Classificação multiclasse é uma tarefa de machine learning onde o resultado pode pertencer a mais de duas classes ou categorias.
Por exemplo, uma fruta pode ser classificada como ‘maçã’, ‘banana’ ou ‘cereja’. Ou um carro pode ser classificado como ‘sedan’, ‘SUV’ ou ‘caminhonete’.
Assim como na classificação binária, podemos usar uma variedade de algoritmos para classificar os pontos de dados nessas múltiplas categorias.
Esses algoritmos incluem regressão logística, árvores de decisão, random forests, SVMs e algoritmos de gradient boosting como XGBoost.
XGBoost, abreviação de eXtreme Gradient Boosting, é um algoritmo popular de machine learning no campo de dados estruturados ou tabulares.
Nas próximas seções, veremos como usar o XGBoost para classificação multiclasse em Python.
Usaremos o “Red Wine Dataset”.
Ele contém 11 features que descrevem as propriedades químicas de diferentes vinhos e uma pontuação de qualidade, que vai de 3 a 8, para cada um.
Vamos começar!
Instalando XGBoost em Python
Antes de começarmos a usar o XGBoost, precisamos instalá-lo.
O XGBoost pode ser instalado usando o pip, que é um gerenciador de pacotes para Python.
Para instalá-lo, você pode usar o seguinte comando no seu terminal:
pip install xgboost
Se você estiver usando um notebook Jupyter, pode executar este comando em uma célula de código prefixando-o com um ponto de exclamação:
!pip install xgboost
Você também pode fazer isso usando conda e mamba:
conda install -c conda-forge xgboost
mamba install -c conda-forge xgboost
Depois de executar este comando, o XGBoost deve estar instalado e pronto para uso.
Você pode verificar se está instalado corretamente importando-o em seu script Python:
import xgboost as xgb
Se este comando for executado sem erros, parabéns! O XGBoost está instalado corretamente.
Agora, vamos passar para a próxima seção, onde discutiremos as funções objetivo para classificação multiclasse.
Funções Objetivo (Perda) para Classificação Multiclasse
Em machine learning, a função objetivo, também conhecida como função de perda, é usada para medir a diferença entre os resultados previstos e reais.
Ela guia o modelo no caminho que deve seguir durante o treinamento para alcançar a solução ótima.
Às vezes, é a mesma que a métrica de avaliação, mas não precisa ser.
Para classificação multiclasse, o XGBoost fornece duas funções objetivo:
multi:softmax
Quando você usa multi:softmax, está dizendo ao algoritmo que há mais de duas classes para classificar os dados.
Ao usar a API do scikit-learn (como faremos aqui), você não precisa especificar o número de classes como argumento, mas deve garantir que suas classes comecem de 0 e vão até o número de classes menos 1.
Isso ficará mais claro no exemplo de código abaixo.
Esta função objetivo retorna apenas a classe com a maior probabilidade, em vez da probabilidade de cada classe.
multi:softprob
A multi:softprob é outra função objetivo no XGBoost, também usada para problemas de classificação multiclasse.
A diferença é que, em vez de fornecer apenas a classe final como saída, multi:softprob fornece a probabilidade dos dados pertencerem a cada classe.
Então, para o nosso exemplo de frutas, multi:softprob daria as probabilidades de ser uma maçã, banana ou cereja.
Isso é útil quando você quer saber não apenas a decisão final, mas também o quão confiante o algoritmo está em sua decisão.
Em caso de dúvida, use multi:softprob, pois fornece tudo o que multi:softmax oferece e mais.
Carregando os Dados
Para carregar os dados, usaremos a biblioteca pandas, que é uma poderosa biblioteca de manipulação de dados em Python.
Se você não a tem instalada, pode fazê-lo usando o pip:
pip install pandas
Agora, vamos carregar o conjunto de dados de vinhos tintos.
O conjunto de dados está disponível como um arquivo CSV no Kaggle.
