Está enfrentando dificuldades para interpretar seu modelo de regressão logística e identificar quais features realmente influenciam na previsão da sua variável alvo?
Determinar quais features estão influenciando as previsões do seu modelo pode ser frustrante, especialmente quando lidamos com um grande número de variáveis.
A situação pode se complicar ainda mais com a presença de features correlacionadas.
Neste tutorial, exploraremos diversos métodos para avaliar a importância das features em modelos de regressão logística, tanto para classificação binária quanto para classificação multiclasse.
Para aproveitar ao máximo este guia, é recomendável ter um conhecimento básico de Python e compreender os conceitos fundamentais de machine learning
Familiaridade com bibliotecas como pandas e scikit-learn também será útil.
Então, vamos começar!
Importância de Features na Regressão Logística Binária
Vamos utilizar o conjunto de dados “Red Wine Quality” do repositório UCI Machine Learning.
Este conjunto de dados inclui propriedades químicas do vinho tinto como features e a qualidade do vinho como variável alvo.
Para calcular a importância das features na regressão logística binária, uma abordagem simples é utilizar os coeficientes do modelo.
Esses coeficientes indicam a mudança no log-odds de um evento ocorrer para cada variação de uma unidade na variável preditora.
Em outras palavras, eles mostram como a chance de um evento ocorrer (por exemplo, a qualidade do vinho ser alta) muda à medida que uma determinada variável independente (como a acidez do vinho) aumenta ou diminui em uma unidade.
Vamos para o código!
Primeiro, a URL do conjunto de dados é armazenada em uma variável chamada url.
Este conjunto de dados é um CSV (Comma Separated Values) que contém informações sobre a qualidade do vinho tinto.
import pandas as pd
from sklearn.model_selection import train_test_split
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
A seguir, utilizamos a função pd.read_csv do Pandas para ler o arquivo CSV a partir da URL fornecida.
O parâmetro sep=";" indica que o separador de campos no arquivo CSV é o ponto e vírgula, não a vírgula padrão.
wine_data = pd.read_csv(url, sep=";")
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol |
|---|---|---|---|---|---|---|---|---|---|---|
| 8.6 | 0.22 | 0.36 | 1.9 | 0.064 | 53 | 77 | 0.99604 | 3.47 | 0.87 | 11 |
| 12.5 | 0.46 | 0.63 | 2 | 0.071 | 6 | 15 | 0.9988 | 2.99 | 0.87 | 10.2 |
| 7.2 | 0.54 | 0.27 | 2.6 | 0.084 | 12 | 78 | 0.9964 | 3.39 | 0.71 | 11 |
| 6.4 | 0.67 | 0.08 | 2.1 | 0.045 | 19 | 48 | 0.9949 | 3.49 | 0.49 | 11.4 |
| 7.5 | 0.58 | 0.14 | 2.2 | 0.077 | 27 | 60 | 0.9963 | 3.28 | 0.59 | 9.8 |
Depois de carregar os dados, a coluna quality é renomeada para si mesma.
Este passo pode parecer redundante, mas pode ser necessário em contextos onde a manipulação ou a reatribuição da coluna se faz necessária por conta de alguma lógica adicional no código.
Em seguida, preparamos os dados para a modelagem.
Criamos a matriz de features X removendo a coluna quality do conjunto de dados, pois esta é a nossa variável alvo e não deve ser usada como feature de entrada.
Utilizamos a função drop do Pandas, com axis=1 indicando que estamos removendo uma coluna.
X = wine_data.drop('quality', axis=1)
Originalmente, a variável alvo é uma variável contínua que varia de 3 a 8.
Vamos aplicar uma transformação que converte os valores de qualidade em classes binárias: vinhos com qualidade maior que 5 são rotulados como 1 (bons vinhos), e vinhos com qualidade 5 ou menor são rotulados como 0 (vinhos não tão bons).
Isto é feito usando a função apply com uma expressão lambda.
y = wine_data['quality'].apply(lambda x: 1 if x > 5 else 0)
Finalmente, dividimos os dados em conjuntos de treinamento e teste.
A função train_test_split do Scikit-learn é usada para isso.
