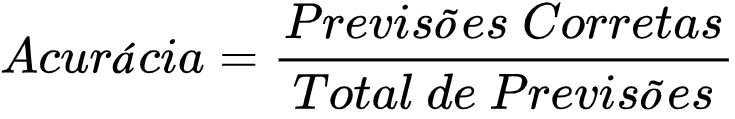

Acurácia é uma métrica de avaliação muito popular para descobrir a performance de um modelo de machine learning em uma tarefa de classificação.
Costumo pensar nela como “taxa de acerto” do modelo.
Ela é calculada dividindo o número de previsões corretas pelo número total de previsões.
Por exemplo, imagine que você treinou um modelo de machine learning para prever se uma pessoa tem uma doença ou não, com base em alguns sintomas.
Se o modelo faz 100 previsões e acerta 85 delas, sua acurácia é de 85%.
Ela é muito popular porque é uma métrica fácil de entender, mas como todas as métricas, existem alguns cuidados que você deve tomar ao usá-la.
Índice
- Qual a Fórmula da Acurácia?
- Como Calcular Acurácia na Matriz de Confusão
- Como Calcular Acurácia com Scikit-learn em Python
- Como Calcular Acurácia em R
- Como Calcular Acurácia com Tensorflow em Python
- Como Calcular Acurácia com PyTorch em Python
- Qual A Diferença Entre Precisão e Acurácia?
- Quais Cuidados Você Deve Ter Ao Usar Acurácia?
- Quais São As Métricas Alternativas À Acurácia?
- Como Saber Se a Acurácia Está Boa?
Qual a Fórmula da Acurácia?
A fórmula da acurácia é dada por:
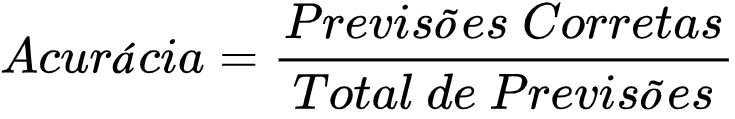
Você também pode pensar nela em termos da matriz de confusão como vou explicar abaixo:
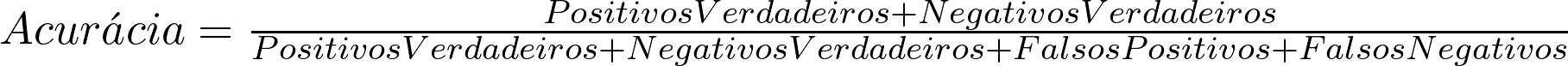
Como Calcular Acurácia na Matriz de Confusão
A matriz de confusão é uma ferramenta muito útil para visualizar o desempenho de um modelo de machine learning.
Ela mostra o número de previsões corretas e incorretas que o modelo fez para cada classe.
Imagine o problema acima onde você quer prever se uma pessoa terá ou não uma doença.
A matriz de confusão ficaria assim:
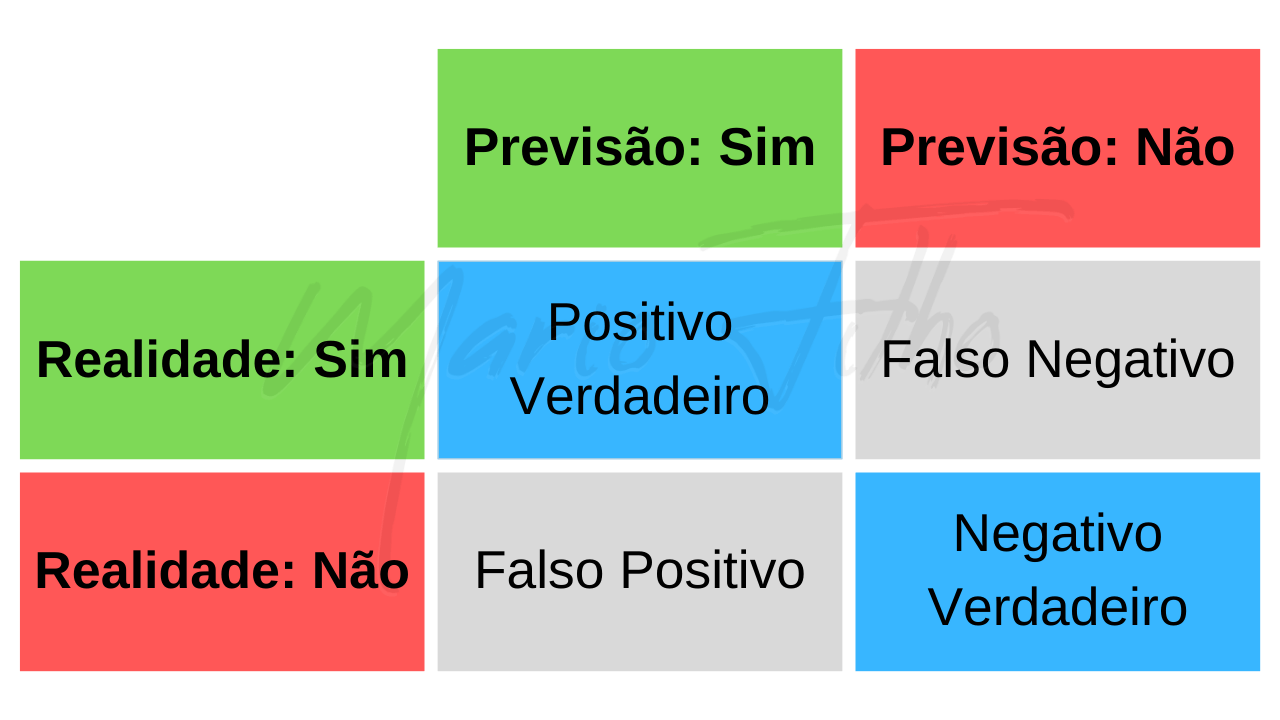
Em vez dos nomes das células, teríamos a quantidade de exemplos que se encaixa em cada uma das categorias.