Usaremos a função read_csv() do pandas para carregar os dados em um DataFrame.
import pandas as pd
# Carregar os dados
dados = pd.read_csv('winequality-red.csv')
# Exibir as primeiras linhas dos dados
dados.head()
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 7.4 | 0.7 | 0 | 1.9 | 0.076 | 11 | 34 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 7.8 | 0.88 | 0 | 2.6 | 0.098 | 25 | 67 | 0.9968 | 3.2 | 0.68 | 9.8 | 5 |
| 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15 | 54 | 0.997 | 3.26 | 0.65 | 9.8 | 5 |
| 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17 | 60 | 0.998 | 3.16 | 0.58 | 9.8 | 6 |
| 7.4 | 0.7 | 0 | 1.9 | 0.076 | 11 | 34 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
A função head() é usada para obter as primeiras n linhas. Por padrão, retorna as primeiras 5 linhas do DataFrame.
Agora que carregamos nossos dados, podemos passar para o treinamento do nosso modelo XGBoost.
Treinando XGBoost com a API do Scikit-Learn
O XGBoost se integra perfeitamente com a biblioteca Scikit-Learn, que fornece uma API consistente para muitos algoritmos diferentes de machine learning em Python.
Antes de começarmos o treinamento, precisamos preparar nossos dados.
Vamos separar nossa variável alvo (quality) do resto do conjunto de dados e dividir os dados em conjuntos de treinamento e teste.
A coluna quality original contém valores de 3 a 8, então precisamos subtrair o valor mínimo desta coluna para fazê-la começar de 0.
from sklearn.model_selection import train_test_split
# Separar variável alvo
X = dados.drop('quality', axis=1)
y = dados['quality'] - dados['quality'].min()
# Dividir os dados em conjuntos de treinamento e teste
X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, test_size=0.2, random_state=42)
Agora, vamos treinar nosso modelo XGBoost.
Usaremos a classe XGBClassifier da biblioteca XGBoost.
from xgboost import XGBClassifier
modelo = XGBClassifier(objective='multi:softprob')
modelo.fit(X_treino, y_treino)
Se você já usou Scikit-Learn antes, este código deve parecer familiar.
A função fit() treina o modelo nos dados de treinamento.
Passamos as features (X_treino) e o alvo (y_treino) como parâmetros para esta função.
Agora que nosso modelo está treinado, podemos usá-lo para fazer previsões.
Fazendo Previsões
Existem duas maneiras básicas de fazer previsões usando XGBoost para classificação.
Previsões de Classe
Se você quiser prever diretamente a classe mais provável de uma instância, pode usar a função predict().
# Fazer previsões de classe
y_pred = modelo.predict(X_teste)
array([2, 2, 2, 2, 3, 2, 2, 2, 3, 3, 4, 2, 3, 2,... ])
Neste caso, o modelo retornará a classe com a maior probabilidade para cada instância.
Cada elemento no array de previsões corresponde a uma instância (linha) no conjunto de teste.
Prevendo Probabilidades
Na maioria das vezes, queremos saber as probabilidades de uma instância pertencer a cada classe, para entendermos o quão confiante o modelo está em suas previsões.
Ter a classe mais provável prevista com 90% de confiança é muito diferente de tê-la prevista com 51%.
A função predict_proba() retorna as probabilidades para cada classe.
# Prever probabilidades
y_pred_proba = modelo.predict_proba(X_teste)
array([[3.8726095e-05, 1.6520983e-04, 8.5571223e-01, 1.4203377e-01,
1.9999363e-03, 5.0116490e-05],
[7.2868759e-05, 7.5193483e-04, 9.8880708e-01, 1.0272802e-02,
3.8626931e-05, 5.6695393e-05],
...])
Da esquerda para a direita, as colunas representam as probabilidades da instância pertencer a cada classe.
Como esperado, cada linha soma 1.
Na próxima seção, avaliaremos o desempenho do nosso modelo.
Isso nos dará uma ideia de quão bem nosso modelo está se saindo.
