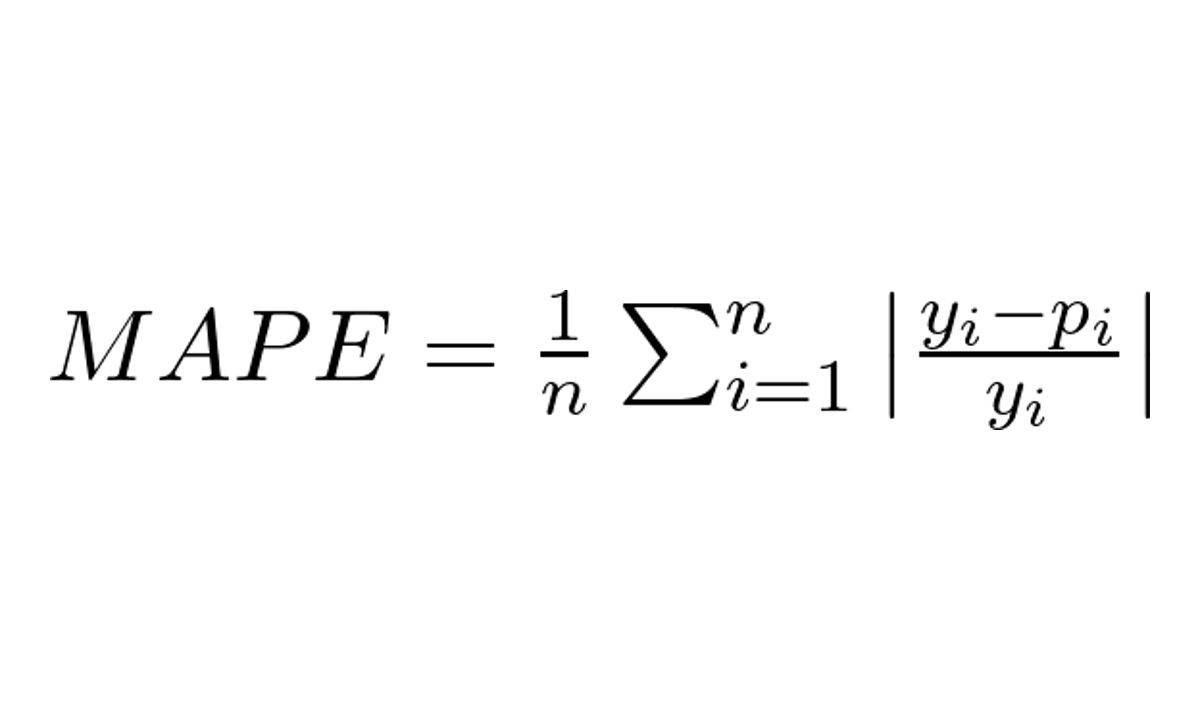
Índice
- O Que é Erro Absoluto Percentual Médio ou MAPE?
- Qual a Fórmula do MAPE?
- Como Interpretar o MAPE?
- Como Calcular o MAPE Usando Scikit-learn em Python?
- Como Calcular o MAPE em R?
- Qual a Diferença Entre MAPE e WMAPE?
- Qual a Diferença Entre MAPE e WAPE?
- Qual a Diferença Entre MAPE e SMAPE?
- Qual a Diferença Entre MAPE e RMSE?
- Qual a Diferença Entre MAPE e MAE?
O Que é Erro Absoluto Percentual Médio ou MAPE?
Erro absoluto percentual médio (MAPE) é uma métrica para avaliar modelos de regressão em machine learning.
Ela é bastante utilizada na previsão de séries temporais, como previsão de demanda e precificação de ativos financeiros.
O MAPE é expressado em porcentagem, que é fácil de entender para a maioria das pessoas e ajuda na comunicação de resultados para pessoas que não têm conhecimento técnico em machine learning.
Além disso, ela é uma boa métrica para usar quando o desvio absoluto das previsões não significa o mesmo para valores em escalas diferentes (por exemplo, prever demanda para um produto que vende 1000 unidades por dia e outro que vende 10 unidades por dia).
Qual a Fórmula do MAPE?