Os acertos são a soma dos positivos e negativos verdadeiros. Exemplos em que a previsão do modelo corresponde ao que aconteceu na realidade.
Falsos positivos e negativos são os erros, exemplos nos quais as previsões do modelo são diferentes da realidade.
Para calcular a acurácia, basta somar os números da diagonal pintada de azul e dividir pela soma dos números de todas as células.
Como Calcular Acurácia com Scikit-learn em Python
O scikit-learn é a biblioteca mais popular de Python para machine learning.
Ela já tem uma função preparada para fazer o cálculo da acurácia: accuracy_score:
from sklearn.metrics import accuracy_score
# Suponha que você tenha um modelo de classificação chamado "model"
# Faça as previsões usando o modelo
predictions = model.predict(X_test)
# Calcule a acurácia
accuracy = accuracy_score(y_test, predictions)
print("Acurácia:", accuracy)
O y_test pode ser uma série do Pandas, uma array do Numpy ou até uma lista do Python. Esta variavel contém as respostas verdadeiras para cada exemplo do X_test.
Ou seja, se você tem 100 exemplos, fará 100 previsões e precisará de 100 elementos no y_test para calcular a acurácia.
A função accuracy_score faz os cálculos que demonstrei acima e retorna a acurácia como um valor entre 0 e 1.
Como Calcular Acurácia em R
Caso você precise calcular a acurácia em R, é possível fazer através do pacote “caret”:
install.packages("caret")
library(caret)
# Suponha que você tenha um modelo de classificação chamado "model"
# Faça as previsões usando o modelo
predictions <- predict(model, X_test)
# Calcule a matriz de confusão
confusion_matrix <- caret::confusionMatrix(predictions, y_test)
# Imprima o valor da acurácia
print(confusion_matrix$overall[["Accuracy"]])
Como Calcular Acurácia com Tensorflow em Python
O TensorFlow é uma biblioteca super popular mais voltada para deep learning (redes neurais) com uma implementação muito boa em Python através da biblioteca Keras.
Na maior parte dos projetos você vai usar o scikit-learn para fazer os cálculos, mas é importante saber como fazê-lo em outras bibliotecas também.
Nenhuma das implementações é melhor ou pior do que a outra.
Para calcular a acurácia de um modelo usando TensorFlow, você pode usar a função tf.keras.metrics.Accuracy.
import tensorflow as tf
# Suponha que você tenha um modelo de classificação chamado "model"
# Faça as previsões usando o modelo
predictions = model.predict(X_test)
# Crie um objeto de métrica de acurácia
accuracy = tf.keras.metrics.Accuracy()
# Atualize a métrica com os rótulos verdadeiros e as previsões
accuracy.update_state(y_test, predictions)
# Imprima o valor da acurácia
print("Acurácia:", accuracy.result().numpy())
Novamente y_test contém os rótulos reais dos exemplos.
Desta vez essa variável também pode ser um Tensor do TensorFlow, que é uma estrutura de dados bem parecida com uma array do Numpy.
Esta função também retorna um valor entre 0 e 1.
Como Calcular Acurácia com PyTorch em Python
O Pytorch é uma biblioteca de deep learning que está ficando cada vez mais popular.
A forma mais fácil de calcular a acurácia de um modelo criado com PyTorch é usar a função accuracy_score do scikit-learn, igual demonstrado acima.
Qual A Diferença Entre Precisão e Acurácia?
Em machine learning, a precisão se refere ao número de exemplos que o modelo previu como sendo de uma classe e que realmente são, divididos pelo número total de exemplos previstos daquela classe.