Definimos que 30% dos dados serão usados para teste (test_size=0.3), e a semente aleatória é fixada em 42 (random_state=42) para garantir a reprodutibilidade dos resultados.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Com isso, temos os conjuntos de dados prontos para treinar e avaliar um modelo.
O conjunto X_train contém as features de entrada para o treinamento, y_train contém as classes correspondentes para o treinamento, X_test contém as features de entrada para a validação, e y_test contém as classes correspondentes para a validação.
Primeiro, importamos as bibliotecas necessárias.
numpy é uma biblioteca populare para cálculos numéricos.
LogisticRegression é uma classe do Scikit-learn usada para criar um modelo de regressão logística.
StandardScaler é uma classe do Scikit-learn usada para escalar as features, removendo a média e escalando para a variância unitária.
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
Em seguida, instanciamos o StandardScaler, que será utilizado para escalar nossos dados.
A padronização é um passo importante na preparação dos dados para muitos algoritmos de machine learning, incluindo a regressão logística, pois ajuda a melhorar a convergência do algoritmo.
scaler = StandardScaler()
Usamos o método fit_transform do StandardScaler para ajustar o scaler aos dados de treinamento (X_train) e, em seguida, transformar X_train para que tenha média zero e variância unitária.
Ele agrega dois passos em um: calcula e armazena a média e o desvio padrão dos dados de treinamento e, em seguida, aplica a transformação.
Se as features tiverem escalas ou unidades diferentes, o modelo pode atribuir coeficientes maiores (portanto, maior importância) às features com valores maiores, mesmo que elas não sejam necessariamente mais importantes.
Quando as features são padronizadas, a magnitude dos coeficientes na regressão logística reflete diretamente a importância de cada feature.
Para os dados de teste (X_test), utilizamos apenas o método transform para aplicar a mesma transformação determinada pelos dados de treinamento.
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
Criamos uma instância do modelo de regressão logística usando a classe LogisticRegression e treinamos o modelo com os dados de treinamento padronizados (X_train) e suas respectivas classes (y_train).
O método fit é usado para ajustar o modelo aos dados.
model = LogisticRegression()
model.fit(X_train, y_train)
Depois de treinar o modelo, extraímos os coeficientes da regressão logística.
Estes coeficientes indicam a importância de cada feature no modelo.
Como estamos lidando com uma única variável alvo binária, os coeficientes estão na primeira (e única) posição do array coef_.
coefficients = model.coef_[0]
Criamos um DataFrame do Pandas para armazenar as características e suas respectivas importâncias.
Usamos np.abs para pegar os valores absolutos dos coeficientes, pois tanto coeficientes positivos quanto negativos indicam a importância das features, apenas em direções diferentes.
feature_importance = pd.DataFrame({'Feature': X.columns, 'Importance': np.abs(coefficients)})
Ordenamos o DataFrame feature_importance em ordem crescente de importância, para que as features mais importantes apareçam primeiro no gráfico.
Parece estranho, mas por alguma razão é assim que o Pandas funciona.
feature_importance = feature_importance.sort_values('Importance', ascending=True)
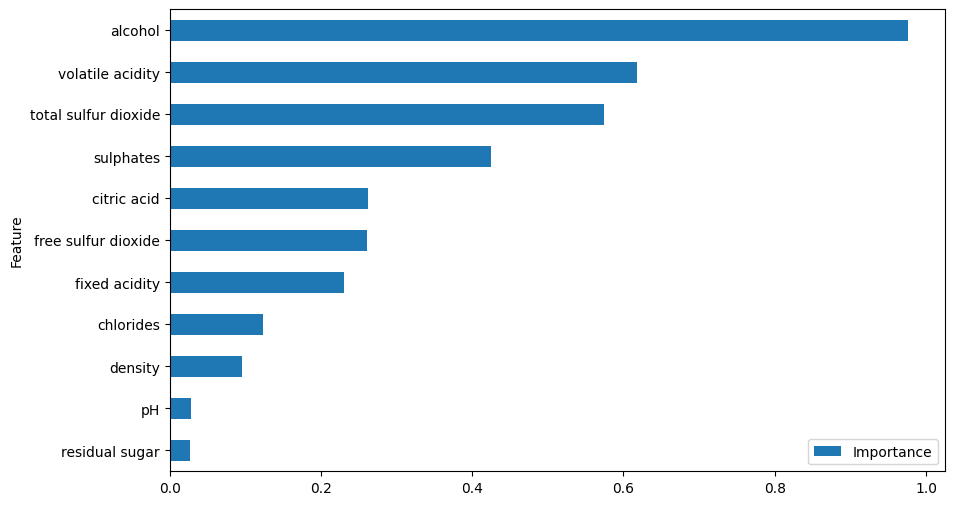
Por fim, plotamos a importância das características usando um gráfico de barras horizontais (barh).