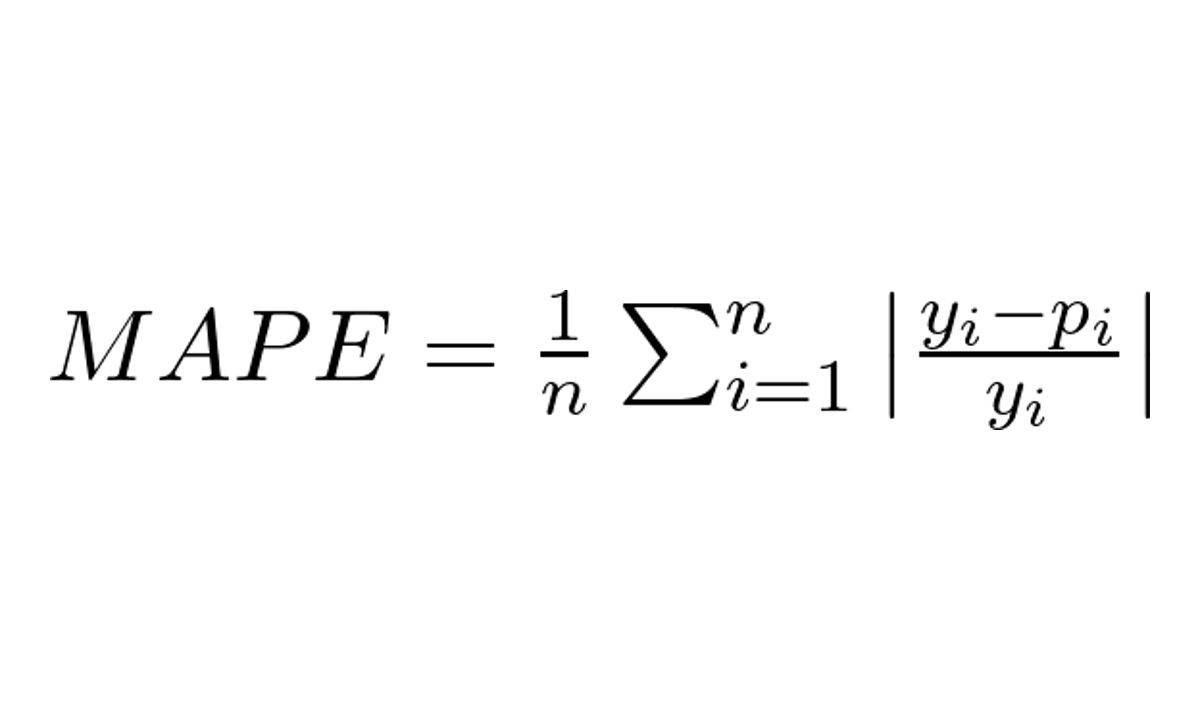
Onde:
- n é o número total de amostras
- y_i é o valor real para a amostra i
- p_i é o valor previsto para amostra i
O primeiro passo é calcular o erro absoluto percentual para cada ponto de dado.
Depois some todos esses erros e, finalmente, divida pelo número total de amostras.
Você ainda pode multiplicar este valor por 100 para ficar mais fácil de explicar.
Como Interpretar o MAPE?
Um valor de MAPE baixo significa que as previsões estão próximas dos valores observados (seu modelo está acertando bem), enquanto um valor alto indica que as previsões estão longe dos valores observados (o modelo precisa ser melhorado).
Na prática, é importante estabelecer um valor aceitável para o erro.
Já trabalhei em casos de previsão de demanda onde o erro ideal era de, no máximo, 10% e um erro aceitável, de 30%.
Isso também dependerá da natureza do problema e do tipo de dados que você está usando.
Por exemplo, produtos que vendem pouco podem afetar o MAPE desproporcionalmente, pois mesmo pequenos erros nas previsões podem representar uma porcentagem significativa do valor real.
Produtos com ciclo de vida curto podem ser difíceis de prever, pois a demanda pode mudar rapidamente, e essa imprevisibilidade pode afetar o MAPE.
Ele também começa a falhar quando a série temporal tem muitos valores zero, pois o MAPE não consegue calcular o erro percentual para estes exemplos.
