
O GPT (Generative Pre-trained Transformer) é uma tecnologia de ponta no campo do processamento de linguagem natural (NLP).
Desenvolvido pela OpenAI, o GPT utiliza aprendizado profundo para compreender e gerar texto de forma contextual e coerente.
A capacidade do GPT de entender nuances linguísticas, responder a perguntas complexas e até mesmo gerar conteúdo criativo o torna uma ferramenta valiosa para uma ampla gama de aplicações.
Você deve conhecer a interface do ChatGPT, que é um exemplo de como o GPT pode ser usado para criar assistentes virtuais, mas a OpenAI também oferece uma API para que você possa integrar o GPT em seus projetos de maneira programática.
Ao usar o GPT via API em Python, você pode integrar essas poderosas capacidades de NLP diretamente em seus projetos, permitindo:
- Geração de texto automatizada
- Análise de sentimentos
- Tradução de idiomas
- Resumo de textos
- Chatbots e assistentes virtuais
- E muito mais
Neste artigo, exploraremos em detalhes como utilizar o GPT através da API da OpenAI em Python.
Crie Uma Conta Na OpenAI
-
Acesse o site da Plataforma para Desenvolvedores da OpenAI.
-
Clique no botão “Sign up” no canto superior direito da página.
- Você pode se cadastrar usando seu e-mail ou através de uma conta Google, Microsoft ou Apple.
- Siga as instruções para verificar seu e-mail e completar o processo de registro.
Gere Uma API Key
A API key é essencial para autenticar suas solicitações à API do GPT.
Siga estes passos para gerar sua chave:
- Acesse a página de API keys em sua conta da OpenAI.
- Na página de API keys, clique no botão “Create new secret key”.
- Escolha um nome descritivo para sua chave e clique em “Create secret key”.
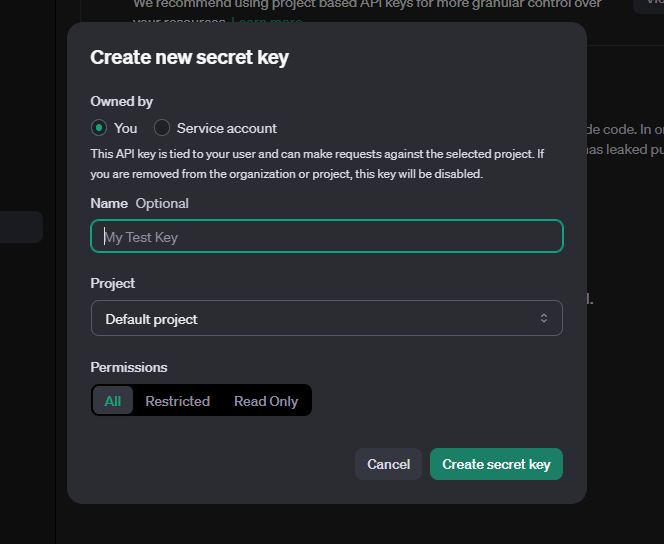
- Copie-a imediatamente e armazene-a em um local seguro, pois você não poderá visualizá-la novamente.
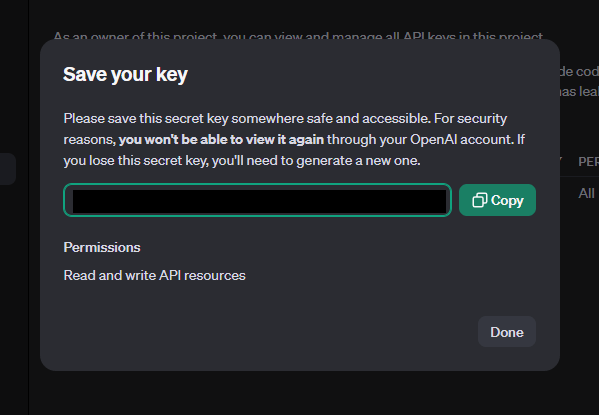
IMPORTANTE: Trate sua API key como uma senha. Nunca a compartilhe publicamente ou a inclua diretamente em seu código-fonte versionado.
