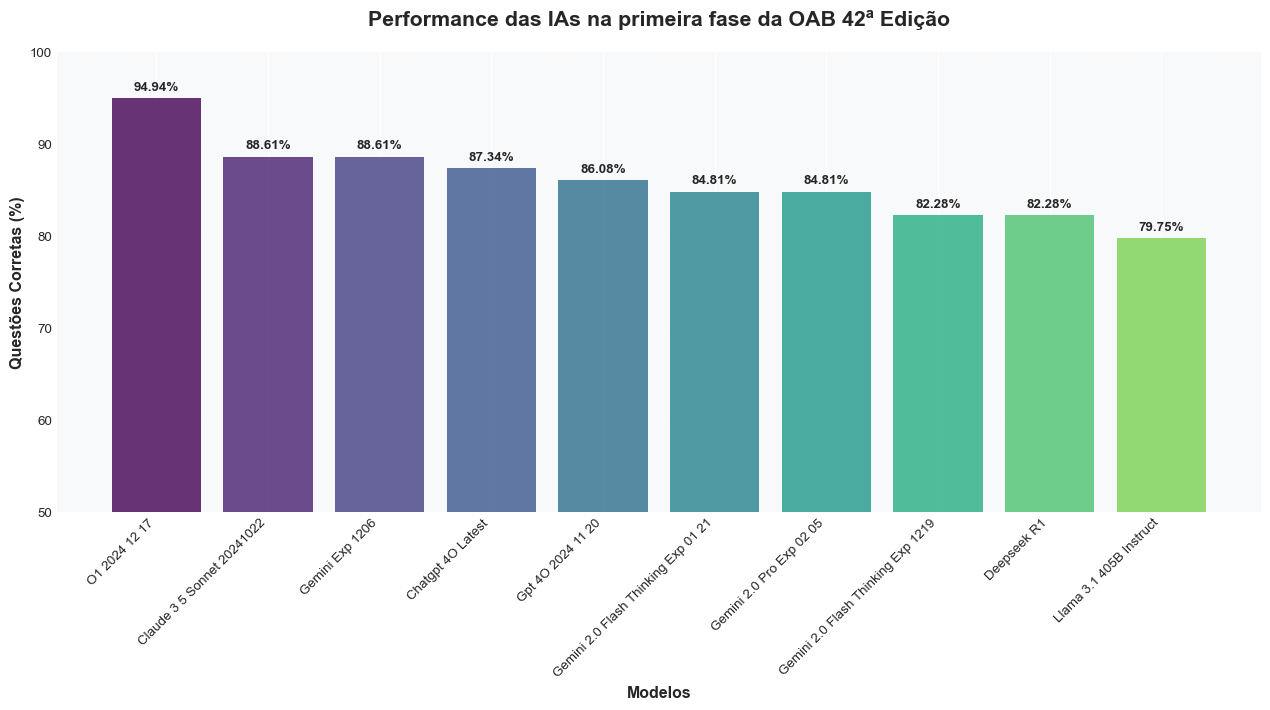
Resolvi testar os LLMs mais populares do momento no exame da primeira fase da OAB 42, que é a prova da Ordem dos Advogados do Brasil.
O exame foi aplicado em 1 de dezembro de 2024, então não está nos dados de treino dos modelos.
Lembrando que esses testes não têm rigor científico. São apenas curiosidades minhas depois de usar esses modelos para analisar alguns documentos legais na semana passada.
Isso também não significa que os LLMs podem substituir advogados.
Esse foi o prompt para todos os modelos:
“““Responda a seguinte questão, formate sua reposta como: “ALTERNATIVA: [sua resposta]”
{question}”””
Por que esse prompt simples?
-
Queria descobrir o quanto de conhecimento de direito brasileiro está “internalizado” nos modelos. Nenhum deles teve acesso à internet ou legislação.
-
Queria medir a capacidade do modelo sem truques de prompt como chain-of-thought (exceto nos modelos que já internalizam isso, como o o1-mini e gemini-thinking)
-
A primeira fase do exame da OAB é feita sem consulta (segundo o Google)
Apesar das diferenças no gráfico, na prática considero que o Gemini-Exp-1206, Claude Sonnet 3.5 e (Chat)GPT-4o empataram.
Em termos de modelos menores, o Gemini Flash se destacou, e essa é minha experiência com ele em várias áreas que testei: é o melhor modelo dentre os pequenos e baratos desde seu lançamento.
Um dos casos interessantes é a má performance do o1-mini, que “raciocina” e eu esperava ter um desempenho melhor.
Acho que o desempenho ruim dele é porque os dados de treino devem ser praticamente todos em inglês e focados em raciocínio matemático, que não necessariamente transfere bem para raciocínio jurídico.
