Interpretar e identificar as features cruciais em modelos de machine learning pode ser um desafio e tanto, especialmente ao lidar com modelos black-box.
Neste tutorial, vamos mergulhar fundo no entendimento da importância global e local das features em Random Forests.
Exploraremos várias técnicas e ferramentas para analisar e interpretar essas importâncias, tornando nossos modelos mais transparentes e confiáveis.
Para ilustrar as técnicas, utilizaremos o conjunto de dados “Red Wine Quality” do Repositório de Machine Learning da UCI.
Este conjunto de dados contém informações sobre as propriedades químicas de vinhos tintos e sua qualidade, avaliada por especialistas em vinhos.
import pandas as pd
from sklearn.model_selection import train_test_split
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
wine_data = pd.read_csv(url, sep=";")
wine_data['quality'] = wine_data['quality']
X = wine_data.drop('quality', axis=1)
y = wine_data['quality']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol |
|---|---|---|---|---|---|---|---|---|---|---|
| 8.6 | 0.22 | 0.36 | 1.9 | 0.064 | 53 | 77 | 0.99604 | 3.47 | 0.87 | 11 |
| 12.5 | 0.46 | 0.63 | 2 | 0.071 | 6 | 15 | 0.9988 | 2.99 | 0.87 | 10.2 |
| 7.2 | 0.54 | 0.27 | 2.6 | 0.084 | 12 | 78 | 0.9964 | 3.39 | 0.71 | 11 |
| 6.4 | 0.67 | 0.08 | 2.1 | 0.045 | 19 | 48 | 0.9949 | 3.49 | 0.49 | 11.4 |
| 7.5 | 0.58 | 0.14 | 2.2 | 0.077 | 27 | 60 | 0.9963 | 3.28 | 0.59 | 9.8 |
Viés de Alta Cardinalidade em Random Forests
Antes de mergulharmos no código, é fundamental entender o viés de alta cardinalidade.
Este viés é um problema comum em modelos de Random Forest, onde o modelo tende a superestimar a importância de features com um grande número de valores únicos.
Isso ocorre porque o algoritmo utiliza o ganho na redução de impureza como um indicador da importância da feature.
No entanto, quando uma feature possui um alto número de valores únicos, o ganho na redução de impureza é artificialmente inflado pelo fato de o modelo ser capaz de realizar mais divisões (splits) nessa feature.
É crucial ter isso em mente ao interpretar gráficos de importância de features, pois pode levar a conclusões incorretas sobre a real importância das features no contexto do modelo.
Se você se deparar com uma feature de alta importância que não parece relevante para o problema, verifique se ela possui um alto número de valores únicos.
Métodos de Importância Global vs. Local de Features
A importância global da feature refere-se à importância geral de uma feature em todas as instâncias do conjunto de dados, enquanto a importância local da feature refere-se à importância de uma feature para uma instância específica.
Neste tutorial, trabalharemos com ambos.
Importância de Features Integrada no Scikit-Learn
O Scikit-learn oferece um método integrado para calcular a importância das features em modelos de Random Forest.
De acordo com a documentação, este método é baseado na diminuição da impureza do nó.
Em termos mais simples, imagine que você está jogando um jogo de adivinhação com seus amigos e tem um conjunto de perguntas para fazer a fim de descobrir a resposta.
Em uma Random Forest, as perguntas são como as features no modelo.
Algumas perguntas ajudam a eliminar mais possibilidades do que outras.
A suposição é que as features que ajudam você a eliminar mais possibilidades rapidamente são mais importantes porque ajudam você a chegar mais perto da resposta correta mais rápido.
