontecerá quando seu modelo for colocado em produção.
Afinal, se você já tiver os dados do futuro, não precisará de um modelo para prevê-lo.
Este método já é suficiente para a maioria dos casos.
Certamente muito melhor do que um split aleatório, mas podemos ir além.
Validação Temporal Com Janela Deslizante
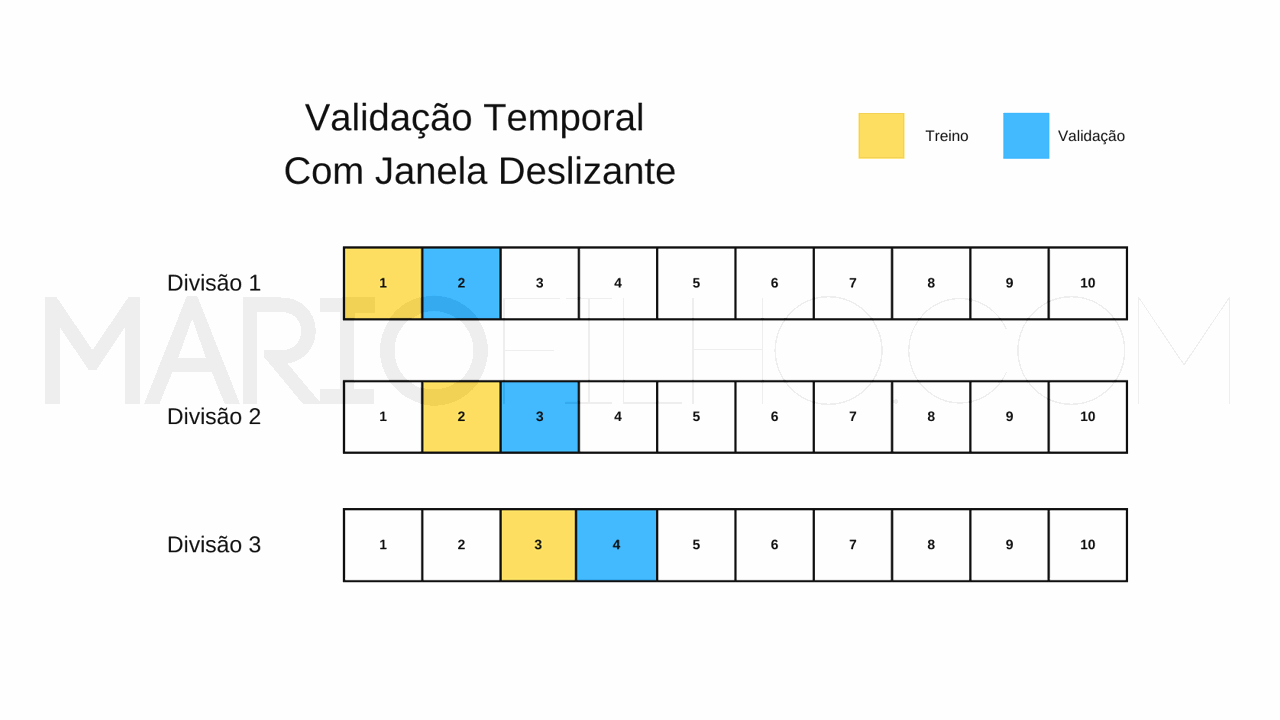
Neste método você determina previamente o tamanho de uma janela (um intervalo de tempo) para os dados de treino e outra para os dados de validação.
Elas podem ser do mesmo tamanho, isso é decidido caso a caso.
O mais importante é aplicar as janelas sempre respeitando a ordem cronológica dos dados: treinando no passado e validando no futuro.
for date in pd.date_range('2021-02-01', '2021-12-31', freq='MS'):
delta = date - pd.offsets.MonthBegin(1)
train = series.loc[delta:date-pd.offsets.Day(1)]
valid = series.loc[date:date+pd.offsets.MonthEnd(1)]
A diferença para o método anterior é que em vez de usar apenas uma divisão, agora você deslizará as duas janelas para frente e repetirá o processo, criando algo similar à validação cruzada tradicional.
Por exemplo, se você tiver um ano de dados diários e quiser usar um mês para treino e um mês para validação, primeiro você treinará com os dados de Janeiro e validará com os dados de Fevereiro.
Depois você treinará com os dados de Fevereiro e validará com os dados de Março.
E assim vai.
Este método te dá uma estimativa mais robusta da performance do seu modelo com o passar do tempo porque agrega as métricas sobre múltiplos períodos, compensando as flutuações naturais das séries temporais.
Outra maneira muito útil de usar este método é manter a janela de treino fixa e deslizar a de validação para frente.
No exemplo acima, sempre usar Janeiro como treino mas verificar como este mesmo modelo se comporta em Fevereiro, Março, Abril, etc.