Configure a Variável de Ambiente
Configurar a API key como uma variável de ambiente é uma prática de segurança recomendada, pois evita que você acidentalmente exponha sua chave no código-fonte.
Para configurar a variável de ambiente:
- No Windows:
set OPENAI_API_KEY=sua_api_key_aqui - No macOS/Linux:
export OPENAI_API_KEY=sua_api_key_aqui
Alternativamente, você pode adicionar esta linha ao seu arquivo .bashrc ou .zshrc para torná-la permanente.
No Windows, você também pode definir variáveis de ambiente permanentes através do Painel de Controle.
Instale a Biblioteca da OpenAI para Python
A biblioteca oficial da OpenAI para Python facilita a integração com a API.
Para instalá-la via pip, execute o seguinte comando:
pip install openai
Este comando baixará e instalará a versão mais recente da biblioteca OpenAI e suas dependências.
Exemplo Básico de Uso Para Gerar Texto Com o GPT
Vamos criar um exemplo simples para demonstrar como usar o GPT para gerar texto:
from openai import OpenAI
client = OpenAI()
prompt = "Qual é a capital do Brasil e por que ela foi escolhida?"
resposta = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
]
)
Primeiro importamos o objeto OpenAI da biblioteca openai.
Depois, criamos uma instância desse objeto e armazenamos em client.
O client servirá como a interface principal para interagir com a API do GPT.
Ele busca automaticamente a chave da API na variável de ambiente OPENAI_API_KEY para autenticação.
Em seguida, definimos um prompt com uma pergunta sobre a capital do Brasil.
Usamos o método chat.completions.create para enviar o prompt ao modelo GPT-3.5 Turbo e obter uma resposta.
Por enquanto usei apenas dois parâmetros, o modelo e as mensagens.
O modelo determina qual versão do GPT será usada, enquanto as mensagens são uma lista de mensagens trocadas entre o usuário e o modelo.
A escolha do modelo afeta a qualidade da resposta, o tempo de processamento e o custo.
O GPT-4o é mais capaz, mas também mais caro.
Você pode conferir os modelos disponíveis na documentação da OpenAI.
Esta área muda muito rápido, então é sempre bom verificar a documentação oficial para obter as informações mais recentes sobre quais modelos ainda estão disponíveis.
Vamos explorar a lista de mensagens e a resposta em mais detalhes na próxima seção.
Anatomia De Uma Resposta Da API
Quando você faz uma chamada à API do GPT, a resposta retornada é um objeto rico em informações.
ChatCompletion(
id='chatcmpl-00000',
choices=[
Choice(
finish_reason='stop',
index=0,
logprobs=None,
message=ChatCompletionMessage(
content='A capital do Brasil é Brasília. Ela foi escolhida para substituir o Rio de Janeiro como capital do país devido à sua localização geográfica mais central, o que ajudaria a integrar melhor as diversas regiões do Brasil. Além disso, a construção de Brasília foi idealizada pelo então presidente Juscelino Kubitschek como um projeto de modernização e desenvolvimento do país, marcando o início de uma nova fase na história do Brasil. A cidade foi inaugurada em 21 de abril de 1960.',
role='assistant',
function_call=None,
tool_calls=None))],
created=1720639257,
model='gpt-3.5-turbo-0125',
object='chat.completion',
system_fingerprint=None,
usage=CompletionUsage(
completion_tokens=119,
prompt_tokens=22,
total_tokens=141)
)
Vamos examinar detalhadamente a estrutura dessa resposta para entender melhor como interpretar e utilizar os dados recebidos.
A resposta é um objeto ChatCompletion, que encapsula todos os detalhes da interação com o modelo.
No coração deste objeto está a lista choices, que geralmente contém apenas um item - a resposta gerada pelo modelo.
Cada Choice inclui um objeto message, que contém o conteúdo real da resposta no campo content.
Para obter apenas o texto da resposta, você pode acessar resposta.choices[0].message.content.
Além do conteúdo da resposta, o objeto ChatCompletion fornece metadados valiosos.