Abaixo você verá algumas adaptações que podem ser feitas para lidar com esses problemas.
Como Calcular o MAPE Usando Scikit-learn em Python?
Para calcular o MAPE em Python, vamos utilizar a função mean_absolute_percentage_error do scikit-learn.
from sklearn.metrics import mean_absolute_percentage_error
# Dados observados e previstos
y_true = [15, 30, 45, 60, 75]
y_pred = [14, 32, 40, 55, 80]
# Calcular MAPE
mape = mean_absolute_percentage_error(y_true, y_pred)
print("MAPE: {:.2f}%".format(mape*100))
Onde y_true e y_pred podem ser arrays do NumPy, listas ou Series do Pandas.
O primeiro com os valores observados e o segundo com os valores previstos pelo modelo.
Se tiver algum valor zero nos dados observados y_true ele ainda fará o cálculo, mas retornará um valor muito alto, inútil na prática.
Como Calcular o MAPE em R?
Para calcular o MAPE em R, vamos utilizar a função mape do pacote Metrics.
library(Metrics)
# Dados observados e previstos
y_true <- c(15, 30, 45, 60, 75)
y_pred <- c(14, 32, 40, 55, 80)
# Calcular MAPE
mape_ <- mape(y_true, y_pred)
print(paste0("MAPE: ", round(mape_*100, 2), "%"))
A função mape recebe como parâmetros os valores reais y_true e os valores previstos y_pred e retorna o MAPE.
Neste caso, se tiver algum valor zero nos dados observados y_true ela retornará Inf (infinito).
Qual a Diferença Entre MAPE e WMAPE?
O WMAPE (Weighted Mean Absolute Percentage Error) é uma variação do MAPE que atribui importâncias diferentes para cada amostra através da ponderação na hora de calcular a média.
Esta á a fórmula:
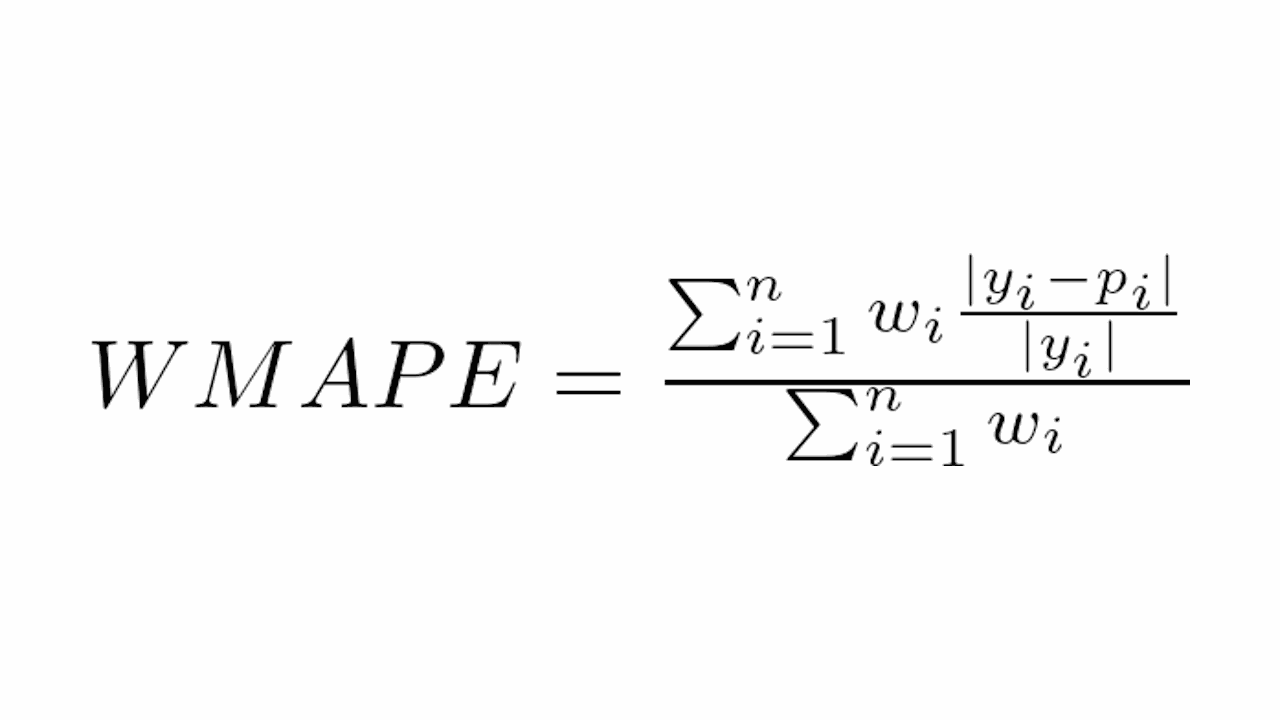
Onde:
- w_i é o peso associado à amostra i
- y_i é o valor real
- p_i é o valor previsto
- n é o número total de amostras
O WMAPE com pesos uniformes (pesos iguais para todas as amostras) é equivalente ao MAPE.