Última curiosidade, o Gemini-Exp-1206 e o Sonnet 3.5 erraram apenas 3 questões em comum: 43, 48 e 50.
A impressão que tive analisando os casos de erro é que, com acesso à legislação e mais tempo para “raciocinar”, eles acertariam mais questões.
Enfim, foi divertido analisar, e esse era o objetivo 😜
Fabrício Carraro generosamente avaliou o o1-2024-12-17, que eu ainda não tenho acesso. Também avaliou o Sabiá 3.
Como Rodei o Teste#
Primeiro criei scripts para extrair as perguntas da prova 1. Cada versão tinha as mesmas questões, só que em ordens diferentes. Depois, extraí as respostas do gabarito.
Para cada pergunta que extraí, fiz uma chamada de API. Desenvolvi outro script para extrair as respostas que a IA me deu, com retry caso não houvesse resposta - só o o1-mini que deu problemas.
Por fim, fiz um script para comparar as respostas que a IA gerou com o gabarito, o que me deu os resultados que estão no artigo.
Para ser um teste mais robusto, o ideal é rodar mais vezes nos mesmos modelos e agregar as respostas. Mas como é só uma curiosidade, não fiz isso.
O1 2024-12-17#
| Métrica |
Valor |
| Respostas corretas |
75/79 |
| Taxa de acerto |
94,94% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 5 |
D |
B |
| 48 |
A |
D |
| 50 |
D |
C |
| 75 |
C |
A |
Claude 3.7 Sonnet (Base, Sem Thinking Tokens)#
| Métrica |
Valor |
| Respostas corretas |
74/79 |
| Taxa de acerto |
93,67% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 28 |
A |
C |
| 48 |
A |
D |
| 61 |
A |
C |
| 63 |
B |
D |
| 69 |
A |
D |
Claude 3.5 Sonnet 2024-10-22#
| Métrica |
Valor |
| Respostas corretas |
70/79 |
| Taxa de acerto |
88,61% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 27 |
A |
C |
| 42 |
C |
A |
| 48 |
A |
D |
| 50 |
D |
A |
| 52 |
C |
B |
| 61 |
A |
C |
| 63 |
B |
D |
| 69 |
A |
D |
| 70 |
B |
A |
Gemini Experimental 1206#
| Métrica |
Valor |
| Respostas corretas |
70/79 |
| Taxa de acerto |
88,61% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
A |
| 21 |
B |
C |
| 48 |
A |
B |
| 50 |
D |
C |
| 52 |
C |
B |
| 63 |
B |
D |
| 68 |
C |
A |
| 74 |
B |
D |
| 76 |
A |
D |
ChatGPT 4o Latest#
| Métrica |
Valor |
| Respostas corretas |
69/79 |
| Taxa de acerto |
87,34% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 5 |
D |
B |
| 19 |
B |
C |
| 21 |
B |
D |
| 25 |
C |
A |
| 48 |
A |
D |
| 50 |
D |
C |
| 63 |
B |
D |
| 69 |
A |
D |
| 74 |
B |
D |
| 77 |
D |
B |
GPT-4o-2024-11-20#
| Métrica |
Valor |
| Respostas corretas |
68/79 |
| Taxa de acerto |
86,08% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 5 |
D |
B |
| 19 |
B |
C |
| 21 |
B |
D |
| 25 |
C |
A |
| 28 |
A |
C |
| 48 |
A |
D |
| 50 |
D |
C |
| 63 |
B |
D |
| 69 |
A |
D |
| 74 |
B |
D |
| 77 |
D |
B |
Gemini 2.0 Flash Thinking Experimental 01-21#
| Métrica |
Valor |
| Respostas corretas |
67/79 |
| Taxa de acerto |
84,81% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
A |
| 5 |
D |
B |
| 7 |
C |
B |
| 21 |
B |
C |
| 32 |
A |
D |
| 48 |
A |
D |
| 50 |
D |
C |
| 52 |
C |
B |
| 61 |
A |
C |
| 68 |
C |
A |
| 73 |
D |