O campo id oferece um identificador único para cada resposta, útil para rastreamento e depuração.
O finish_reason indica por que a geração de texto foi concluída, com stop sendo o valor comum para uma conclusão natural da resposta.
Se a resposta fosse interrompida por passar de um limite de tokens especificado, o finish_reason seria length.
O modelo utilizado para gerar a resposta é especificado no campo model, permitindo que você verifique qual versão do GPT foi empregada.
Isso é particularmente útil se você estiver experimentando diferentes modelos em seu aplicativo.
Um aspecto crucial da resposta é o objeto usage, que fornece estatísticas detalhadas sobre o consumo de tokens.
Ele mostra o número de tokens usados no prompt (prompt_tokens), na resposta gerada (completion_tokens), e o total geral (total_tokens).
Essas informações são essenciais para monitorar e otimizar o uso da API, especialmente considerando que o custo do serviço é baseado no consumo de tokens.
Alguns campos, como logprobs, function_call, e tool_calls, podem aparecer como None se não forem relevantes para a solicitação específica.
Estes campos são utilizados em casos de uso mais avançados, como quando você está usando funções personalizadas ou ferramentas específicas com o modelo.
Parâmetros Mais Importantes Para a API do GPT
Ao usar a API do GPT, você pode ajustar vários parâmetros para controlar o comportamento e a saída do modelo:
Mensagens
As messages são a parte mais importante da solicitação, pois definem o contexto e a interação entre o usuário e o modelo.
Cada mensagem é um dicionário com dois campos principais: role e content.
O campo role especifica o papel da mensagem, que pode ser user, assistant, ou system.
A role user é usada para mensagens que devem ser interpretadas como entradas do usuário.
Usei o termo “devem ser interpretadas” porque você pode colar mensagens geradas por outras chamadas feitas ao modelo em contextos diferentes.
Imagine que você tenha duas chamadas separadas: uma para escrever e-mails e outra para verificar se o e-mail está bem escrito.
Você pode colar a resposta da primeira chamada como uma mensagem do usuário na segunda chamada para que o modelo foque apenas na correção do texto na segunda chamada.
A role assistant é usada para mensagens geradas pelo modelo.
Isso abre a possibilidade de criar conversas simuladas entre o usuário e o assistente, mas também será importante na seção sobre conversas com mais de uma mensagem.
Por fim, a role system é usada para definir o comportamento geral do modelo.
Você pode usar essa mensagem para definir o “personagem” ou estilo de resposta que o modelo deve usar em todas as mensagens.
Um caso de uso interessante é adicionar um documento longo a este campo e fazer perguntas sobre o conteúdo do documento nas mensagens do usuário.
A variável content contém o texto de cada mensagem.
Temperatura
A temperature controla a aleatoriedade da saída do modelo.
Este é o parâmetro que você deve ajustar com mais frequência para obter respostas mais ou menos criativas.
Os valores variam de 0 a 2.
Uma temperatura mais baixa (próxima de 0) resulta em respostas mais determinísticas e focadas (apesar de nem sempre serem 100% reprodutíveis).
Geralmente é preferível quando você fizer classificação de texto ou responder a perguntas factuais.
Uma temperatura zero também é conhecida como “greedy decoding”, porque sempre escolhe o token mais provável.
Uma temperatura mais alta produz respostas mais diversas e criativas.
Isso é mais interessante quando você deseja gerar texto criativo ou explorar várias possibilidades.
A criação de histórias ou a geração de ideias de títulos para artigos são exemplos de tarefas que podem se beneficiar de temperaturas mais altas.
Exemplo:
resposta = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user",
"content": "Escreva um poema curto sobre programação"}],
temperature=0.8
)
'No mundo do código e da lógica\nA programação é a nossa música\nCom linhas de comando e algoritmos\nCriamos maravilhas e encurtamos caminhos'
Nos bastidores a temperatura suaviza as probabilidades de token geradas pelo modelo.
Isso faz com que o modelo escolha tokens menos prováveis com mais frequência, resultando em respostas mais variadas.
