
Em machine learning, frequentemente nos deparamos com conjuntos de dados onde o número de observações em uma classe é significativamente maior do que na outra.
Isso é conhecido como dados desbalanceados.
Por exemplo, em um conjunto de dados de transações de cartão de crédito, o número de transações fraudulentas (classe positiva) é geralmente muito menor do que o número de transações legítimas (classe negativa).
Este também é um exemplo de uma tarefa de classificação binária, que é um tipo comum de problema de machine learning.
Ao lidar com dados desbalanceados em classificação binária, o modelo pode se tornar enviesado em direção à classe majoritária, levando a um desempenho ruim na classe minoritária.
Se você tiver uma transação fraudulenta e 99 transações legítimas, um modelo que prevê qualquer transação como legítima terá uma acurácia de 99%.
No entanto, esse modelo é inútil porque nunca prevê uma transação fraudulenta, que é a que nos interessa.
XGBoost é uma poderosa biblioteca de gradient-boosting que nos oferece uma maneira simples de lidar com dados desbalanceados através do parâmetro scale_pos_weight.
Não se deixe enganar pela simplicidade desta abordagem: na minha experiência, ela NUNCA foi superada por métodos mais complexos como SMOTE.
Confie em mim, eu testei muitos métodos e o scale_pos_weight sempre superou todos eles.
Você pode usar essa abordagem para classificação multiclasse também.
Continue lendo para aprender como usar essa poderosa abordagem para lidar com dados desbalanceados em seus modelos XGBoost.
Carregando o Conjunto de Dados Desbalanceados
Vamos começar carregando o conjunto de dados Red Wine Quality da UCI.
Este é um conjunto de dados popular que usaremos ao longo deste tutorial.
Ele contém 11 features medindo diferentes propriedades químicas do vinho tinto, e a variável alvo é a qualidade do vinho, que é uma pontuação entre 3 e 8.
Não tem variáveis categóricas, então não precisamos nos preocupar em codificá-las.
Vamos binarizar a variável alvo para criar uma tarefa de classificação binária.
Cada vinho com uma pontuação de qualidade de 7 ou mais receberá um valor de 1, e o restante receberá um valor de 0.
Primeiro, precisamos importar as bibliotecas necessárias e carregar o conjunto de dados:
import pandas as pd
from sklearn.model_selection import train_test_split
# Carrega o conjunto de dados
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
data = pd.read_csv(url, sep=";")
# Binariza a variável alvo
data['quality'] = [1 if x >= 7 else 0 for x in data['quality']]
Em seguida, vamos dividir os dados em conjuntos de treinamento e teste:
# Divide os dados em conjuntos de treinamento e teste
X = data.drop('quality', axis=1)
y = data['quality']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Agora, vamos verificar a distribuição das classes em nosso conjunto de treinamento:
# Verifica a distribuição das classes
y_train.value_counts()
0 1109
1 170
Note que o número de observações em uma classe é significativamente maior do que na outra, indicando que temos um conjunto de dados desbalanceado.
Minha “regra de ouro” é começar a me preocupar com dados desbalanceados quando pelo menos 80% das observações estão em uma classe.
Neste caso, temos 87,5% das observações em uma classe, então precisamos lidar com esse desequilíbrio.
Usando scale_pos_weight (class_weight) Para Lidar com Dados Desbalanceados
Ao lidar com dados desbalanceados, uma abordagem comum é atribuir uma penalidade maior às classificações incorretas da classe minoritária.
Isso pode ser feito usando o parâmetro scale_pos_weight no XGBoost.
Pense no valor de scale_pos_weight como um multiplicador para a função de perda avaliada na classe positiva.
Por padrão, ele é definido como 1, significando que as duas classes têm o mesmo peso.
Se o definirmos como um valor maior que 1, o modelo dará mais importância à classe positiva, pois será mais penalizado por classificar incorretamente esta classe.
A maneira sugerida de definir o valor de scale_pos_weight é dividindo o número de amostras negativas pelo número de positivas.
Vamos calcular essa proporção para nosso conjunto de treinamento:
# Calcula a proporção da classe negativa para a classe positiva
ratio = float(y_train.value_counts()[0]) / y_train.value_counts()[1]
# 6.523529411764706
Agora, podemos usar essa proporção como o valor de scale_pos_weight ao treinar nosso modelo XGBoost.
Neste caso, cada erro de amostra positiva que o modelo cometer custará 6,52 vezes um erro de amostra negativa.
Isso ajudará o modelo a prestar mais atenção à classe minoritária durante o treinamento, potencialmente melhorando seu desempenho nesta classe.
Como eu disse antes, embora simples, é a abordagem mais poderosa que já usei para lidar com dados desbalanceados em qualquer modelo de machine learning.
Eu até perguntei a outros colegas experientes sobre isso, e eles compartilharam a mesma opinião.
Na próxima seção, treinaremos um modelo XGBoost usando este valor de scale_pos_weight.