Por isso, a escolha dos pesos corretos é muito importante.
Uma das escolhas mais comuns para os pesos é simplesmente o valor absoluto do valor observado da amostra, o que elimina o problema de valores zero já que as amostras com valores zero terão peso zero.
Um exemplo onde o WMAPE pode ser mais adequado que o MAPE é na previsão de tráfego em rodovias.
Como o tráfego varia de hora em hora, acertar as previsões no horário de pico pode ser mais importante para gerir o fluxo de veículos.
Na fórmula isso significa dar pesos maiores às amostras referentes a horários de pico.
Para usar o WMAPE no scikit-learn em Python, basta adicionar o argumento sample_weight na chamada da função
mean_absolute_percentage_error e passar uma lista com os pesos das amostras.
from sklearn.metrics import mean_absolute_percentage_error
# Dados observados e previstos
y_true = [15, 30, 45, 60, 75]
y_pred = [14, 32, 40, 55, 80]
# Calcular WMAPE
wmape = mean_absolute_percentage_error(y_true, y_pred, sample_weight=y_true)
print("WMAPE: {:.2f}%".format(wmape*100))
Nesse exemplo, passamos como pesos os valores observados y_true.
Qual a Diferença Entre MAPE e WAPE?
O WAPE (Weighted Absolute Percentage Error) é uma variação do MAPE que faz as somas dos erros percentuais e dos valores observados antes da divisão.
Ele é calculado pela seguinte fórmula:
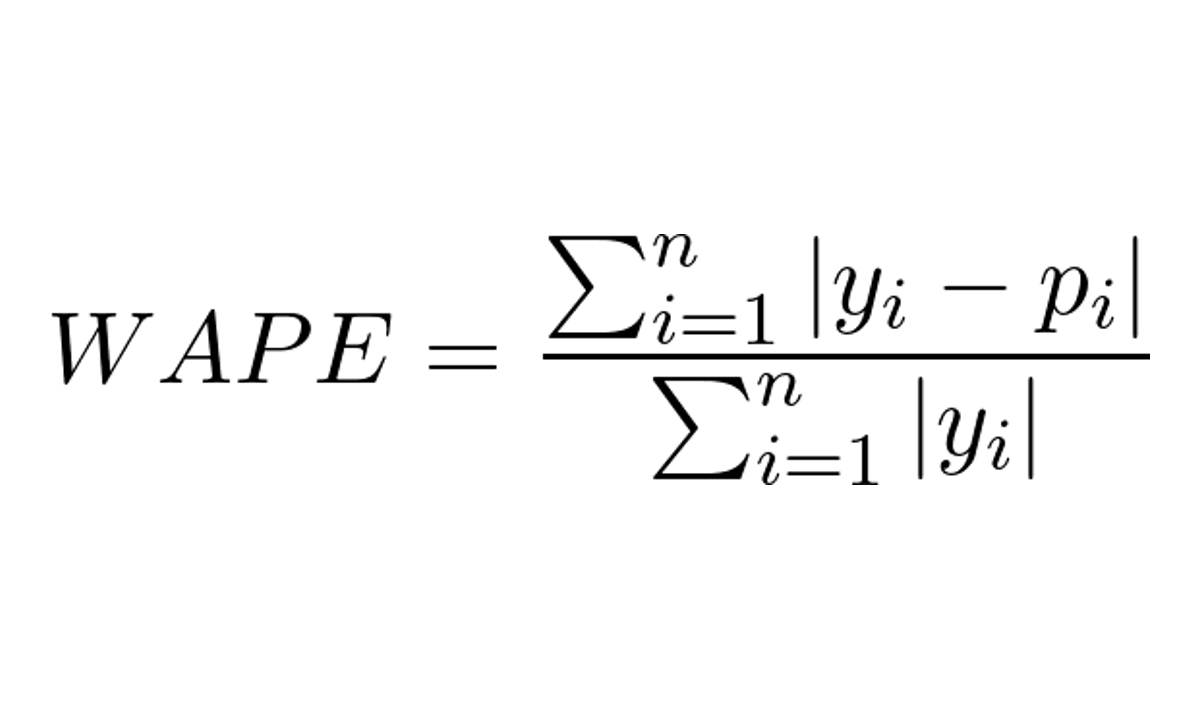
Onde:
- y_i é o valor real para o período ou amostra i
- p_i é o valor previsto para o período ou amostra i
- n é o número de períodos ou amostras no conjunto de dados
O WAPE é outra maneira de escapar do problema de valores zero nos dados observados.
Ele é outra alternativa recomendada quando a maioria de seus produtos não vendem em todos os períodos ou são vendidos em pouca quantidade.