Max tokens
O parâmetro max_tokens limita o número máximo de tokens (unidades de texto) na resposta.
Ele é útil para controlar o tamanho e o custo da resposta, mas você pode encontrar situações em que a resposta é truncada se o modelo atingir o limite de tokens antes de concluir a resposta.
resposta = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Resuma a história do Brasil"}],
temperature=0.1,
max_tokens=100
)
Logit Bias
Este é um parâmetro pouco falado, mas extremamente poderoso para casos de classificação de texto ou geração de texto com vocabulário específico.
O logit_bias permite aumentar ou diminuir a probabilidade de tokens específicos aparecerem na saída:
Imagine que você queira classificar mensagens de clientes em positivas ou negativas.
Uma maneira é pedir que o modelo diga se uma mensagem específica é positiva ou negativa.
resposta = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "A seguinte mensagem é positiva?\nMensagem: O produto chegou antes do prazo e em perfeitas condições."}],
temperature=0.,
max_tokens=1,
logit_bias={14354: 10, 51899: 10})
Ao passarmos o dicionário de tokens e seus valores, estamos pedindo que a API do GPT aumente a probabilidade de dois tokens específicos aparecerem na resposta.
Mas como você sabe quais tokens usar?
A OpenAI disponibiliza uma ferramenta onde você pode digitar um texto e clicar em “Token IDs” ver os IDs dos tokens.
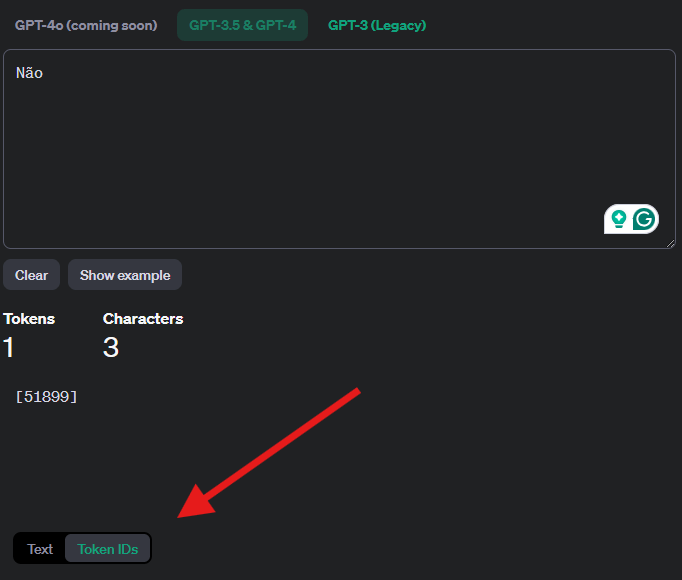
No caso, usei os tokens 14354 e 51899, que são os IDs dos tokens “Sim” e “Não” respectivamente.
Uma observação interessante é que você pode escolher tokens em maiúsculas ou minúsculas, pois o token para “Sim” é diferente de “sim” ou “SIM”.
Em tese, não faz tanta diferença na prática, mas é bom saber disso.
Log Probs
O campo logprobs é um dos recursos mais avançados e poderosos da API do GPT.
Ele fornece informações detalhadas sobre as probabilidades de cada token na resposta gerada.
Usando o exemplo acima, em vez de apenas obter a resposta, você também pode solicitar as probabilidades de cada token que poderia ser gerado.
resposta = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "A seguinte mensagem é positiva?\nMensagem: O produto chegou antes do prazo e em perfeitas condições."}],
temperature=0.,
max_tokens=1,
logit_bias={14354: 100, 51899: 100},
logprobs=True,
top_logprobs=5)
Neste caso, definimos logprobs=True para ativar o registro de probabilidades e top_logprobs=5 para obter as probabilidades dos cinco tokens com maior pontuação.
Segundo a documentação, você pode pedir até 20 tokens com maior pontuação.
Agora a resposta incluirá informações detalhadas sobre as probabilidades dos tokens gerados.
