
Muitas pessoas acham a configuração inicial do CatBoost um pouco intimidante.
Talvez você tenha ouvido falar sobre sua capacidade de trabalhar com features categóricas sem nenhum pré-processamento, mas não sabe por onde começar.
Neste tutorial passo a passo, vou simplificar as coisas para você.
Afinal, esta é apenas mais uma biblioteca de gradient boosting para ter em sua caixa de ferramentas.
Vou guiá-lo pelo processo de instalação do CatBoost, carregamento dos seus dados e configuração de um classificador CatBoost.
Ao longo da jornada, também abordaremos como dividir seus dados em um conjunto de treinamento e um conjunto de teste, como lidar com dados desbalanceados e como treinar seu modelo em uma GPU.
Ao final deste guia, você estará pronto e confiante para usar o CatBoost em seus próprios projetos de classificação binária.
Então, vamos começar!
Instalando o CatBoost no Python
Existem duas maneiras principais de instalar o CatBoost no Python: usando pip e conda.
Se você prefere usar pip, pode instalar o CatBoost executando o seguinte comando no seu terminal:
pip install catboost
Se você prefere usar conda, pode instalá-lo executando:
conda install -c conda-forge catboost
Certifique-se de ter pip ou conda instalado em seu ambiente Python antes de executar esses comandos.
Depois de instalar o CatBoost com sucesso, você está pronto para seguir para o próximo passo: carregar seus dados.
Carregando os Dados
Usaremos o Adult Dataset. Você pode baixá-lo no Kaggle.
Este é um conjunto de dados bem conhecido que contém informações demográficas sobre a população dos EUA.
O objetivo é prever se uma pessoa ganha mais de $50.000 por ano.
O destaque do CatBoost é que ele pode lidar com features categóricas sem nenhum pré-processamento, então escolhi este conjunto de dados porque ele tem uma mistura de features categóricas e numéricas.
Usaremos a biblioteca pandas para carregar nossos dados.
Primeiro, vamos importar as bibliotecas necessárias:
import pandas as pd
from sklearn.model_selection import train_test_split
Agora, vamos carregar os dados.
Usaremos a função read_csv do pandas para carregar os dados.
data = pd.read_csv(data_path)
| age | workclass | fnlwgt | education | education.num | marital.status | occupation | relationship | race | sex | capital.gain | capital.loss | hours.per.week | native.country | income |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 90 | ? | 77053 | HS-grad | 9 | Widowed | ? | Not-in-family | White | Female | 0 | 4356 | 40 | United-States | <=50K |
| 82 | Private | 132870 | HS-grad | 9 | Widowed | Exec-managerial | Not-in-family | White | Female | 0 | 4356 | 18 | United-States | <=50K |
| 66 | ? | 186061 | Some-college | 10 | Widowed | ? | Unmarried | Black | Female | 0 | 4356 | 40 | United-States | <=50K |
| 54 | Private | 140359 | 7th-8th | 4 | Divorced | Machine-op-inspct | Unmarried | White | Female | 0 | 3900 | 40 | United-States | <=50K |
| 41 | Private | 264663 | Some-college | 10 | Separated | Prof-specialty | Own-child | White | Female | 0 | 3900 | 40 | United-States | <=50K |
Agora temos nossos dados carregados e prontos para uso.
O próximo passo é dividir nossos dados em um conjunto de treinamento e um conjunto de teste.
Vamos usar a função train_test_split do módulo sklearn.model_selection.
Dividiremos os dados em 80% para treinamento e 20% para teste.
X = data.drop('income', axis=1)
y = data['income']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
No código acima, X é nosso conjunto de features e y é nossa variável alvo, que é ‘income’ neste caso.
Agora temos nossos dados divididos em conjuntos de treinamento e teste, e estamos prontos para treinar nosso classificador CatBoost.
Observe como não precisamos fazer nenhum pré-processamento para features numéricas ou categóricas.
Treinando um Classificador CatBoost
A biblioteca CatBoost fornece uma classe CatBoostClassifier para tarefas de classificação binária e multiclasse.
Por padrão, ela usa valores de hiperparâmetros que são geralmente eficazes para uma ampla gama de conjuntos de dados.
Ainda assim, recomendo que você tune os hiperparâmetros para seu conjunto de dados específico para obter o melhor desempenho.
