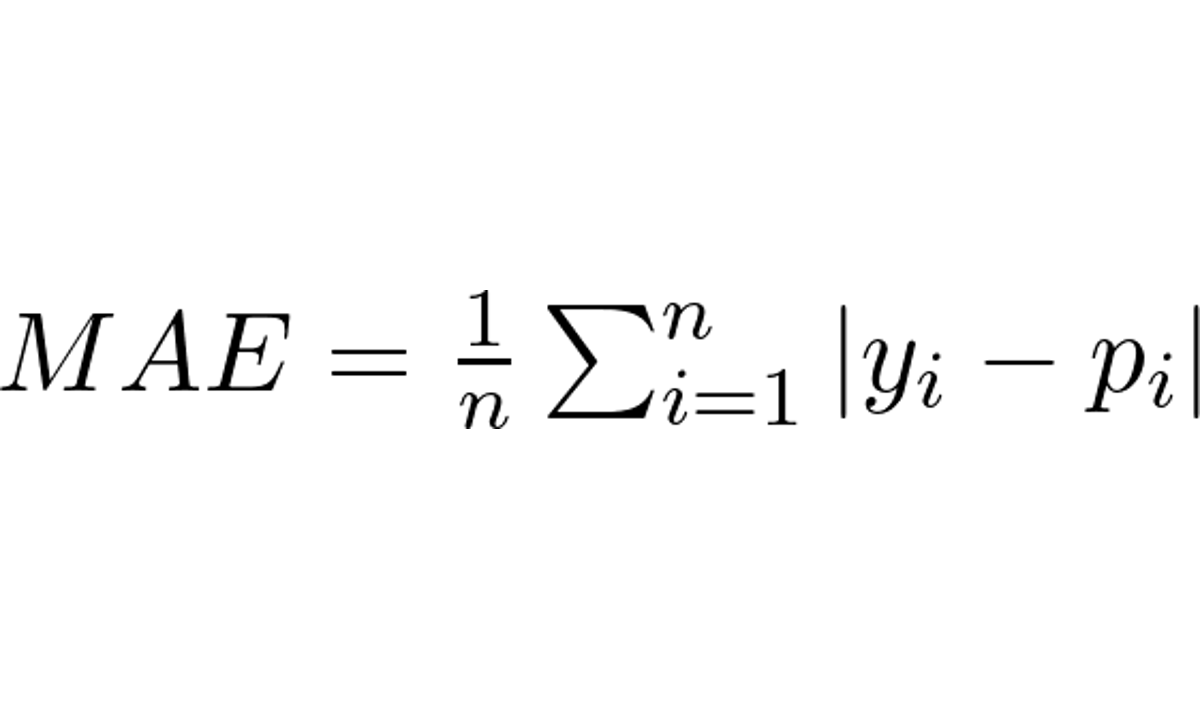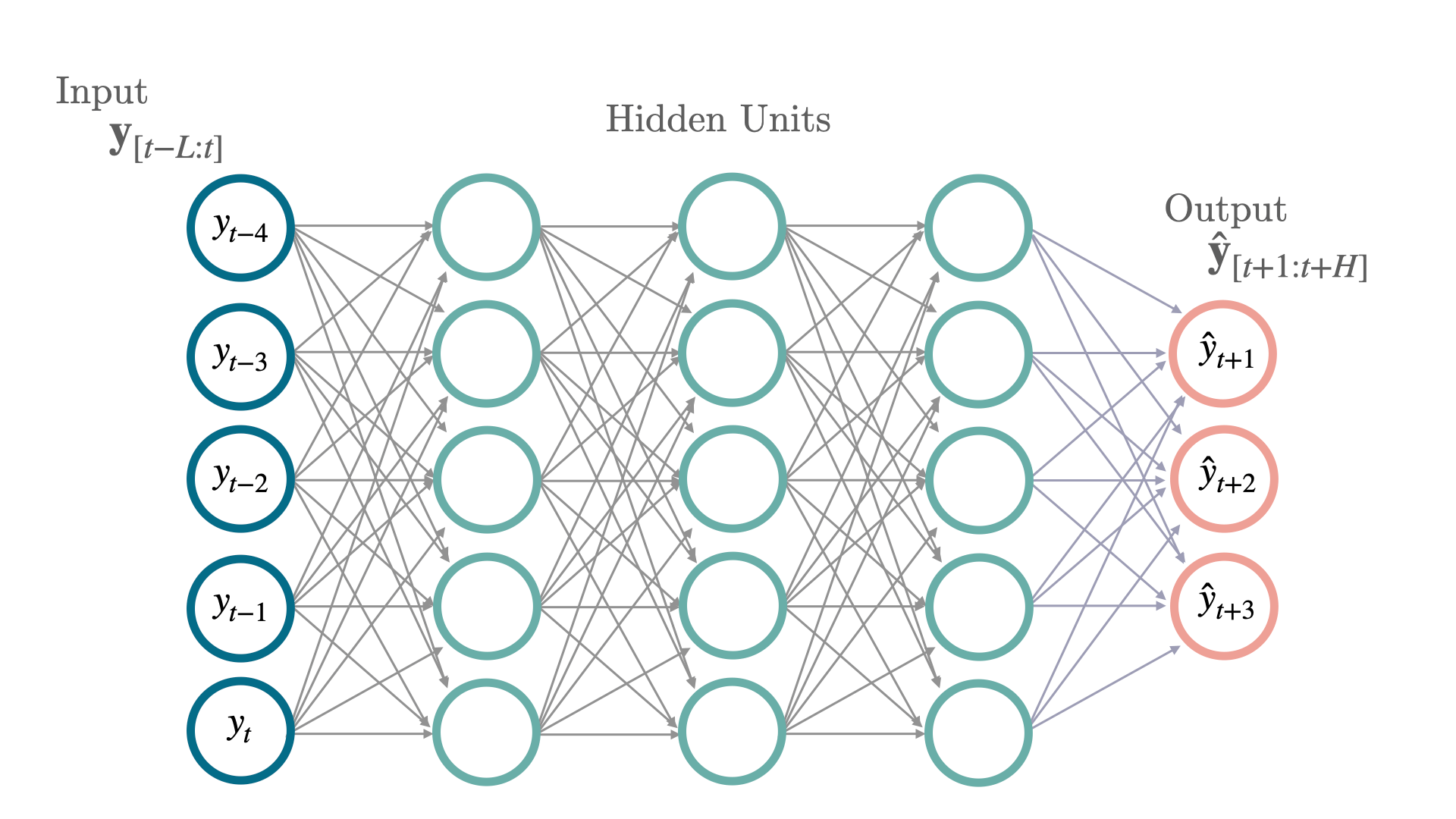
Como Prever Séries Temporais Com Redes Neurais em Python
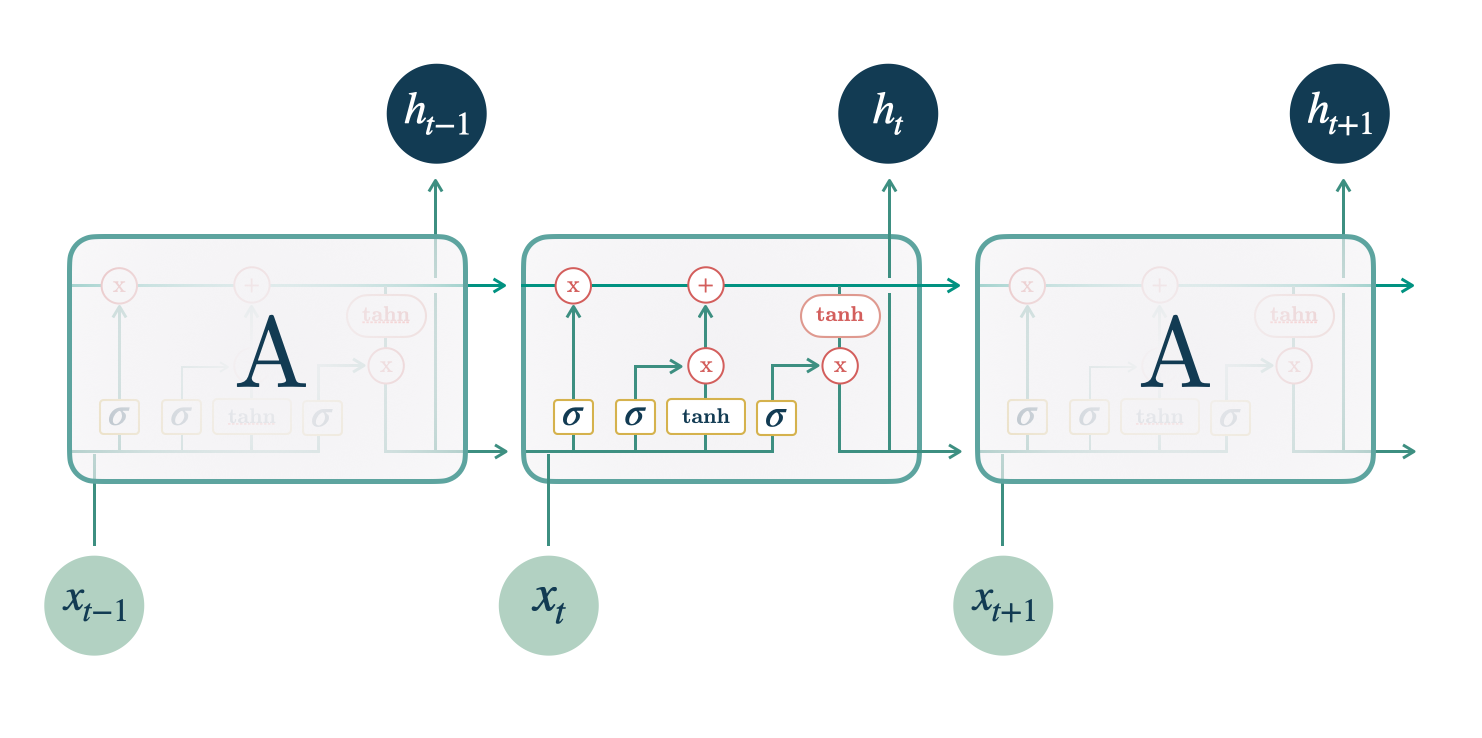