Treinamento do Modelo XGBoost Classifier com scale_pos_weight
Primeiro, precisamos importar a biblioteca XGBoost:
import xgboost as xgb
Em seguida, criaremos uma instância do classificador XGBoost, passando nosso valor de scale_pos_weight:
# Cria um classificador XGBoost com o valor de scale_pos_weight
model = xgb.XGBClassifier(scale_pos_weight=ratio)
Agora, podemos treinar o modelo com nossos dados de treinamento:
# Treina o modelo com os dados de treinamento
model.fit(X_train, y_train)
E isso é tudo!
Treinamos um modelo XGBoost em dados desbalanceados, usando o parâmetro scale_pos_weight para dar mais importância à classe minoritária.
Vamos ver como ele se sai no conjunto de teste.
Avaliando o Modelo
Após treinar nosso modelo, é importante avaliar seu desempenho.
Usaremos duas métricas para isso: ROC-AUC (Área Sob a Curva ROC) e pontuação F1.
Você pode estar se perguntando: por que não usar log loss?
Eu não gosto de log loss quando uso pesos diferentes para as classes, pois não é adequado para o problema: se você precisa de probabilidades calibradas, não faz sentido forçar o modelo a prever a classe minoritária com mais frequência, que é o que o parâmetro scale_pos_weight faz.
ROC AUC é uma métrica de avaliação comum para problemas de classificação binária.
Ela mede a capacidade do modelo de atribuir uma pontuação maior a exemplos positivos do que a exemplos negativos.
Um classificador perfeito terá uma pontuação ROC AUC de 1, enquanto um classificador aleatório terá uma pontuação ROC AUC de 0,5.
A pontuação F1 é a média harmônica entre precisão e recall. É uma boa métrica para usar quando as classes estão desbalanceadas.
Eu não gosto de otimizar diretamente a pontuação F1, pois precisamos definir um ponto de corte para converter as pontuações previstas em rótulos de classe antes de calculá-la.
Recomendo que você desenvolva seu modelo otimizando a pontuação ROC AUC no conjunto de validação e, após maximizá-la, você escolha o ponto de corte que maximiza a pontuação F1.
Vamos ver como calcular essas métricas para nosso modelo.
Primeiro, precisamos importar as funções necessárias de sklearn.metrics:
from sklearn.metrics import roc_auc_score, f1_score
Em seguida, faremos previsões no conjunto de teste e calcularemos as métricas:
# Faz previsões no conjunto de teste
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1]
# Calcula AUC
auc = roc_auc_score(y_test, y_pred_proba)
print(f"AUC: {auc}")
# Calcula a pontuação F1
f1 = f1_score(y_test, y_pred)
print(f"Pontuação F1: {f1}")
model.predict(X_test) retorna os rótulos de classe previstos com um ponto de corte de 0,5, enquanto model.predict_proba(X_test) retorna as “probabilidades” previstas.
Como você pode ver, pegamos apenas a coluna correspondente à classe positiva ao calcular a pontuação ROC AUC.
Lembre-se, o objetivo não é apenas maximizar a precisão, mas também garantir que o modelo tenha um bom desempenho na classe minoritária, que geralmente é a classe de interesse em conjuntos de dados desbalanceados.
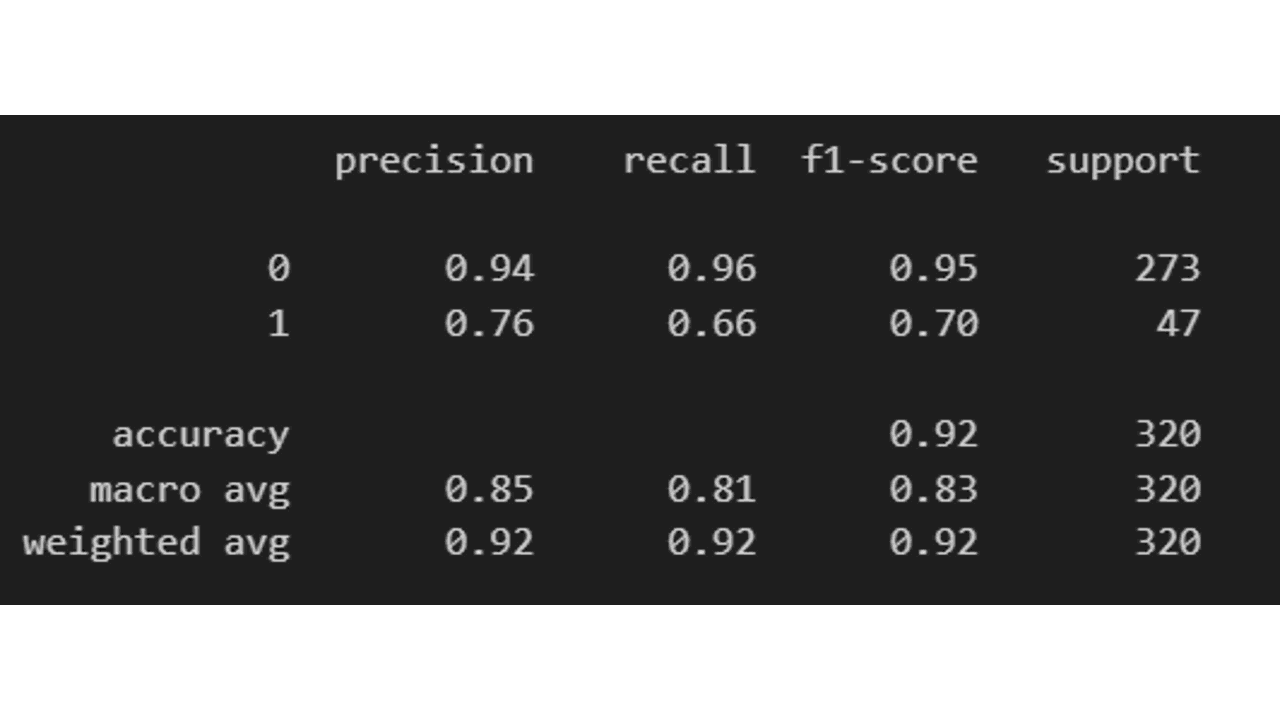
Outra função muito útil do scikit-learn é o classification_report, que nos dá um resumo das métricas de classificação mais importantes:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
Para otimizar o ponto de corte para maximizar a pontuação F1, podemos usar um loop para iterar sobre diferentes valores e escolher o que maximiza a pontuação F1.