Vamos importar a biblioteca necessária e criar uma instância do CatBoostClassifier:
from catboost import CatBoostClassifier
cat_features = X_train.select_dtypes(include=['object']).columns.tolist()
model = CatBoostClassifier(cat_features=cat_features)
Criei a variável cat_features para armazenar os nomes das colunas de features categóricas.
O método select_dtypes é usado para selecionar colunas de um DataFrame com base em seus tipos de dados.
Neste caso, estamos selecionando colunas com o tipo de dados ‘object’, que são nossas features categóricas.
O classificador otimiza a função Logloss, também conhecida como cross-entropy loss.
É a função de perda mais comum usada para tarefas de classificação binária.
Por padrão, o CatBoost usa codificação one-hot para features categóricas com um pequeno número de valores diferentes.
Para features com alta cardinalidade (como CEPs), o CatBoost usa uma codificação mais complexa, incluindo codificação de probabilidade e contagens de níveis categóricos.
Cardinalidade é o termo técnico para o número de valores únicos em uma coluna categórica.
Precisamos especificar os nomes das colunas de features categóricas no parâmetro cat_features ao inicializar o CatBoostClassifier.
Eu selecionei todas as features não numéricas como features categóricas no código acima.
Lidando com Dados Desbalanceados
O CatBoost fornece o parâmetro scale_pos_weight.
Este parâmetro ajusta o custo de classificar erroneamente exemplos positivos (classe 1).
Um bom valor padrão é a razão entre amostras negativas e positivas no conjunto de dados de treinamento.
Basta dividir o número de amostras negativas pelo número de amostras positivas e passar o resultado para o parâmetro scale_pos_weight:
scale_pos_weight = len(y_train[y_train=='<=50K']) / len(y_train[y_train=='>50K'])
model = CatBoostClassifier(cat_features=cat_features, scale_pos_weight=scale_pos_weight)
Tenha cuidado caso você precise prever probabilidades reais do evento positivo.
Este parâmetro quebra a calibração das probabilidades, então não é recomendado para uso em tarefas onde a calibração é importante.
Nossos dados não são terrivelmente desbalanceados, então não usarei este parâmetro neste exemplo.
Treinamento Usando GPU
O CatBoost permite que você treine seu modelo usando uma GPU.
Isso pode acelerar significativamente o processo de treinamento, especialmente para grandes conjuntos de dados.
Para habilitar o treinamento em GPU, defina o parâmetro task_type como ‘GPU’ ao inicializar o CatBoostClassifier:
model = CatBoostClassifier(cat_features=cat_features, task_type='GPU')
Por fim, vamos treinar nosso modelo nos dados de treinamento:
model.fit(X_train, y_train)
Com isso, nosso classificador CatBoost está treinado e pronto para fazer previsões.
Fazendo Previsões com o CatBoost
Existem dois tipos de previsões que podemos fazer: previsões de classe e previsões de probabilidade.
Previsões de Classe
Neste caso, o modelo prevê diretamente o rótulo da classe.
Ele faz isso definindo todos os exemplos onde a probabilidade da classe positiva é maior que 0,5 como 1 e o restante como 0.
class_predictions = model.predict(X_test)
No código acima, model.predict() é usado para fazer previsões de classe nos dados de teste X_test.
Prevendo Probabilidades
Em alguns casos, as probabilidades de cada classe são mais importantes do que as previsões de classe.
Isso é útil quando queremos ter uma medida da confiança do modelo em suas previsões ou selecionar um limiar personalizado para a classe positiva.
O CatBoost nos permite prever essas probabilidades usando o método predict_proba:
probability_predictions = model.predict_proba(X_test)
No código acima, model.predict_proba() é usado para prever as probabilidades das classes.
A saída é uma matriz 2D, onde o primeiro elemento de cada par é a probabilidade da classe negativa (0) e o segundo elemento é a probabilidade da classe positiva (1).
Agora que sabemos como fazer previsões, vamos seguir para avaliar o desempenho do nosso modelo.
Avaliando o Desempenho do Modelo
Usaremos várias métricas para isso: Log Loss, ROC AUC e um relatório de classificação.
Primeiro, vamos importar as funções necessárias do módulo sklearn.metrics:
from sklearn.metrics import log_loss, roc_auc_score, classification_report
Log Loss
Log Loss mede quão bem um modelo pode prever a verdadeira probabilidade de cada classe.
Como é a métrica diretamente otimizada pelo CatBoost, tende a ser uma boa medida do desempenho do modelo.