C |
| 74 |
B |
D |
Gemini 2.0 Pro Exp 02-05#
| Métrica |
Valor |
| Respostas corretas |
67/79 |
| Taxa de acerto |
84,81% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
A |
| 19 |
B |
C |
| 21 |
B |
C |
| 33 |
A |
B |
| 48 |
A |
B |
| 50 |
D |
C |
| 52 |
C |
B |
| 63 |
B |
D |
| 68 |
C |
A |
| 69 |
A |
D |
| 74 |
B |
D |
| 76 |
A |
D |
Gemini 2.0 Flash Thinking Experimental 12-19#
| Métrica |
Valor |
| Respostas corretas |
65/79 |
| Taxa de acerto |
82,28% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
C |
| 5 |
D |
B |
| 7 |
C |
B |
| 19 |
B |
A |
| 35 |
C |
B |
| 36 |
A |
D |
| 48 |
A |
B |
| 52 |
C |
D |
| 55 |
C |
B |
| 61 |
A |
C |
| 68 |
C |
A |
| 69 |
A |
D |
| 70 |
B |
C |
| 74 |
B |
D |
DeepSeek R1#
| Métrica |
Valor |
| Respostas corretas |
65/79 |
| Taxa de acerto |
82,28% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 4 |
A |
D |
| 5 |
D |
B |
| 7 |
C |
B |
| 27 |
A |
C |
| 28 |
A |
C |
| 32 |
A |
D |
| 33 |
A |
C |
| 48 |
A |
C |
| 50 |
D |
C |
| 53 |
D |
C |
| 54 |
B |
D |
| 61 |
A |
C |
| 64 |
A |
C |
| 70 |
B |
C |
Llama 3.1 405B Instruct#
| Métrica |
Valor |
| Respostas corretas |
63/79 |
| Taxa de acerto |
79,75% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
A |
| 21 |
B |
C |
| 32 |
A |
D |
| 36 |
A |
D |
| 48 |
A |
D |
| 50 |
D |
A |
| 51 |
B |
C |
| 52 |
C |
B |
| 53 |
D |
C |
| 56 |
B |
D |
| 57 |
C |
A |
| 63 |
B |
D |
| 64 |
A |
C |
| 69 |
A |
C |
| 71 |
C |
D |
| 77 |
D |
B |
Gemini 2.0 Flash#
| Métrica |
Valor |
| Respostas corretas |
62/79 |
| Taxa de acerto |
78,48% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
C |
| 5 |
D |
B |
| 11 |
B |
D |
| 14 |
A |
D |
| 19 |
B |
C |
| 21 |
B |
C |
| 24 |
B |
D |
| 27 |
A |
C |
| 32 |
A |
D |
| 33 |
A |
B |
| 36 |
A |
D |
| 48 |
A |
B |
| 61 |
A |
C |
| 68 |
C |
B |
| 69 |
A |
D |
| 70 |
B |
C |
| 76 |
A |
D |
Qwen 2.5 Max#
| Métrica |
Valor |
| Respostas corretas |
59/79 |
| Taxa de acerto |
74,68% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
A |
| 19 |
B |
C |
| 24 |
B |
D |
| 28 |
A |
C |
| 32 |
A |
D |
| 33 |
A |
B |
| 35 |
C |
B |
| 40 |
B |
C |
| 48 |
A |
B |
| 50 |
D |
C |
| 53 |
D |
C |
| 54 |
B |
C |
| 61 |
A |
C |
| 63 |
B |
D |
| 68 |
C |
A |
| 69 |
A |
B |
| 71 |
C |
B |
| 74 |
B |
D |
| 76 |
A |
D |
| 78 |
A |
C |
Sabia-3#
| Métrica |
Valor |
| Respostas corretas |
58/79 |
| Taxa de acerto |
73,42% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 4 |
A |
B |
| 24 |
B |
A |
| 27 |
A |
C |
| 28 |
A |
B |
| 36 |
A |
D |
| 40 |
B |
D |
| 48 |
A |
B |
| 50 |
D |
C |
| 52 |
C |
B |
| 53 |
D |
C |
| 57 |
C |
B |
| 60 |
C |
D |
| 61 |
A |
C |
| 62 |
C |
B |
| 63 |
B |
D |
| 68 |
C |
A |
| 69 |
A |
B |
| 74 |
B |
D |
| 76 |
A |
D |
| 77 |
D |
B |
| 78 |
A |
C |
O3 Mini High#
| Métrica |
Valor |
| Respostas corretas |
58/79 |
| Taxa de acerto |
73,42% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 3 |
D |
B |
| 4 |
A |
B |
| 5 |
D |
C |
| 8 |
A |
B |
| 27 |
A |
C |
| 28 |
A |
C |
| 33 |
A |
C |
| 35 |
C |
B |
| 42 |
C |
B |
| 48 |
A |
D |
| 50 |
D |