É muito simples obter essas importâncias de features com o Scikit-learn:
from sklearn.ensemble import RandomForestRegressor
from matplotlib import pyplot as plt
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
global_importances = pd.Series(rf.feature_importances_, index=X_train.columns)
global_importances.sort_values(ascending=True, inplace=True)
global_importances.plot.barh(color='green')
plt.xlabel("Importância")
plt.ylabel("Feature")
plt.title("Importância Global da Feature - Método Embutido")
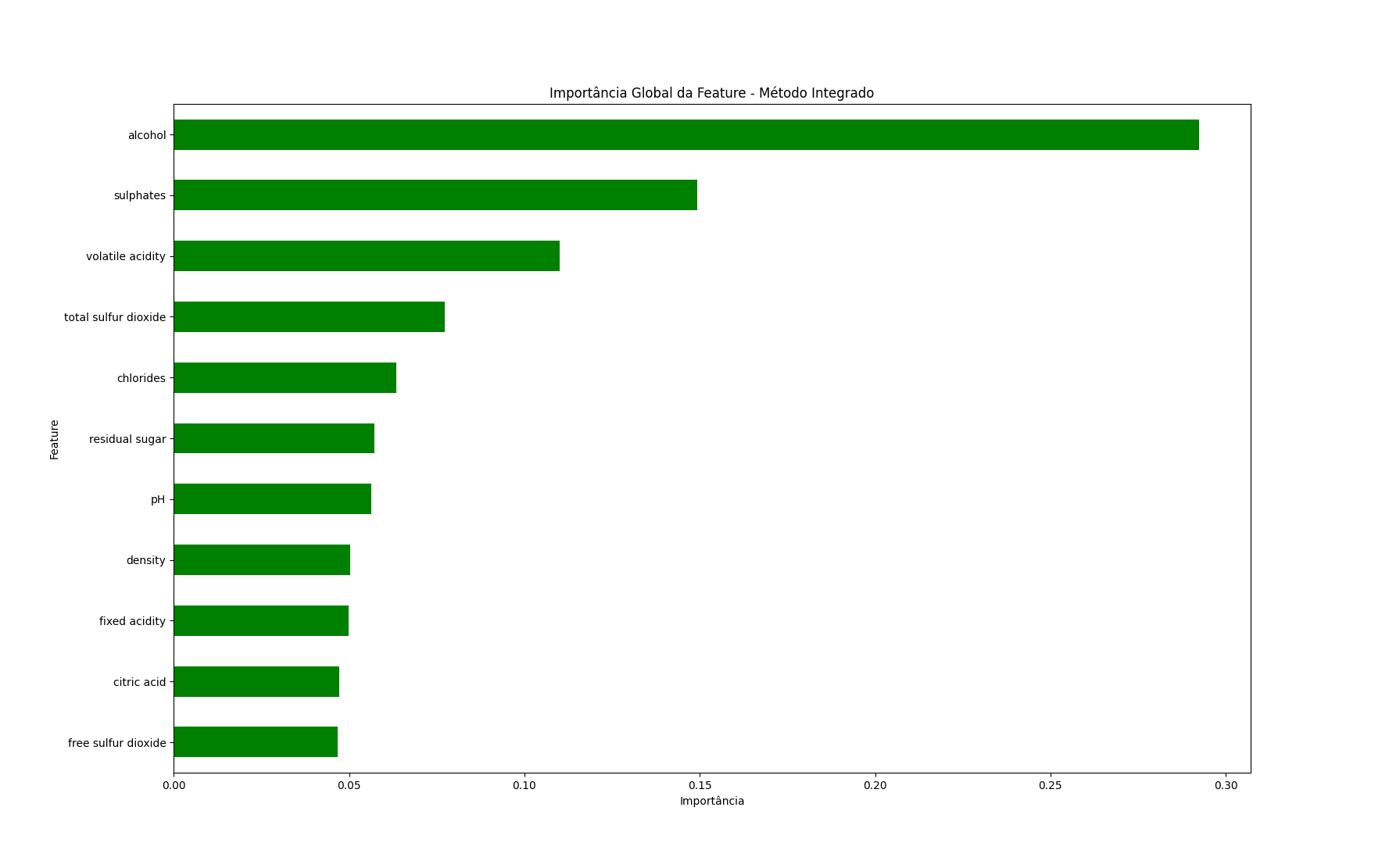
Nós apenas acessamos o atributo feature_importances_ do modelo e plotamos os resultados.
Álcool e sulfatos são as features mais importantes no modelo, de acordo com este método.
Lembre-se disso para que possamos comparar os resultados com os outros métodos.
Não existe um método único que seja o melhor, todos eles são apenas estimativas baseadas em diferentes premissas.
Uma desvantagem deste método é que ele não fornece nenhuma informação sobre a direção da relação entre a feature e o alvo.
Em outras palavras, não nos diz se mais álcool ou sulfatos estão associados a um vinho de maior qualidade ou vice-versa.