Avaliando o Desempenho do Modelo
Avaliar o desempenho de um modelo é uma etapa crucial em machine learning.
Isso nos ajuda a entender o quão bem nosso modelo está se saindo e onde pode ser melhorado.
Vamos ver algumas maneiras de fazer isso.
Função score
Esta é a maneira mais simples de obter uma avaliação do seu modelo em um conjunto de dados.
No XGBoost, ela retorna a acurácia média nos dados de teste e rótulos fornecidos.
# Calcular acurácia
acuracia = modelo.score(X_teste, y_teste)
print("Acurácia: %.2f%%" % (acuracia * 100.0))
Usando Métricas de Avaliação do Scikit-learn
O Scikit-learn fornece várias funções para calcular métricas como precisão, recall, F1-score e Log Loss.
Para usar o Log Loss, precisamos obter as probabilidades para cada classe.
from sklearn.metrics import log_loss
# Calcular log loss
log_loss(y_teste, y_pred_proba)
A função classification_report() imprime a precisão, recall, pontuação F1 e suporte para cada classe.
Para esta função, precisamos passar as previsões de classe, não as probabilidades.
from sklearn.metrics import classification_report
# Imprimir relatório de classificação
print(classification_report(y_teste, y_pred))
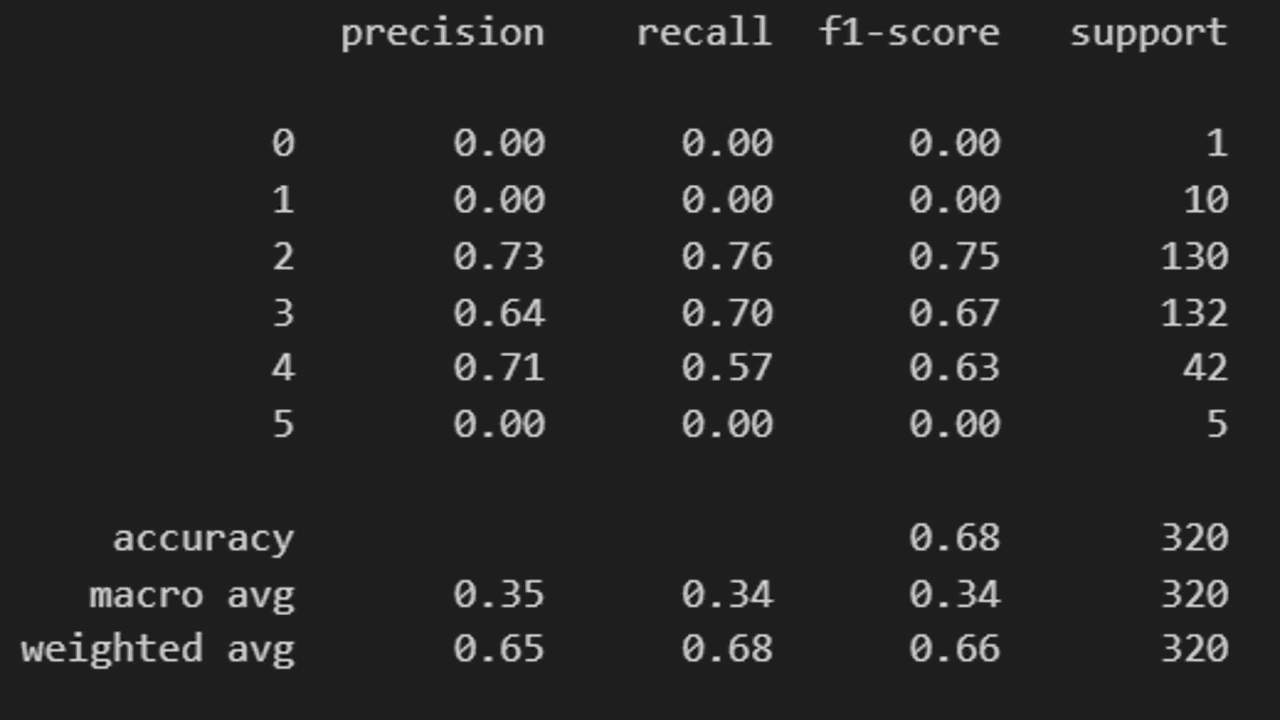
Lembre-se, nenhuma métrica isolada é suficiente para avaliar o desempenho de um modelo.