Esta é uma maneira fantástica de descobrir como seu modelo se degrada com o passar do tempo caso você não o retreine em dados mais recentes.
Eu uso muito para decidir qual a frequência ideal para atualizar os modelos.
Na prática sempre começo com uma validação simples de ponto fixo e depois vou para a validação com janela deslizante, por ser um método mais próximo do que acontecerá quando o modelo for colocado em produção.
Validação Temporal Com Janela Expansiva
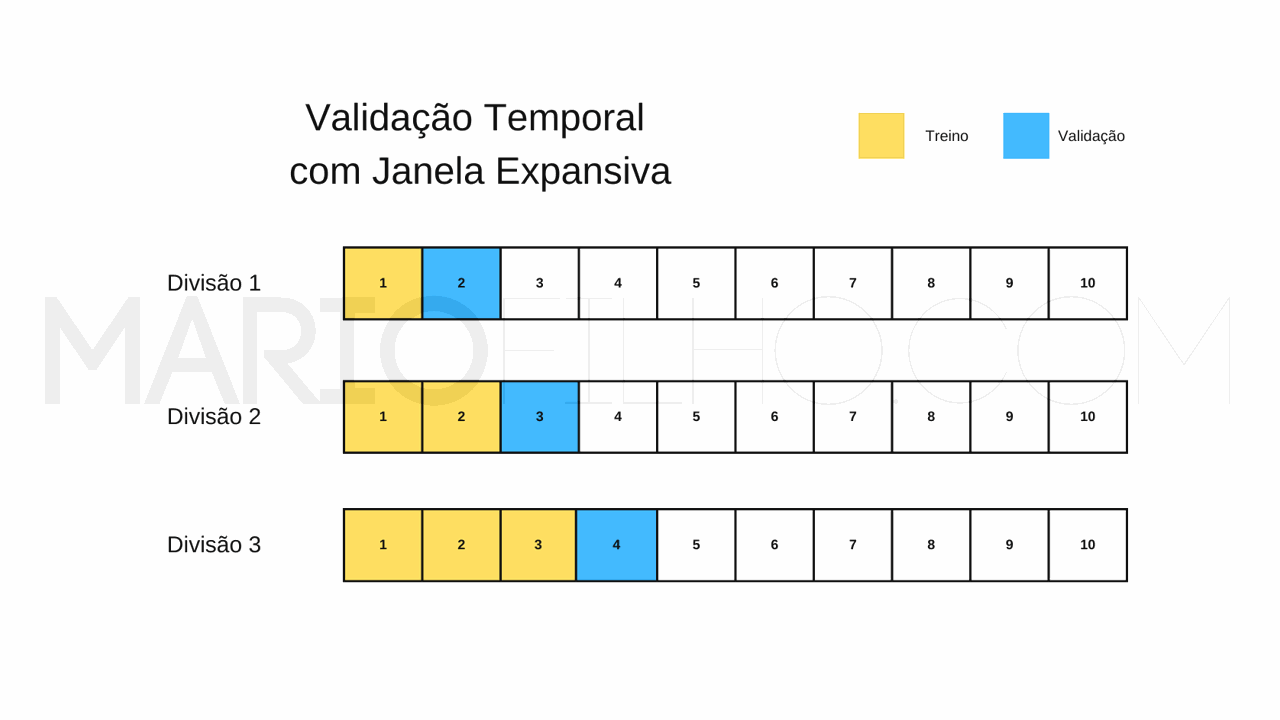
Este método geralmente significa expandir a janela de treino com o passar do tempo e manter a de validação fixa.
A ideia é treinar seu modelo sobre cada vez mais dados, o que é muito útil em casos onde você tem poucos dados e também para não perder padrões antigos que ainda são válidos.
for date in pd.date_range('2021-02-01', '2021-12-31', freq='MS'):
train = series.loc[:date-pd.offsets.Day(1)]
valid = series.loc[date:date+pd.offsets.MonthEnd(1)]
Continuando nosso exemplo, no primeiro passo você treinará com os dados de Janeiro e validará com os dados de Fevereiro.
No segundo, você treinará com os dados de Janeiro e Fevereiro e validará com os dados de Março.
E assim vai, sempre aumentando a janela de treino enquanto mantém a de validação fixa.
Apesar de, em regra, treinar um modelo com mais dados dar melhores resultados, seu modelo pode sentir dificuldades em aprender e se adaptar a padrões novos e esquecer padrões antigos que deixaram de existir.
Eu costumo usar este método apenas quando tenho dados novos chegando com pouca frequência (por exemplo, dados trimestrais de PIB), mas em geral prefiro a validação com janela deslizante.