Método Embutido do Scikit-learn com uma Feature Aleatória
Uma maneira simples de tornar este método mais robusto é adicionar uma feature aleatória ao conjunto de dados e ver se ela obtém uma pontuação de importância alta.
A feature aleatória atua como um ponto de referência contra o qual a importância das features reais pode ser comparada.
Se uma feature real tiver importância menor do que a feature aleatória, isso pode indicar que sua importância se deve apenas ao acaso.
Para usar este método, basta adicionar uma coluna aleatória ao conjunto de dados e treinar novamente o modelo.
import numpy as np
X_train_random = X_train.copy()
X_train_random["RANDOM"] = np.random.RandomState(42).randn(X_train.shape[0])
rf_random = RandomForestRegressor(n_estimators=100, random_state=42)
rf_random.fit(X_train_random, y_train)
global_importances_random = pd.Series(rf_random.feature_importances_, index=X_train_random.columns)
global_importances_random.sort_values(ascending=True, inplace=True)
global_importances_random.plot.barh(color='green')
plt.xlabel("Importância")
plt.ylabel("Feature")
plt.title("Importância Global da Feature - Feature Aleatória")
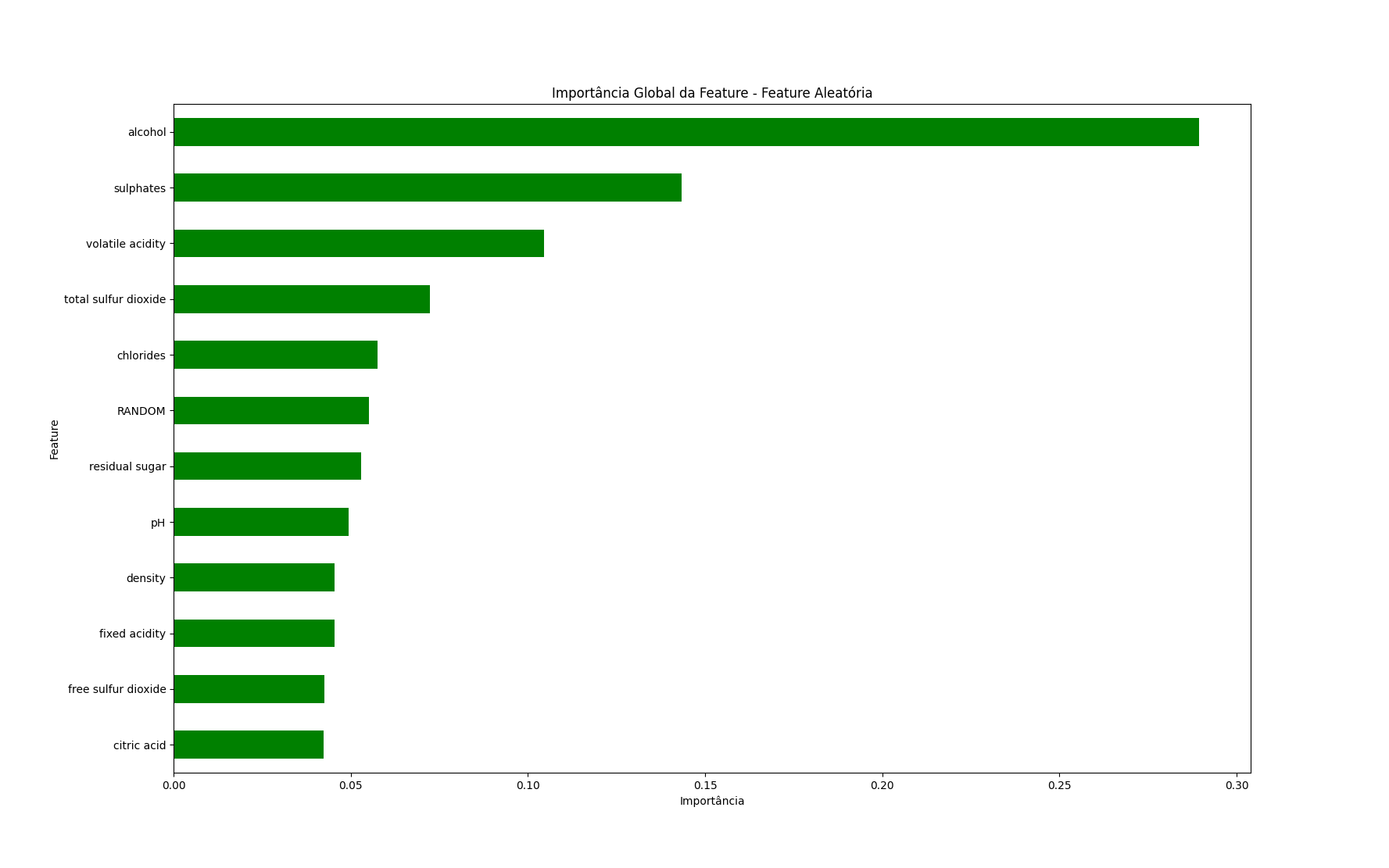
Neste caso, qualquer feature abaixo da feature aleatória, como açúcar residual, deve ser questionada.