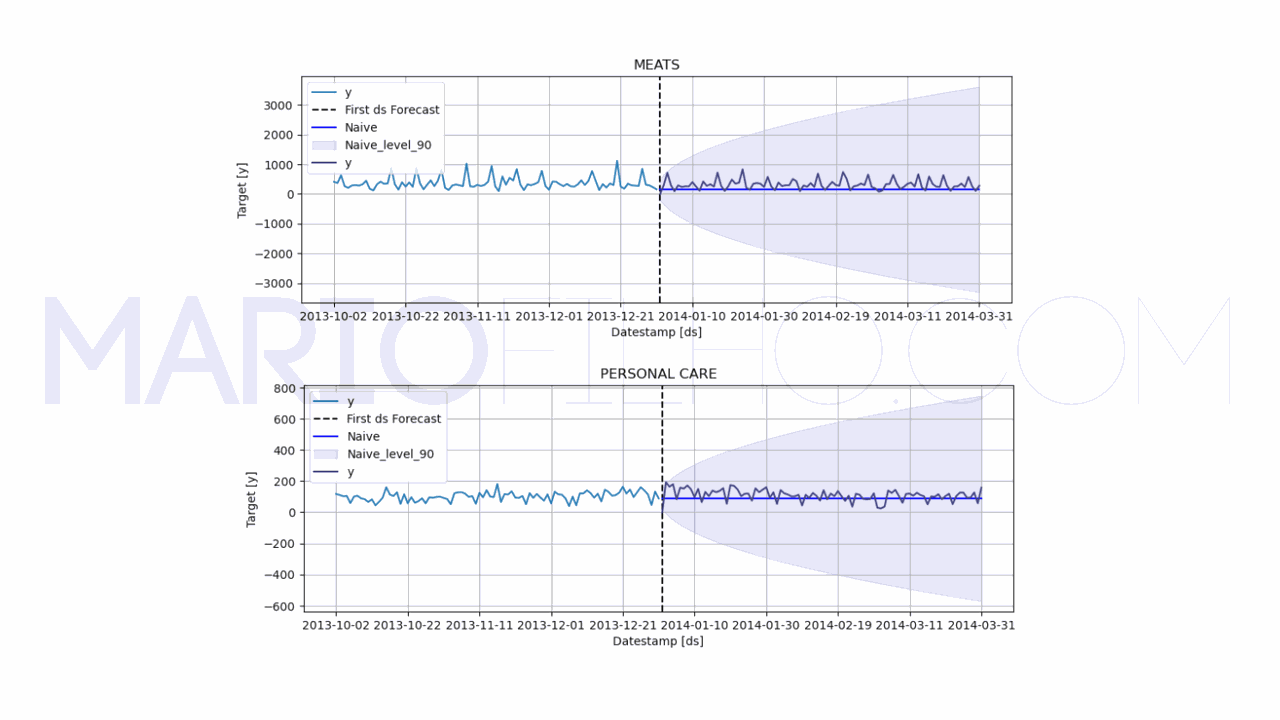
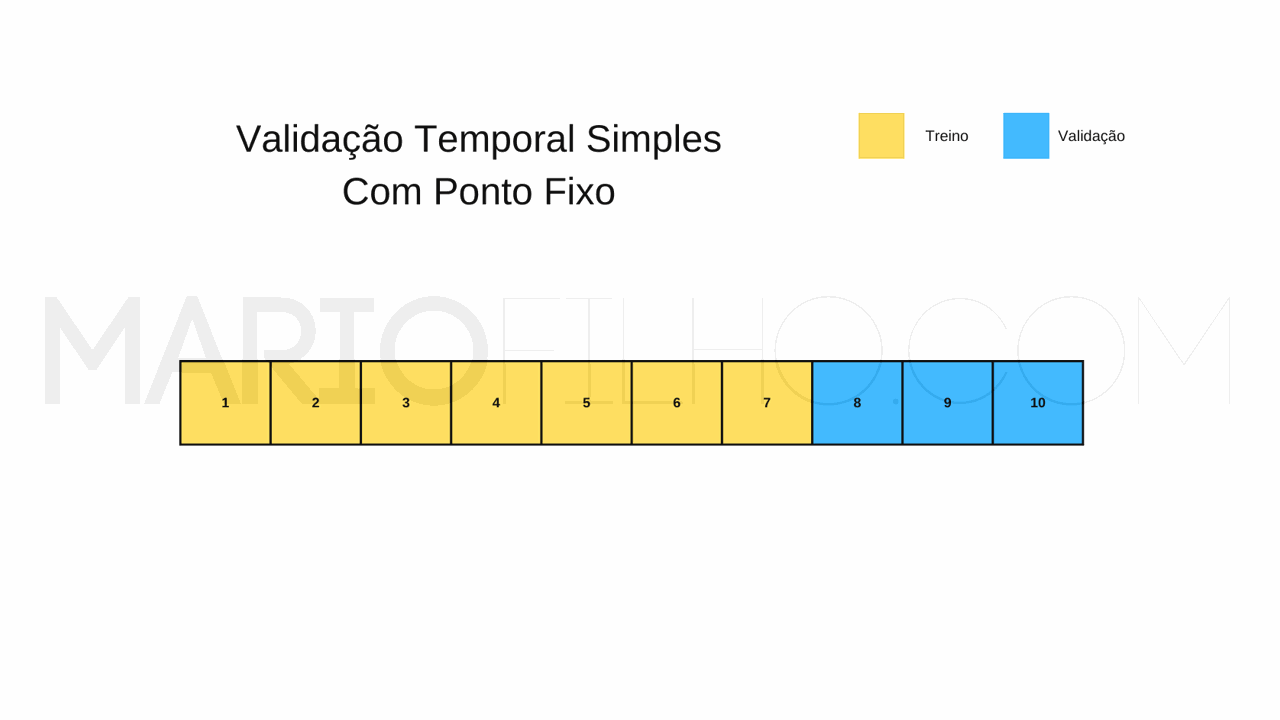
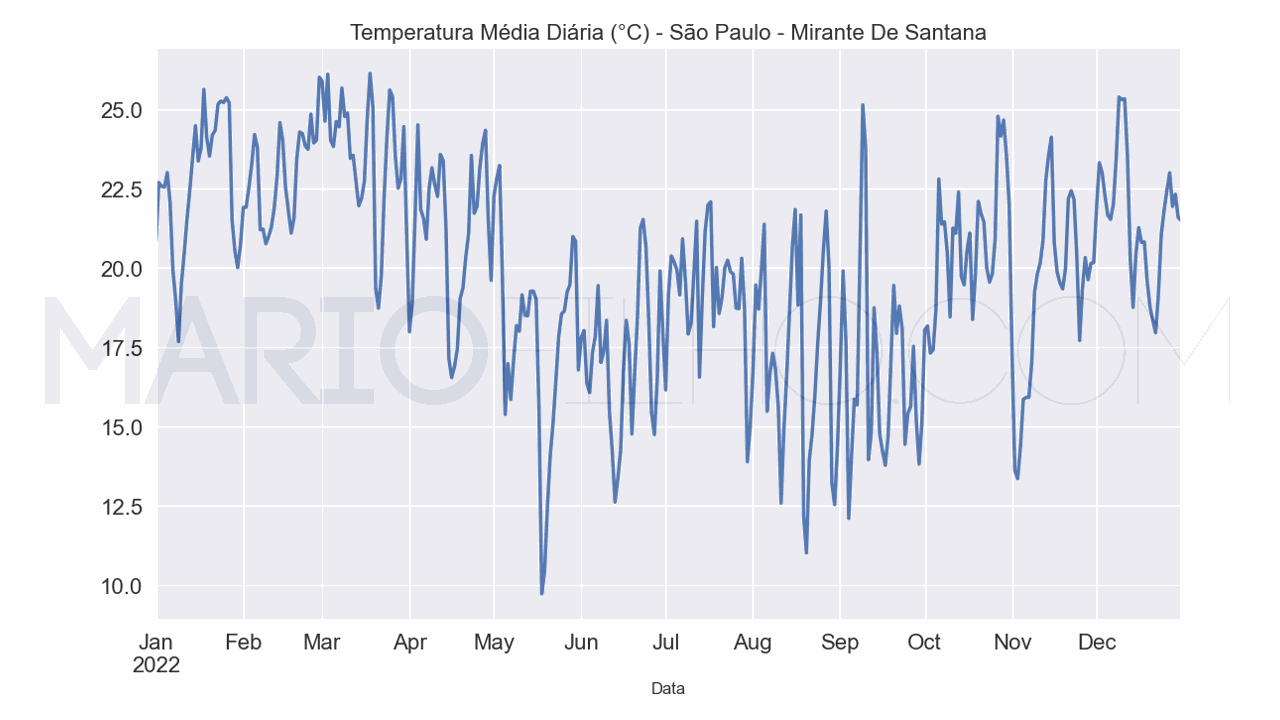
A modelagem de séries temporais com deep learning (redes neurais) é uma área em constante evolução. Falar de “redes neurais” pode se referir a vários tipos diferentes de técnicas como redes neurais convolucionais, redes neurais recorrentes, redes neurais tradicionais (MLP) e redes neurais com mecanismo de atenção (transformer). Por isso, primeiro vou te dar uma visão geral dessas técnicas, indicando artigos mais detalhados sobre cada uma e depois vou te mostrar como aplicar uma rede neural tradicional (MLP) para prever séries temporais....