Quando um produto tem baixo volume de vendas, qualquer erro na previsão tem um impacto significativo na porcentagem de erro calculada pelo MAPE.
Mesmo que o erro absoluto seja pequeno, ele será dividido por um valor muito baixo, resultando em uma porcentagem de erro elevada.
Isso pode dar a impressão que a previsão é muito pior do que realmente é.
Já no caso do WAPE, como a divisão é feita pela soma de todos os valores reais absolutos de uma vez, esse efeito é menor.
Qual a Diferença Entre MAPE e SMAPE?
O SMAPE (Symmetric Mean Absolute Percentage Error) é uma variação do MAPE que procura dar a mesma importância a erros positivos e negativos entre valores reais e previstos, já que o MAPE dá mais importância aos erros em que o valor real é menor que o valor previsto.
A fórmula usada na prática, uma modificação da fórmula original, é a seguinte:
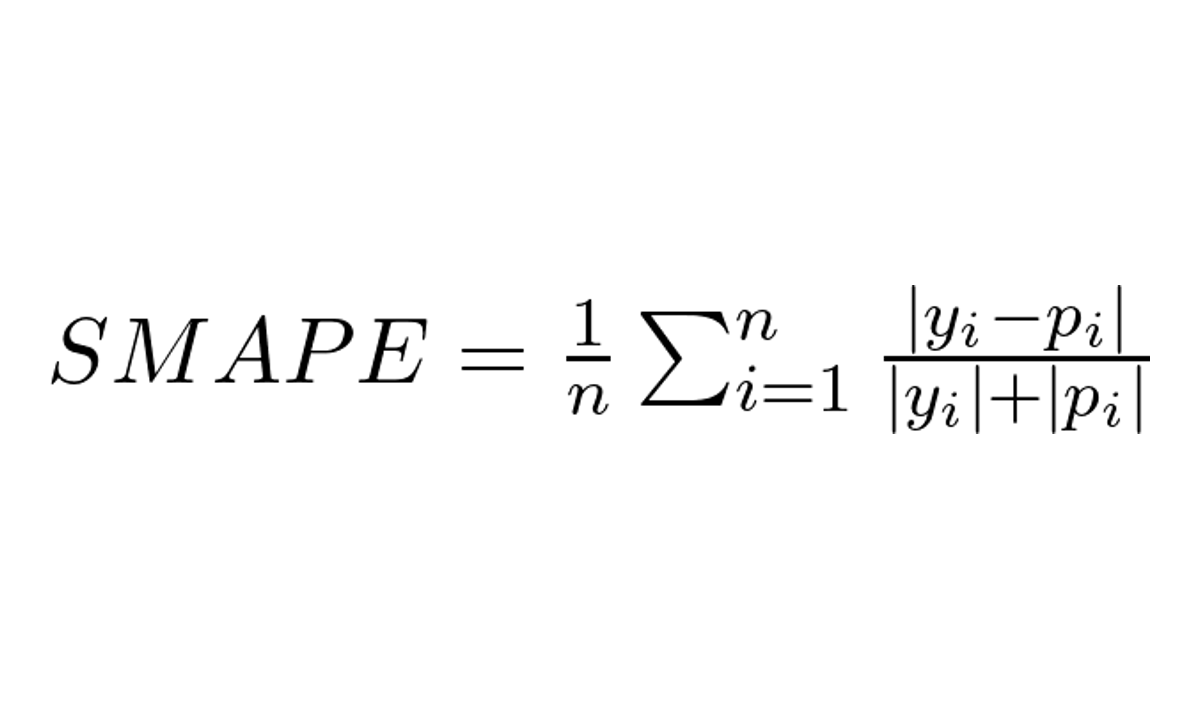
Onde:
- y_i é o valor real para o período ou amostra i
- p_i é o valor previsto para o período ou amostra i
- n é o número de períodos ou amostras no conjunto de dados
Apesar de ser uma métrica de erro que já foi utilizada até mesmo em competições de machine learning, ela não é unanimidade entre os especialistas.
Diferente das outras alternativas, ela não resolve o problema de valores zero nos dados observados e previstos.
Além disso você encontrará várias definições diferentes da fórmula, o que gera confusão na hora de implementar e apresentar.
Já que temos as outras alternativas, que são mais simples e resolvem os problemas do MAPE original, não vejo vantagem em usar o SMAPE.
Qual a Diferença Entre MAPE e RMSE?
Uma diferença importante é como cada uma mede o erro.
O RMSE mede o erro como a raiz quadrada da média dos erros ao quadrado, ou seja, é a raiz quadrada da soma dos erros ao quadrado, dividido pelo número de amostras.