A |
| 57 |
C |
A |
| 61 |
A |
C |
| 62 |
C |
B |
| 63 |
B |
D |
| 64 |
A |
C |
| 68 |
C |
A |
| 73 |
D |
C |
| 76 |
A |
D |
| 77 |
D |
B |
| 78 |
A |
C |
DeepSeek-R1-Distill-Llama-70B#
| Métrica |
Valor |
| Respostas corretas |
55/79 |
| Taxa de acerto |
69,62% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 3 |
D |
C |
| 5 |
D |
B |
| 11 |
B |
D |
| 21 |
B |
C |
| 25 |
C |
A |
| 27 |
A |
D |
| 28 |
A |
C |
| 32 |
A |
D |
| 35 |
C |
B |
| 36 |
A |
D |
| 48 |
A |
B |
| 50 |
D |
A |
| 52 |
C |
D |
| 53 |
D |
C |
| 54 |
B |
D |
| 55 |
C |
A |
| 61 |
A |
C |
| 64 |
A |
C |
| 68 |
C |
B |
| 69 |
A |
C |
| 70 |
B |
C |
| 71 |
C |
D |
| 74 |
B |
D |
| 78 |
A |
C |
Llama 3.3 70B Instruct#
| Métrica |
Valor |
| Respostas corretas |
52/79 |
| Taxa de acerto |
65,82% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
C |
| 4 |
A |
B |
| 5 |
D |
B |
| 11 |
B |
D |
| 21 |
B |
C |
| 26 |
C |
D |
| 28 |
A |
C |
| 32 |
A |
D |
| 33 |
A |
B |
| 34 |
D |
B |
| 35 |
C |
B |
| 36 |
A |
D |
| 48 |
A |
B |
| 53 |
D |
C |
| 54 |
B |
D |
| 55 |
C |
B |
| 57 |
C |
A |
| 59 |
C |
D |
| 63 |
B |
D |
| 64 |
A |
C |
| 67 |
D |
B |
| 68 |
C |
B |
| 69 |
A |
C |
| 71 |
C |
D |
| 76 |
A |
D |
| 77 |
D |
B |
| 78 |
A |
C |
O1 Mini 2024-09-12#
| Métrica |
Valor |
| Respostas corretas |
51/79 |
| Taxa de acerto |
64,56% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 5 |
D |
C |
| 8 |
A |
B |
| 16 |
D |
A |
| 21 |
B |
C |
| 22 |
D |
C |
| 27 |
A |
C |
| 28 |
A |
C |
| 32 |
A |
D |
| 35 |
C |
B |
| 36 |
A |
D |
| 42 |
C |
D |
| 47 |
C |
A |
| 48 |
A |
C |
| 50 |
D |
C |
| 52 |
C |
D |
| 53 |
D |
C |
| 54 |
B |
C |
| 55 |
C |
A |
| 57 |
C |
B |
| 61 |
A |
C |
| 62 |
C |
D |
| 64 |
A |
D |
| 68 |
C |
A |
| 69 |
A |
C |
| 71 |
C |
B |
| 74 |
B |
D |
| 76 |
A |
D |
| 77 |
D |
B |
Claude 3.5 Haiku#
| Métrica |
Valor |
| Respostas corretas |
50/79 |
| Taxa de acerto |
63,29% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
C |
| 4 |
A |
B |
| 11 |
B |
D |
| 12 |
A |
B |
| 19 |
B |
C |
| 22 |
D |
B |
| 24 |
B |
A |
| 28 |
A |
B |
| 32 |
A |
D |
| 33 |
A |
B |
| 34 |
D |
B |
| 35 |
C |
B |
| 36 |
A |
D |
| 40 |
B |
C |
| 41 |
D |
B |
| 48 |
A |
D |
| 50 |
D |
A |
| 52 |
C |
B |
| 53 |
D |
C |
| 57 |
C |
A |
| 61 |
A |
C |
| 62 |
C |
D |
| 68 |
C |
B |
| 69 |
A |
C |
| 71 |
C |
B |
| 76 |
A |
D |
| 77 |
D |
C |
| 78 |
A |
C |
| 79 |
D |
B |
GPT-4o Mini#
| Métrica |
Valor |
| Respostas corretas |
49/79 |
| Taxa de acerto |
62,03% |
Respostas Erradas#
| Questão |
Correta |
Selecionada |
| 2 |
B |
A |
| 3 |
D |
B |
| 5 |
D |
C |
| 16 |
D |
C |
| 19 |
B |
A |
| 21 |
B |
C |
| 22 |
D |
C |
| 24 |
B |
A |
| 26 |
C |
D |
| 32 |
A |
D |
| 34 |
D |
B |
| 35 |
C |
B |
| 40 |
B |
C |
| 48 |
A |
C |
| 50 |
D |
C |
| 52 |
C |
B |
| 53 |
D |
C |
| 54 |
B |
C |
| 55 |
C |
A |
| 57 |
C |
A |
| 61 |
A |
C |
| 67 |
D |
A |
| 68 |
C |
A |
| 69 |
A |
C |
| 70 |
B |
A |
| 71 |
C |
D |
| 73 |
D |
C |
| 76 |
A |
D |
| 77 |
D |
C |
| 78 |
A |
C |
Seja o primeiro a saber das novidades em Machine Learning. Me siga no
LinkedIn.