Ajustamos o tamanho da figura para 10x6 polegadas para garantir que o gráfico seja legível.
feature_importance.plot(x='Feature', y='Importance', kind='barh', figsize=(10, 6))

De acordo com este método, acidez volátil, álcool e densidade são as features mais importantes.
Vamos ver como calcular a importância das features para a regressão logística multiclasse.
Importância de Features na Regressão Logística Multiclasse
Na regressão logística multiclasse, temos um conjunto separado de coeficientes para cada classe.
Podemos calcular a importância das features tomando a média dos valores absolutos dos coeficientes em todas as classes.
Ou, se quisermos saber a importância de uma feature para uma classe específica, podemos usar os coeficientes para essa classe.
X = wine_data.drop('quality', axis=1)
y = wine_data['quality']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Desta vez, não vamos binarizar a variável alvo e mantê-la como um problema multiclasse.
Agora, vamos treinar um modelo de regressão logística no conjunto de treinamento.
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
model = LogisticRegression()
model.fit(X_train, y_train)
coefficients = model.coef_
avg_importance = np.mean(np.abs(coefficients), axis=0)
feature_importance = pd.DataFrame({'Feature': X.columns, 'Importance': avg_importance})
feature_importance = feature_importance.sort_values('Importance', ascending=True)
feature_importance.plot(x='Feature', y='Importance', kind='barh', figsize=(10, 6))
Primeiro, escalonamos as features usando StandardScaler como antes.
Então, criamos um modelo de regressão logística, mas desta vez será um modelo multiclasse.
Após treinar o modelo, podemos acessar os coeficientes usando o atributo coef_.
Aqui, tomamos a array completa em vez de apenas a primeira linha.
Calculamos a importância média em todas as classes tomando a média dos valores absolutos dos coeficientes.
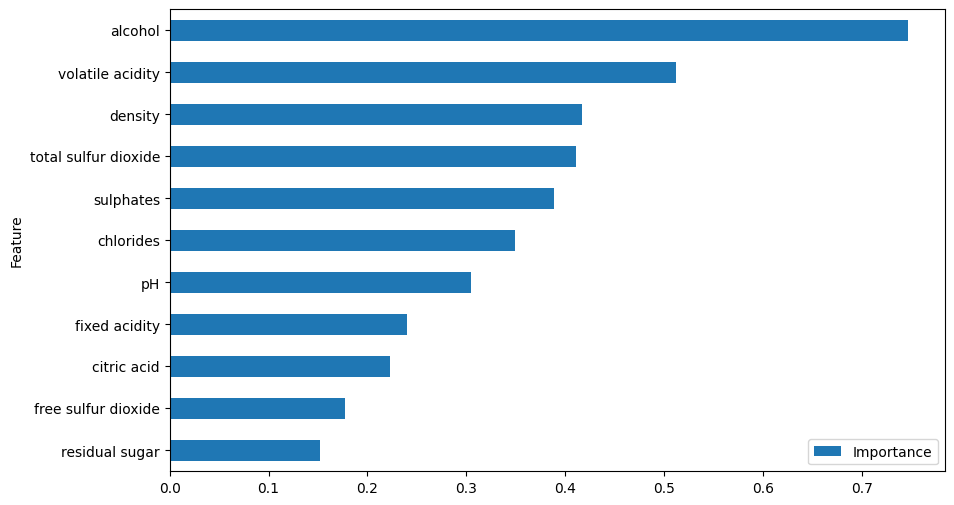
Esses métodos são simples e fáceis de implementar, mas possuem algumas limitações.
Quando as features são altamente correlacionadas, os coeficientes podem se tornar instáveis, e sua magnitude pode não representar com precisão a importância real das features.