Isso significa que o RMSE é uma medida de erro nas unidades originais da variável alvo enquanto o MAPE é uma medida de erro relativo, ou seja, a porcentagem de erro.
Nesta comparação você pode ver como o RMSE sempre dá o mesmo valor, mas o MAPE varia de acordo com a escala do valor observado.
| Valor Observado | Valor Previsto | MAPE (x 100) | RMSE |
|---|---|---|---|
| 50 | 45 | 10 | 5 |
| 60 | 55 | 8.33 | 5 |
| 70 | 65 | 7.14 | 5 |
| 80 | 75 | 6.25 | 5 |
| 90 | 85 | 5.56 | 5 |
| 100 | 95 | 5 | 5 |
Por isso, o MAPE é indicado quando for importante diferenciar entre o mesmo erro em escalas diferentes.
Qual a Diferença Entre MAPE e MAE?
O MAE, assim como o RMSE, mede o erro nas unidades originais do alvo. Só que neste caso, é a soma dos erros absolutos, dividido pelo número de amostras.
Veja esta tabela comparando o MAE e o MAPE sobre os mesmos itens do exemplo anterior:
| Valor Observado | Valor Previsto | MAPE (x 100) | MAE |
|---|---|---|---|
| 50 | 45 | 10 | 5 |
| 60 | 55 | 8.33333 | 5 |
| 70 | 65 | 7.14286 | 5 |
| 80 | 75 | 6.25 | 5 |
| 90 | 85 | 5.55556 | 5 |
| 100 | 95 | 5 | 5 |
Apesar do MAE ter o mesmo valor do RMSE demonstrado acima, isso nem sempre é o caso, como você pode ver no artigo sobre o RMSE.
A principal diferença entre o MAPE e o MAE é a mesma do MAPE e do RMSE.
O MAPE é uma medida de erro relativo, expressa como uma porcentagem, enquanto o MAE é uma medida da amplitude do erro, expressa na mesma unidade do alvo original.
Por exemplo, se as previsões de vendas de uma loja estiverem 10% abaixo das vendas reais, isso pode ser considerado um erro alto se as vendas reais são de 100 unidades, mas um erro baixo se as vendas reais são de 1 milhão de unidades.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.