Validação Temporal Com Censura Entre Passado e Futuro
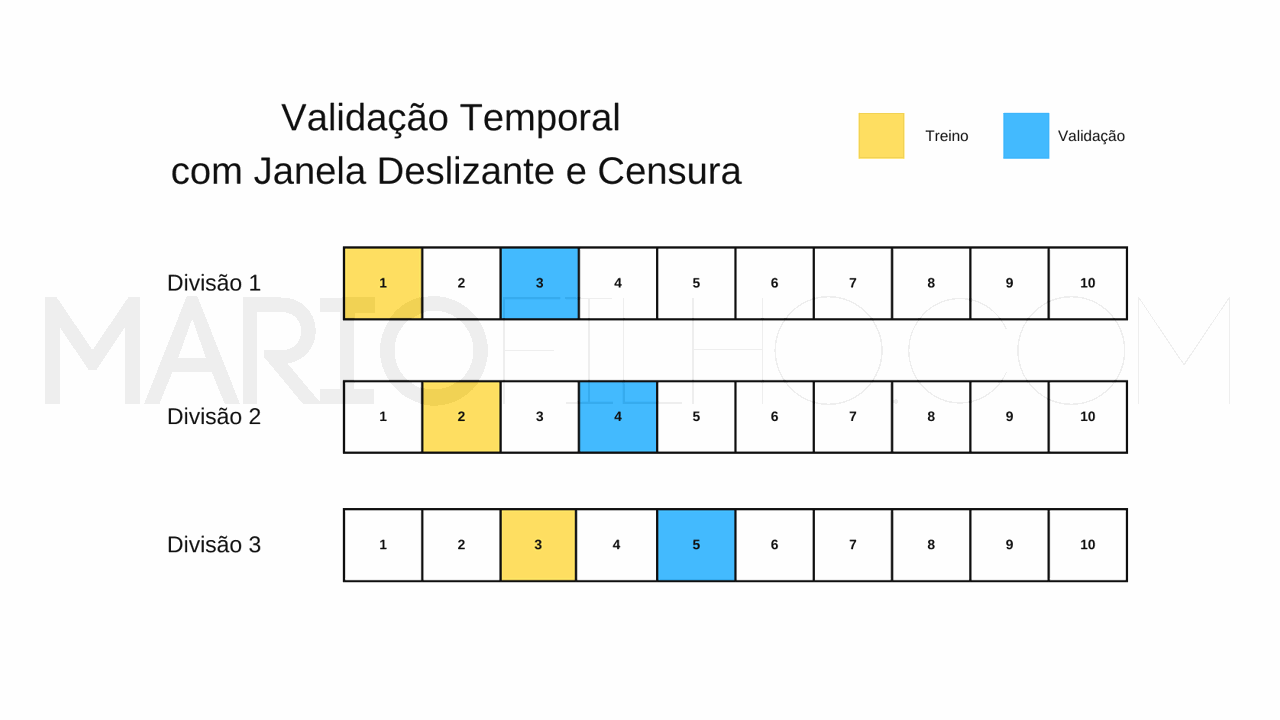
Uma maneira de tornar sua validação temporal ainda mais robusta é inserir um intervalo de tempo entre o último registro dos dados de treino e o primeiro dos dados de validação.
Esta técnica pode ser usada com qualquer um dos métodos acima.
for date in pd.date_range('2021-02-01', '2021-12-31', freq='MS'):
delta = date - pd.offsets.MonthBegin(1)
train = series.loc[delta:date-pd.offsets.Day(1)]
valid = series.loc[date+pd.offsets.MonthEnd(1)+pd.offsets.Day(1):date+pd.offsets.MonthEnd(2)]
Isto é muito útil nos casos em que dados recentes não chegam imediatamente ou você quer usar os dados mais recentes para validar continuamente seu modelo de maneira automática.
Já trabalhei em um caso de previsão de demanda onde os dados de vendas chegavam com um atraso de 3 semanas, então eu precisei validar meu modelo ignorando 3 semanas de dados entre o momento da previsão e a realidade.
Em nosso exemplo, ao invés de usar os dados de Fevereiro para validar o modelo treinado com os dados de Janeiro, você usaria os dados de Março.
Outra maneira, em casos que você não tenha problemas para obter dados recentes, seria usar os dados de Janeiro para treinar, dados de Fevereiro para otimizar hiperparâmetros e dados de Março para validar.
Em competições geralmente retreinamos usando todos os dados (Janeiro e Fevereiro) depois de otimizar os hiperparâmetros, mas não recomendo que você faça isso em projetos do dia-a-dia.
Retreinar desta maneira pode invalidar os resultados da otimização e validação e prejudicar a performance do modelo em produção.
Com esses métodos em sua caixa de ferramentas, você estará melhor preparado que 99% dos cientistas de dados por aí para lidar com qualquer tarefa de previsão de séries temporais.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.