ChatCompletion(...,
choices=[
Choice(...,
logprobs=ChoiceLogprobs(
content=[
ChatCompletionTokenLogprob(
token='Sim', bytes=[83, 105, 109], logprob=-0.00031460886, top_logprobs=[
TopLogprob(token='Sim', bytes=[83, 105, 109], logprob=-0.00031460886),
TopLogprob(token='sim', bytes=[115, 105, 109], logprob=-8.226086),
TopLogprob(token=' Sim', bytes=[32, 83, 105, 109], logprob=-10.226419),
TopLogprob(token='SIM', bytes=[83, 73, 77], logprob=-12.296225),
TopLogprob(token='S', bytes=[83], logprob=-13.851227)])]),
...])
Cada objeto TopLogprob contém informações sobre um token específico, incluindo o token mais provável que foi retornado como content.
Estas probabilidades estão em escala logarítmica, por isso os valores são negativos.
Veja também como existem várias formas do modelo retornar uma resposta positiva, mostrando a importância do logit_bias para evitar problemas na hora de extrair essa resposta.
Infelizmente ajustar o logit_bias não muda as probabilidades retornadas no logprobs, porque um paper mostrou que isso possibilita descobrir a arquitetura do modelo através de ataques à API.
Ainda assim, ele funciona como esperado.
Um caso interessante de uso do log probs é pedir que o modelo faça a mesma classificação de texto, mas com um viés diferente.
Por exemplo, podemos perguntar se a mensagem é negativa também e depois comparar as probabilidades dos tokens “Sim” e “Não” nas duas respostas, para ter uma ideia da confiança do modelo em suas respostas.
Conversas Com Múltiplas Mensagens
Você pode simular uma conversa incluindo múltiplas mensagens, permitindo que o modelo mantenha o contexto ao longo da interação:
# Exemplo de uma conversa
historico = [
{"role": "system", "content": "Você é um assistente útil e amigável."},
{"role": "user", "content": "Oi, pode me ajudar com uma receita?"},
{"role": "assistant", "content": "Claro! Ficarei feliz em ajudar com uma receita. Que tipo de prato você gostaria de preparar?"},
{"role": "user", "content": "Que tal um bolo de chocolate?"},
{"role": "assistant", "content": "Ótima escolha! Vou te dar uma receita simples de bolo de chocolate. Você precisa dos seguintes ingredientes:\n\n- 2 xícaras de farinha de trigo\n- 2 xícaras de açúcar\n- 3/4 xícara de cacau em pó\n- 2 colheres de chá de fermento em pó\n- 1 colher de chá de sal\n- 2 ovos\n- 1 xícara de leite\n- 1/2 xícara de óleo vegetal\n- 2 colheres de chá de essência de baunilha\n- 1 xícara de água quente\n\nVocê gostaria que eu explicasse o modo de preparo?"},
{"role": "user", "content": "Sim, por favor!"}
]
resposta = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=historico
)
Este método é útil para criar chatbots, assistentes virtuais e outras aplicações de diálogo.
Note que usamos a role assistant para as mensagens geradas pelo modelo, mantendo a distinção entre as mensagens do usuário e as respostas da IA.
Respostas Estruturadas Em JSON
Ao trabalhar com a API do GPT, muitas vezes é útil receber respostas em um formato estruturado como JSON.
Isso facilita o processamento e a integração dos dados em suas aplicações Python.
Para garantir que a resposta do modelo seja um objeto JSON válido, você pode usar o parâmetro response_format.
Este recurso está disponível para modelos GPT-4 Turbo e todos os modelos GPT-3.5 Turbo mais recentes que gpt-3.5-turbo-1106.
Aqui está um exemplo de como usar o response_format:
resposta = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Você é um assistente que sempre responde em formato JSON."},
{"role": "user", "content": "Liste os 3 melhores frameworks Python para desenvolvimento web."}
],
response_format={"type": "json_object"}
)
Importante: Ao usar o modo JSON, você deve instruir explicitamente o modelo a produzir JSON através de uma mensagem do sistema ou do usuário.