Quanto menor o log loss, melhores as previsões.
Não é adequado se você estiver usando scale_pos_weight para lidar com dados desbalanceados.
Nesse caso, você deve usar ROC AUC.
log_loss_value = log_loss(y_test, probability_predictions[:,1])
print(f'Log Loss: {log_loss_value}')
Usamos probability_predictions[:,1] para obter a probabilidade da classe positiva (1), já que o log loss trabalha com probabilidades, não com rótulos de classe.
ROC AUC
ROC AUC (Área Sob a Curva ROC - Receiver Operating Characteristic) é uma medida de desempenho para problemas de classificação onde você está mais interessado em quão bem o modelo prevê os exemplos positivos.
Quanto maior o AUC, melhor o modelo.
roc_auc = roc_auc_score(y_test, probability_predictions[:,1])
print(f'ROC AUC: {roc_auc}')
Assim como antes, precisamos passar a probabilidade da classe positiva (1) para a função roc_auc_score.
Relatório de Classificação
Um relatório de classificação exibe as pontuações de precisão, recall, F1 e suporte para cada classe e para o modelo como um todo.
class_report = classification_report(y_test, class_predictions)
print(f'Relatório de Classificação:\n {class_report}')
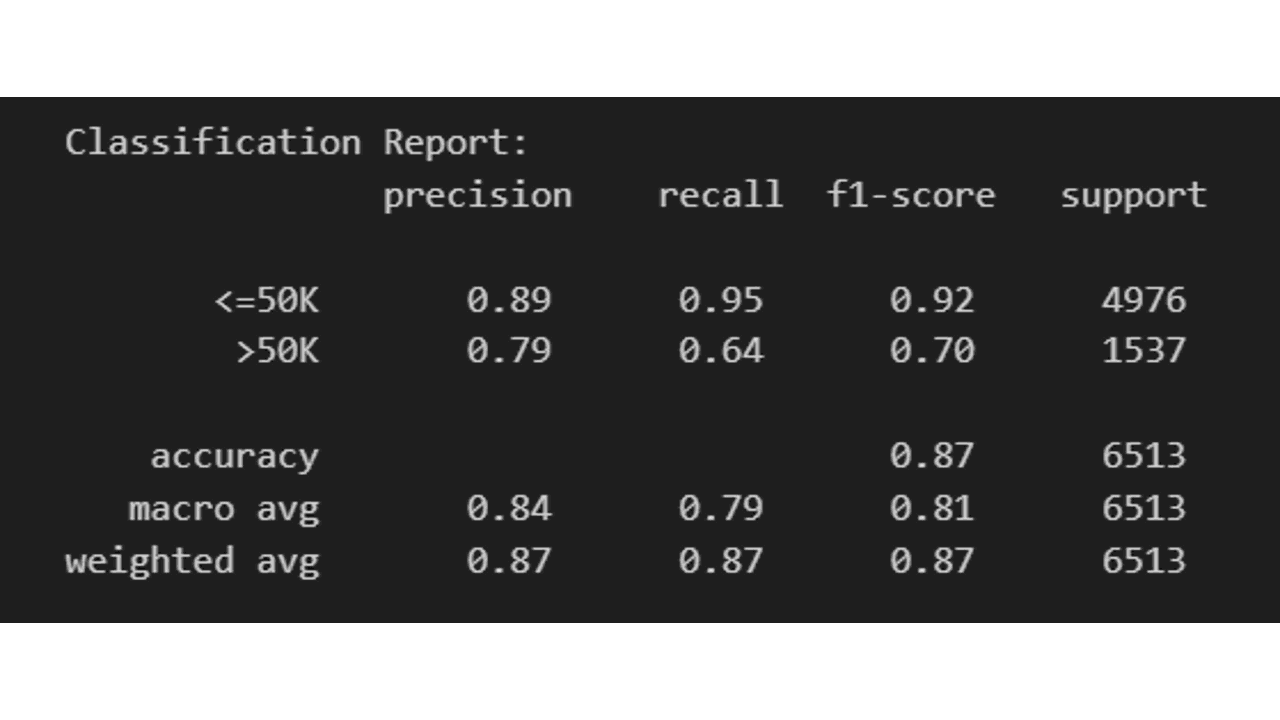
Ao avaliar essas métricas, você entenderá quão bem seu classificador CatBoost está se saindo em sua tarefa de classificação binária.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.