Nesses casos, a importância de um grupo de features correlacionadas pode ser distribuída entre elas, dificultando a interpretação da importância individual de cada feature.
Vamos testar um método mais avançado: a importância por permutação.
Importância por Permutação para Regressão Logística
A importância por permutação é um método independente para calcular a importância das features que pode ser usado com qualquer modelo, não apenas com a regressão logística.
A ideia por trás da importância por permutação é medir a queda no desempenho do modelo quando os valores de uma feature específica são permutados aleatoriamente, após o treinamento, quebrando a relação entre a feature e a variável alvo.
Se embaralhar os valores de uma feature resultar em uma grande queda no desempenho do modelo, então a feature é importante.
O scikit-learn possui uma função integrada para calcular a importância por permutação.
Como esse método usa as previsões em um conjunto de dados fora da amostra para calcular a importância das features, podemos usar o modelo que já treinamos.
from sklearn.inspection import permutation_importance
result = permutation_importance(model, X_test, y_test, n_repeats=10, random_state=42)
feature_importance = pd.DataFrame({'Feature': X.columns,
'Importance': result.importances_mean,
'Standard Deviation': result.importances_std})
feature_importance = feature_importance.sort_values('Importance', ascending=True)
ax = feature_importance.plot(x='Feature', y='Importance', kind='barh', figsize=(10, 6), yerr='Standard Deviation', capsize=4)
ax.set_xlabel('Permutation Importance')
ax.set_title('Permutation Importance with Standard Deviation')
Precisamos passar o modelo e o conjunto de validação para a função permutation_importance.
O parâmetro n_repeats especifica quantas vezes os valores da feature são permutados.
Mais repetições fornecerão resultados mais precisos, mas levarão mais tempo para serem computados.
O parâmetro random_state é usado para definir a semente aleatória para reprodutibilidade.
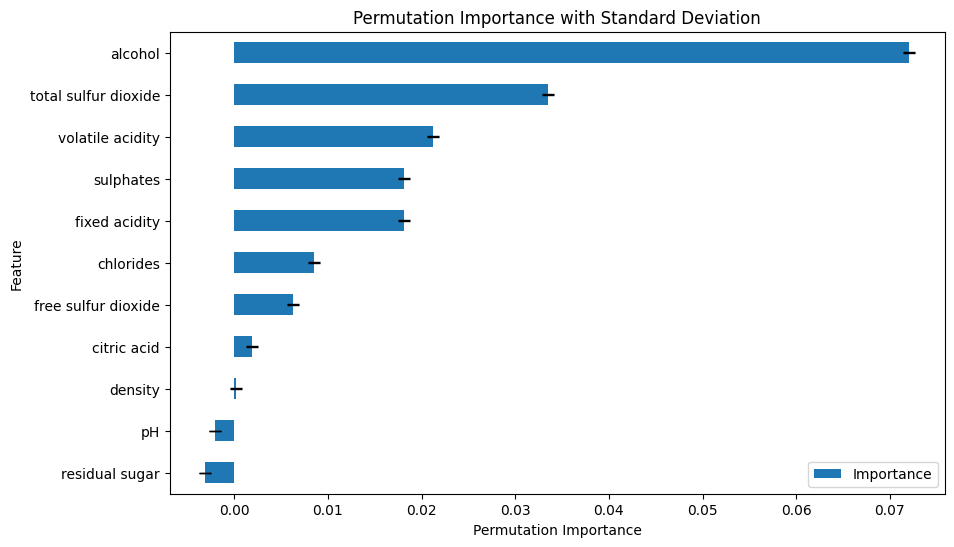
Esse método nos fornece a importância média e o desvio padrão em todas as repetições.
Questões Adicionais sobre a Importância de Features na Regressão Logística
Como Lidar com Features Altamente Correlacionadas?
Remova ou combine-as.
Você pode descartar uma das features correlacionadas ou criar uma nova feature que combine informações de ambas.
Como Interpretar os Coeficientes Negativos e Positivos?
Um coeficiente positivo significa que um aumento no valor da feature aumentará o log-odds da classe positiva, tornando-a mais provável.