for th in range(1,11,1):
th = th / 10
y_pred = (y_pred_proba > th).astype(int)
f1 = f1_score(y_test, y_pred)
print(f"Limiar: {th} - F1: {f1}")
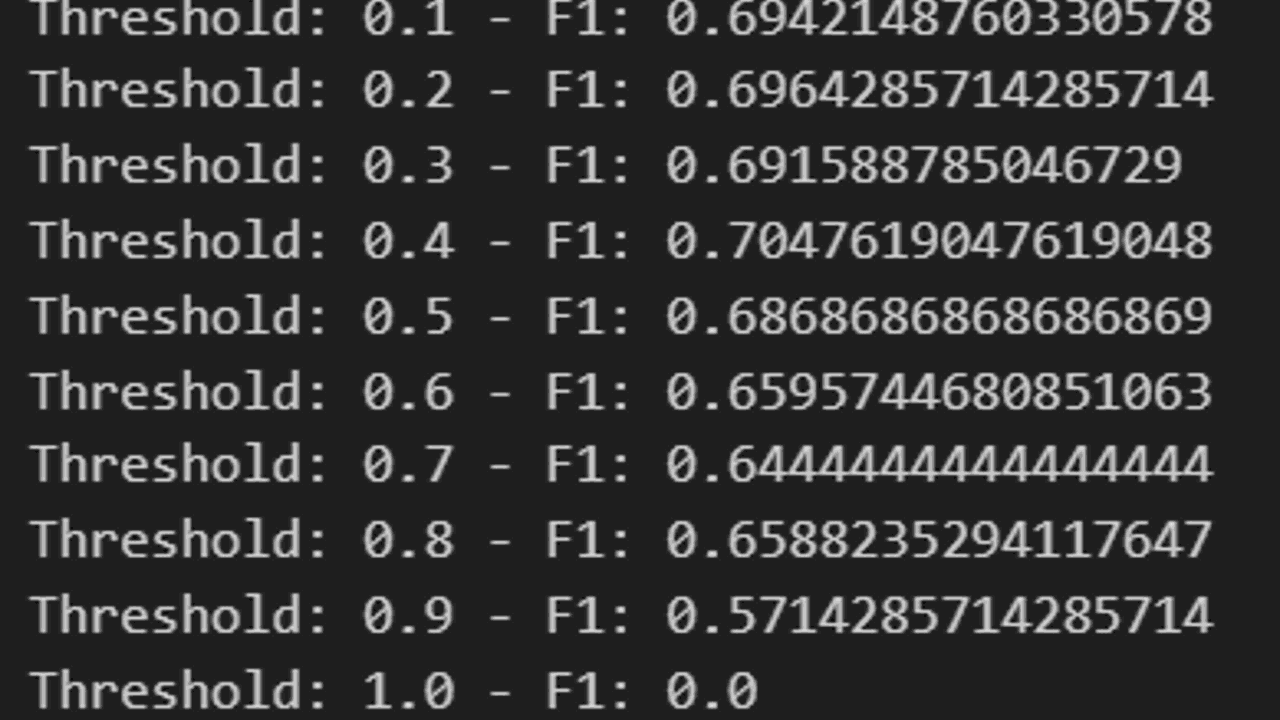
Aqui, iteramos sobre uma série de valores de 0,1 a 1 e, para cada valor, convertemos as probabilidades previstas em rótulos de classe usando esse limiar.
Em seguida, calculamos a pontuação F1 para os rótulos previstos e a imprimimos.
Você pode fazer o mesmo para outras métricas com limiar, como precisão e recall, e escolher o limiar que maximiza a métrica que mais lhe interessa.
Apenas não exagere na granularidade do intervalo, pois isso pode causar overfitting no conjunto de teste.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.