É importante olhar para múltiplas métricas e entender o que elas significam no contexto do seu problema específico.
Importância das Features por Permutação
Após treinar um modelo, é útil entender a contribuição de cada variável na criação das previsões.
Isso pode nos ajudar a obter insights sobre o problema e potencialmente simplificar o modelo removendo features irrelevantes.
O XGBoost fornece métodos internos para calcular a importância das features, que são baseados em fatores como o número de vezes que uma feature é usada para dividir os dados dentro das árvores de decisão e o ganho médio das divisões.
No entanto, este método tem algumas limitações, especialmente para dados com features correlacionadas.
Uma abordagem alternativa é usar a importância das features por permutação, que é uma técnica que pode ser aplicada a qualquer modelo de machine learning.
A ideia básica por trás da importância das features por permutação é medir o aumento no erro de previsão do modelo após permutar (embaralhar) os valores de uma feature em um conjunto de dados não visto.
Se uma feature é importante, embaralhar seus valores deve aumentar significativamente o erro do modelo.
Por outro lado, se uma feature não é importante, embaralhar seus valores deve ter pouco ou nenhum efeito no erro do modelo.
Vamos calcular a importância das features por permutação para nosso modelo XGBoost:
from sklearn.inspection import permutation_importance
# Calcular a importância das features por permutação
resultado = permutation_importance(
modelo, X_teste, y_teste, scoring='neg_log_loss', n_repeats=10, random_state=42
)
# Obter as importâncias das features e ordená-las em ordem decrescente
importancias = pd.Series(resultado.importances_mean, index=X.columns).sort_values(ascending=False)
# Imprimir as importâncias das features
print(importancias)
| Feature | Importance |
|---|---|
| alcohol | 0.377121 |
| sulphates | 0.280283 |
| volatile acidity | 0.188259 |
| total sulfur dioxide | 0.152310 |
| residual sugar | 0.051633 |
| citric acid | 0.049829 |
| pH | 0.049466 |
| fixed acidity | 0.043403 |
| density | 0.041544 |
| chlorides | 0.021090 |
| free sulfur dioxide | -0.012878 |
A função permutation_importance do scikit-learn recebe os seguintes parâmetros:
modelo: O modelo treinado para o qual queremos calcular a importância das features.X_teste: A matriz de features para o conjunto não visto (validação).y_teste: A variável alvo para o conjunto não visto (validação).scoring: A métrica a ser usada para medir o aumento no erro de previsão. Estamos usando'neg_log_loss'para classificação multiclasse.n_repeats: O número de vezes para permutar cada feature. Mais repetições levam a resultados mais estáveis, mas demoram mais para calcular.random_state: A semente para o gerador de números aleatórios, para garantir reprodutibilidade.
A função retorna um objeto PermutationImportance, que contém a média e o desvio padrão do aumento no erro de previsão para cada feature.
Extraímos as importâncias médias usando resultado.importances_mean, criamos uma Series do pandas com os nomes das features como índice, ordenamos a Series em ordem decrescente e a imprimimos.
Isso nos dará uma lista ordenada de features, com as features mais importantes no topo e as menos importantes na parte inferior.
Interpretar a importância das features pode ser complicado, e é sempre uma boa ideia combiná-la com conhecimento do domínio e outras técnicas de análise exploratória de dados.
No entanto, pode ser uma ferramenta útil para entender o comportamento do seu modelo e potencialmente melhorar seu desempenho removendo ou diminuindo o peso de features irrelevantes.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.