
A “importância de features” (feature importance) nos ajuda a identificar quais features nos seus dados são mais influentes quando se trata das previsões do seu modelo.
Compreender a importância das features pode ajudar você a interpretar seu modelo de forma mais eficaz.
Por exemplo:
- Você pode descobrir uma feature surpreendentemente importante que não esperava.
- Ou perceber que uma feature que você considerava crucial na verdade não está fazendo muita diferença.
Isso é mais importante ainda quando consideramos modelos complexos, como o XGBoost, já que estes modelos de alta performance tendem a ser mais difíceis de interpretar.
Neste tutorial, vamos explorar como implementar essa análise no seu código e como interpretar os resultados obtidos.
Como o XGBoost Calcula a Importância das Features?
O XGBoost oferece cinco tipos principais de importância: ‘weight’, ‘gain’, ‘cover’, ’total_gain’ e ’total_cover’.
Vamos examinar cada um deles:
Weight
Este é o tipo mais simples de importância de feature.
Ele representa o número de vezes que uma feature é usada para dividir os dados em todas as árvores.
Quanto mais splits usam uma feature, mais importante ela é considerada.
Gain
Este tipo é um pouco mais complexo.
O gain mede a melhoria média na perda (do conjunto de treinamento) proporcionada por uma feature.
Em outras palavras, ele indica o quanto uma feature contribui para reduzir o erro do modelo considerando todas as divisões em que a feature é usada.
Cover (Cobertura)
O cover mede o número de pontos de dados que uma determinada feature afeta.
Isso é calculado através da média dos valores hessian de todas as divisões em que a feature é utilizada.
Total_gain
Semelhante ao gain, mas em vez da média, ele fornece a melhoria total trazida por uma feature.
Total_cover
Similar ao cover, mas fornece o número total, em vez da média.
Quando devo usar cada tipo?
Infelizmente, não existe uma resposta única que se aplique a todos os casos.
Uma abordagem que costumo adotar é calcular todos os tipos e, em seguida, usar meu melhor julgamento para decidir qual é mais útil para o problema específico em questão.
Implementando a Importância das Features do XGBoost em Python
Para este exemplo, vamos utilizar o conjunto de dados Red Wine da UCI.
Este dataset contém informações sobre vários atributos de vinhos tintos, como ‘fixed acidity’, ‘volatile acidity’, ‘citric acid’, entre outros.
Nossa tarefa será prever a qualidade do vinho com base nesses atributos.
Primeiro, vamos importar as bibliotecas necessárias:
import pandas as pd
from xgboost import XGBRegressor
import matplotlib.pyplot as plt
Agora, vamos carregar nosso conjunto de dados:
df = pd.read_csv('winequality-red.csv', delimiter=';')
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 7.4 | 0.7 | 0 | 1.9 | 0.076 | 11 | 34 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 7.8 | 0.88 | 0 | 2.6 | 0.098 | 25 | 67 | 0.9968 | 3.2 | 0.68 | 9.8 | 5 |
| 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15 | 54 | 0.997 | 3.26 | 0.65 | 9.8 | 5 |
| 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17 | 60 | 0.998 | 3.16 | 0.58 | 9.8 | 6 |
| 7.4 | 0.7 | 0 | 1.9 | 0.076 | 11 | 34 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
O próximo passo é separar nossas features (X) da nossa variável alvo (y).
Neste caso, queremos prever a coluna ‘quality’:
X = df.drop('quality', axis=1)
y = df['quality']
Nota: Para manter este exemplo conciso, não estou dividindo os dados em conjuntos de treinamento e teste.
Em um cenário real, você deve fazer essa divisão antes de treinar seu modelo.
Agora, vamos criar e treinar nosso modelo XGBoost:
model = XGBRegressor()
model.fit(X, y)
Com o modelo treinado, podemos obter as importâncias das features.
A API sklearn do XGBoost torna isso fácil com o atributo feature_importances_:
importances = model.feature_importances_
feature_importance = pd.Series(importances, index=X.columns).sort_values(ascending=False)
print(feature_importance)
| 0 | |
|---|---|
| fixed acidity | 0.0356799 |
| density | 0.051082 |
| free sulfur dioxide | 0.0526365 |
| chlorides | 0.0537856 |
| residual sugar | 0.055074 |
| citric acid | 0.0559636 |
| pH | 0.0683643 |
| total sulfur dioxide | 0.0783635 |
| sulphates | 0.0954391 |
| volatile acidity | 0.0955693 |
| alcohol | 0.358042 |
Neste resultado, você verá que a feature ‘alcohol’ é a mais importante, sinalizada por seu valor de importância de 0,358042.
Por padrão, o XGBoost usa o tipo ‘gain’ de importância de feature.
Para mudar o tipo utilizado podemos alterar o parâmetro importance_type na inicialização do modelo:
model = XGBRegressor(importance_type='weight')
model.fit(X, y)
importances = model.feature_importances_
feature_importance = pd.Series(importances, index=X.columns).sort_values(ascending=False)
print(feature_importance)
| 0 | |
|---|---|
| free sulfur dioxide | 0.0671536 |
| alcohol | 0.0680961 |
| pH | 0.0713949 |
| citric acid | 0.0798775 |
| residual sugar | 0.0803487 |
| sulphates | 0.0838831 |
| density | 0.0933082 |
| total sulfur dioxide | 0.0937795 |
| chlorides | 0.0951932 |
| volatile acidity | 0.111216 |
| fixed acidity | 0.155749 |
Agora, você pode notar uma mudança na ordem das features importantes.
Por exemplo, ‘fixed acidity’ se tornou a feature mais importante.
É importante ter cuidado ao interpretar esses resultados, especialmente com o método ‘weight’.