Após receber a resposta, você pode facilmente processá-la usando a biblioteca json do Python:
import json
conteudo_json = resposta.choices[0].message.content
dados = json.loads(conteudo_json)
print(json.dumps(dados, indent=2, ensure_ascii=False))
{
"frameworks": [
"Django",
"Flask",
"FastAPI"
]
}
Este código carrega o conteúdo JSON da resposta e o imprime de forma formatada.
Lidando com Respostas Parciais
Note que o conteúdo da mensagem pode ser parcialmente cortado se ultrapassar o limite de tokens especificado.
Para lidar com isso, você pode implementar uma verificação:
if resposta.choices[0].finish_reason == "length":
print("Aviso: A resposta pode estar incompleta devido a limitações de comprimento.")
try:
dados = json.loads(conteudo_json)
except json.JSONDecodeError:
print("Erro: A resposta não é um JSON válido. Pode estar incompleta.")
# Implemente uma lógica de tratamento adequada aqui
Lidando Com Erros e Exceções
Ao trabalhar com a API do GPT, é crucial implementar um robusto sistema de tratamento de erros para garantir que sua aplicação funcione de forma confiável.
A API do OpenAI pode retornar vários tipos de erros.
Alguns dos mais comuns incluem:
- Erros de Autenticação
- Erros de Limite de Uso (Rate Limit)
- Erros de Timeout
Implementando Tratamento de Erros
Vamos ver como podemos tratar esses erros de forma eficaz:
from openai import OpenAI
from openai import RateLimitError, APITimeoutError, APIConnectionError
client = OpenAI()
def fazer_requisicao_gpt(prompt):
try:
resposta = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
timeout=10 # Definindo um timeout de 10 segundos
)
return resposta.choices[0].message.content
except RateLimitError as e:
print(f"Erro de limite de uso: {e}")
# Implementar lógica de retry com backoff exponencial
except APITimeoutError:
print("A requisição excedeu o tempo limite.")
# Considerar aumentar o timeout ou dividir a tarefa
except APIConnectionError:
print("Erro de conexão com a API.")
# Verificar a conexão de internet e tentar novamente
except Exception as e:
print(f"Erro inesperado: {e}")
# Logar o erro para investigação futura
Neste exemplo, encapsulamos a chamada à API do GPT em uma função fazer_requisicao_gpt e implementamos um bloco try-except para capturar e tratar diferentes tipos de erros.
Se ocorrer um erro de limite de uso, podemos implementar uma lógica de retry com backoff exponencial para tentar novamente após um intervalo de tempo crescente.
Para erros de timeout, podemos considerar aumentar o tempo limite ou dividir a tarefa em partes menores.
Erros inesperados são capturados por um bloco except Exception genérico, que loga o erro para investigação futura.
Conclusão
Neste artigo, exploramos em detalhes como utilizar o GPT através da API da OpenAI em Python, desde a criação de uma conta e obtenção da API key até a implementação de chamadas avançadas e o tratamento de erros.
A integração do GPT em aplicações Python abre um mundo de possibilidades para o processamento de linguagem natural, permitindo desde a geração de texto automatizada até a criação de assistentes virtuais sofisticados.
As capacidades do GPT em compreender contexto, nuances linguísticas e gerar respostas coerentes o tornam uma ferramenta poderosa para uma ampla gama de aplicações.
À medida que a tecnologia de IA continua a evoluir, é provável que vejamos ainda mais avanços na capacidade e eficiência dos modelos de linguagem.
Futuros desenvolvimentos podem incluir modelos mais especializados para tarefas específicas, melhor compreensão de contextos complexos e integração mais profunda com outras modalidades de IA, como visão computacional e processamento de áudio.
Para os desenvolvedores que estão começando a trabalhar com a API do GPT, é importante lembrar de sempre considerar as melhores práticas de segurança, otimização de custos e tratamento de erros.
Também é bom lembrar que estes modelos não são perfeitos e podem gerar respostas incorretas ou inapropriadas em certas situações.
E você, já tem alguma ideia de como vai usar o GPT em seus projetos?
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.