Por outro lado, um coeficiente negativo significa que um aumento no valor da feature diminuirá o log-odds da classe positiva, tornando-a menos provável.
Suponha que o coeficiente para a característica alcohol é 2,0.
Isso significa que, mantendo todas as outras características constantes, um aumento no nível de álcool aumentará significativamente a chance de um vinho ser considerado de boa qualidade (classe positiva).
Em outras palavras, vinhos com maiores níveis de álcool são mais propensos a serem classificados como de boa qualidade.
Agora, imagine que o coeficiente para a característica volatile acidity seja -1,5.
Isso indica que, mantendo todas as outras características constantes, um aumento na acidez volátil diminuirá a log-odds de um vinho ser considerado de boa qualidade.
Ou seja, vinhos com maior acidez volátil são menos propensos a serem classificados como de boa qualidade.
Como Obter a Importância da Feature para uma Classe Específica na Regressão Logística Multiclasse?
Para calcular a importância da feature para uma classe específica, você pode acessar os coeficientes correspondentes a essa classe.
class_index = 2 # Defina o índice da classe em que você está interessado
coefficients = model.coef_[class_index] # Acesse os coeficientes para a classe específica
feature_importance = pd.DataFrame({'Feature': X.columns, 'Importance': np.abs(coefficients)})
feature_importance = feature_importance.sort_values('Importance', ascending=True)
feature_importance.plot(x='Feature', y='Importance', kind='barh', figsize=(1280/96, 720/96))
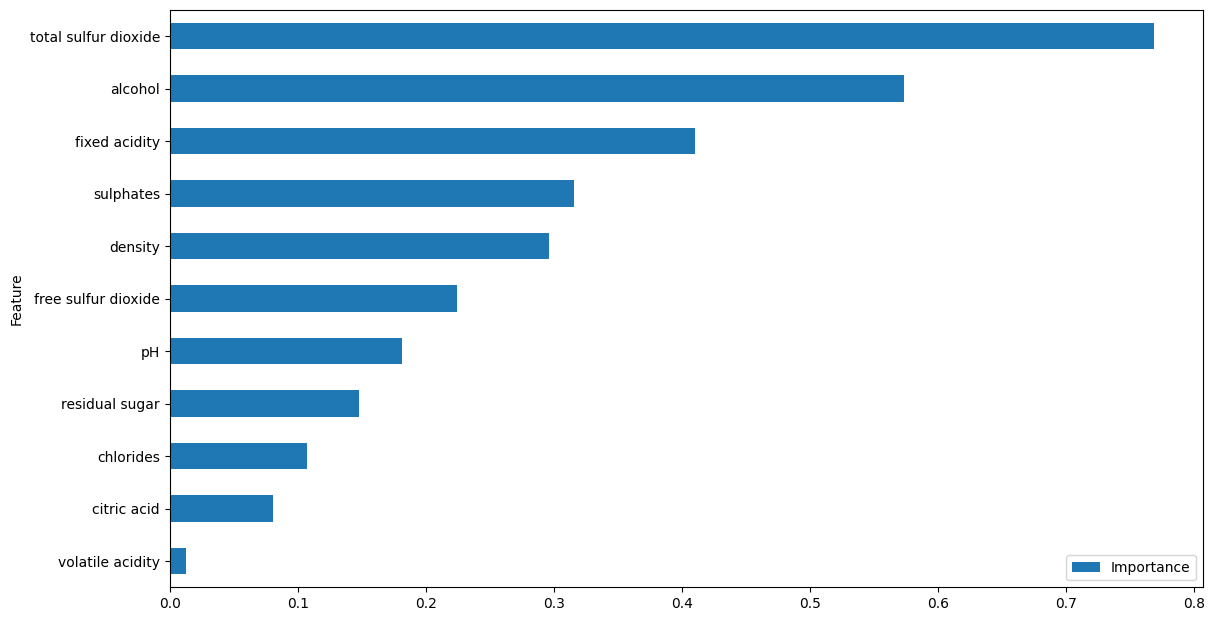
Substitua class_index pelo índice da classe que você deseja analisar (por exemplo, 0 para a primeira classe, 1 para a segunda classe e assim por diante).
Este código modificado calculará a importância da feature para a classe especificada usando seus coeficientes correspondentes.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.