Para features categóricas de alta cardinalidade, o método ‘weight’ pode ser tendencioso, já que essas features naturalmente têm mais divisões.
As Random Forests também sofrem desse problema.
Para usar o método ‘cover’, basta trocar o parâmetro importance_type para ‘cover’:
model = XGBRegressor(importance_type='cover')
| 0 | |
|---|---|
| fixed acidity | 0.0465268 |
| free sulfur dioxide | 0.0672191 |
| citric acid | 0.0774046 |
| volatile acidity | 0.0809456 |
| residual sugar | 0.0822461 |
| sulphates | 0.0887277 |
| total sulfur dioxide | 0.0980716 |
| chlorides | 0.0999913 |
| pH | 0.104945 |
| density | 0.125591 |
| alcohol | 0.128332 |
Enfim, coloquei todos os tipos de importância (média) numa tabela para facilitar a comparação:
| weight | gain | cover | |
|---|---|---|---|
| fixed acidity | 0.155749 | 0.0356799 | 0.0465268 |
| volatile acidity | 0.111216 | 0.0955693 | 0.0809456 |
| citric acid | 0.0798775 | 0.0559636 | 0.0774046 |
| residual sugar | 0.0803487 | 0.055074 | 0.0822461 |
| chlorides | 0.0951932 | 0.0537856 | 0.0999913 |
| free sulfur dioxide | 0.0671536 | 0.0526365 | 0.0672191 |
| total sulfur dioxide | 0.0937795 | 0.0783635 | 0.0980716 |
| density | 0.0933082 | 0.051082 | 0.125591 |
| pH | 0.0713949 | 0.0683643 | 0.104945 |
| sulphates | 0.0838831 | 0.0954391 | 0.0887277 |
| alcohol | 0.0680961 | 0.358042 | 0.128332 |
Visualizando a Importância das Features
Para tornar nossa análise mais intuitiva, vamos criar uma visualização das importâncias das features.
Um gráfico de barras é uma ótima maneira de fazer isso:
plt.figure(figsize=(10, 6))
feature_importance.plot(kind='bar')
plt.title('Importância das Features no XGBoost')
plt.xlabel('Features')
plt.ylabel('Importância')
plt.tight_layout()
plt.show()
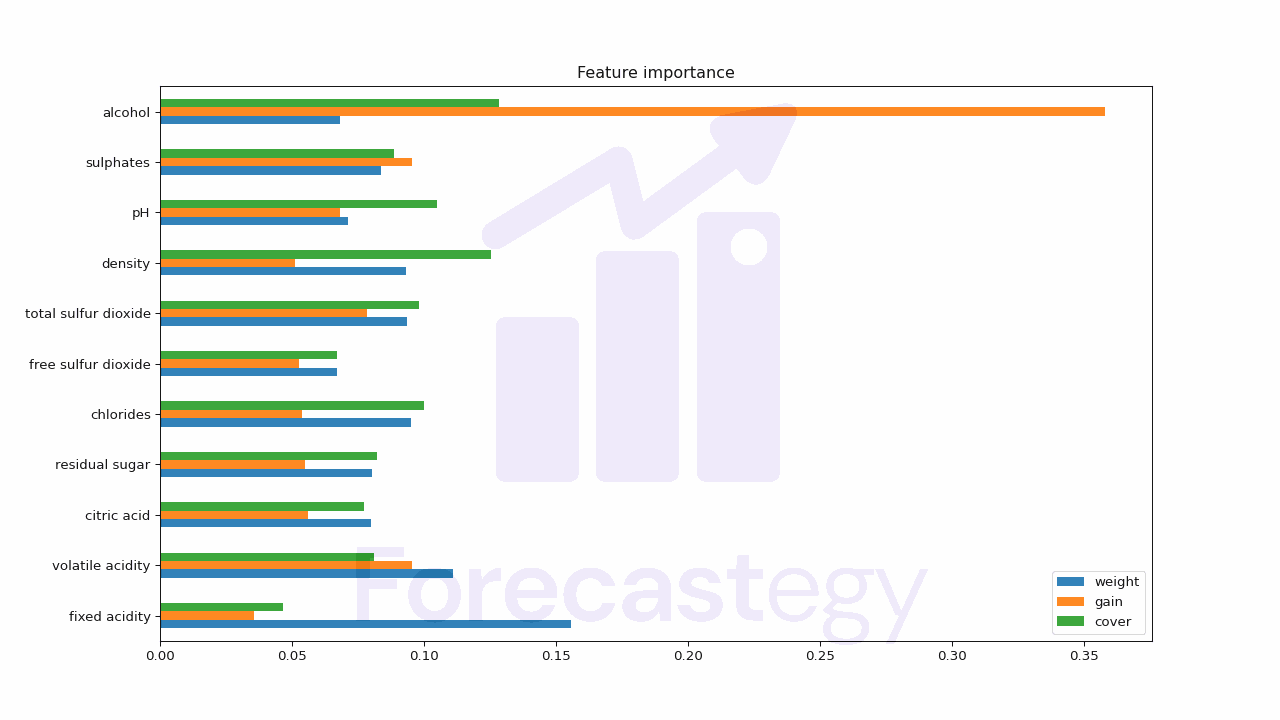
Este gráfico oferece uma representação visual clara da importância relativa de cada feature no nosso modelo.
É importante notar que, embora essas métricas de importância sejam muito úteis, elas têm suas limitações.
Por exemplo, elas não nos dizem a direção da relação entre a feature e a variável alvo - apenas a força dessa relação.
Portanto, não sabemos se uma feature está positiva ou negativamente correlacionada com a qualidade do vinho.
Apesar dessas limitações, a análise de importância das features continua sendo uma ferramenta valiosa para entender melhor nossos modelos de machine learning e os dados que estamos analisando.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.