Pensando no caso de classificação binária (apenas duas classes: positiva e negativa)
Em termos da matriz de confusão, a fórmula fica:
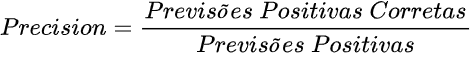
Já a acurácia trata da taxa de acertos total, incluindo acertos da classe negativa.
É importante lembrar que, às vezes, pode ser mais importante maximizar a precisão em uma classe específica (como spam) em vez da acurácia geral.
Vou te dar um exemplo abaixo.
Quais Cuidados Você Deve Ter Ao Usar Acurácia?
O maior problema da acurácia ocorre quando você tem dados desequilibrados ou desbalanceados.
Isso significa que você tem mais exemplos de uma classe do que das outras.
Vamos nos manter no exemplo de classificação binária de spam para ficar fácil de entender.
A maioria dos e-mails enviados todos os dias não é spam, o que significa que a porcentagem de spam comparada a e-mails normais em nossos dados tende a ser bem pequena (1% ou menos).
Se nós usarmos uma comparação simples, prevendo que NENHUM e-mail é spam, teremos uma acurácia de 99%.
Ou seja, todos os e-mails de spam vão passar por nosso filtro, tornando-o inútil, apesar da acurácia parecer alta.
Por isso é importante sempre considerar outras métricas de avaliação mais adequadas no caso de dados desbalanceados.
Em casos práticos, eu sempre uso mais de uma métrica (cerca de duas ou três) para cobrir mais de um aspecto da avaliação do modelo.
Quais São As Métricas Alternativas À Acurácia?
O F1 Score é uma métrica que leva em consideração tanto a precisão quanto o recall, enquanto a acurácia leva em consideração apenas o número de amostras corretamente classificadas em relação ao número total de amostras.
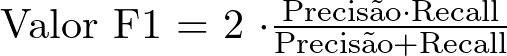
Isso significa que o F1 score pode ser mais útil do que a acurácia em situações em que classificar corretamente dados de uma classe é mais importante que das outras.
O recall ou taxa de detecção é a proporção de exemplos positivos que foram classificados corretamente pelo modelo.
Por exemplo, em um problema de detecção de spam, o recall se refere à proporção de e-mails de spam que foram classificados corretamente.
A precisão, como já explicado, se refere à proporção de amostras classificadas como positivas que realmente são positivas.
No exemplo de detecção de spam, a precisão se refere à proporção de e-mails classificados como spam que realmente são spam.
Em alguns problemas, é mais importante maximizar o recall, enquanto em outros problemas é mais importante maximizar a precisão.
O F1 score é útil porque é capaz de equilibrar esses dois fatores, sendo mais versátil e informativo do que a acurácia
Como Saber Se a Acurácia Está Boa?
O que é considerado uma acurácia “boa” varia de acordo com o problema que você está tentando resolver e com o contexto em que o modelo será usado.
Um modelo que prevê se Ibovespa vai subir amanhã pode ser ótimo com uma acurácia de 51%, enquanto um modelo que prevê quais e-mails são spam pode ser considerado ruim com uma acurácia de 99%.
A melhor maneira de descobrir quão bom é seu modelo, é compará-lo a soluções mais simples ou soluções que já existem para o problema.
Método Da Baseline Da Classe Mais Frequente
Compare a acurácia de seu modelo à previsão da classe mais frequente dos dados.
Esta é uma técnica simples em que você simplesmente prevê que todos os exemplos de validação pertencem à classe mais frequente no conjunto de treinamento.
Imagine que prever a classe mais frequente faça com que você acerte 60% dos exemplos.
Seu modelo precisará de uma acurácia maior do que essa para mostrar que ele está aprendendo algo útil dos dados e fazendo previsões melhores do que um modelo que não aprende nada.
Como Prever A Classe Mais Frequente Usando Scikit-learn?
Você pode usar o método DummyClassifier do scikit-learn para prever facilmente a classe mais frequente.
Aqui está um exemplo de como fazer isso:
from sklearn.dummy import DummyClassifier
from sklearn.metrics import accuracy_score
# Crie o classificador dummy que sempre preveja a classe mais frequente
dummy = DummyClassifier(strategy='most_frequent')
# Treine o classificador usando o conjunto de treinamento
dummy.fit(X_train, y_train)
# Faça previsões no conjunto de teste
y_pred = dummy.predict(X_test)
# Calcule a acurácia
print('Acurácia: {:.2f}'.format(accuracy_score(y_test, y_pred)))
Compare Com A Solução Atual
Se já existe uma solução implementada para o problema que você está tentando resolver, seja ela com machine learning ou não, você pode usá-la como uma baseline para comparar com o desempenho do seu modelo.
Dessa forma, você pode ver se ele supera a solução existente ou se está apenas capturando a performance já existente.
Implementar e manter modelos de machine learning são tarefas que exigem esforço e recursos, então não vale a pena implementar modelos que não tragam melhorias sobre a solução atual.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.