Importância de Features por Permutação
A importância de features por permutação é outra técnica para estimar a importância de cada feature em um modelo de Random Forest, medindo a mudança no desempenho do modelo quando os valores da feature são aleatoriamente embaralhados.
A permutação é feita após o modelo ser treinado, usando um conjunto de dados fora da amostra.
Funciona seguindo estas etapas:
- Treine um modelo de machine learning usando o conjunto de dados original.
- Avalie o desempenho do modelo em um conjunto de validação e armazene a métrica de desempenho como referência (baseline).
- Para cada feature:
- Crie uma cópia do conjunto de validação e embaralhe os valores da feature selecionada.
- Avalie o desempenho do modelo no conjunto de dados embaralhado e calcule a mudança no desempenho em comparação com a baseline.
- Calcule a média da mudança no desempenho em várias iterações para obter uma estimativa estável da importância da feature.
- Classifique as features com base em suas pontuações de importância.
Uma das vantagens deste método é que ele pode ser usado com qualquer modelo, não apenas Random Forests, o que torna os resultados entre modelos mais comparáveis.
O Scikit-learn fornece uma função integrada para calculá-lo.
from sklearn.inspection import permutation_importance
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
result = permutation_importance(rf, X_test, y_test, n_repeats=10, random_state=42)
perm_importances = result.importances_mean
perm_std = result.importances_std
sorted_idx = perm_importances.argsort()
feature_names = X_test.columns
pd.DataFrame({'Importance': perm_importances, 'Std': perm_std}, index=feature_names[sorted_idx]).sort_values('Importance',ascending=True)
| Importance | Std | |
|---|---|---|
| residual sugar | 0.0103288 | 0.00391747 |
| density | 0.0131995 | 0.00419697 |
| fixed acidity | 0.0138728 | 0.00278277 |
| citric acid | 0.0183364 | 0.00271801 |
| volatile acidity | 0.022453 | 0.00639456 |
| total sulfur dioxide | 0.0225819 | 0.00862568 |
| pH | 0.0313185 | 0.0052627 |
| chlorides | 0.0576537 | 0.0100574 |
| free sulfur dioxide | 0.114513 | 0.0161098 |
| sulphates | 0.249654 | 0.02068 |
| alcohol | 0.366661 | 0.0439056 |
Temos a importância média de cada feature e o desvio padrão das pontuações de importância.
Para obter resultados mais robustos, podemos aumentar o parâmetro n_repeats, que é o número de vezes que a permutação é repetida para cada feature.
Uma desvantagem deste método é que ele pode ser muito lento para computar, especialmente para conjuntos de dados com centenas de features.
Ainda não temos uma indicação da direção da relação entre a feature e o alvo com este método.
Importância de Features em Random Forest com SHAP
SHAP é um método para interpretar a saída de modelos de machine learning com base na teoria dos jogos.
Ele fornece uma medida unificada da importância da feature que, assim como a importância da permutação, pode ser aplicada a qualquer modelo.
Obtemos pontuações de importância de features globais e locais com o SHAP.
A principal desvantagem é que ele pode ser computacionalmente caro, especialmente para conjuntos de dados grandes ou modelos complexos.
É meu método favorito porque fornece muitas informações sobre o modelo.
Para usá-lo, você precisa instalar o pacote shap com pip ou conda.
pip install shap
conda install -c conda-forge shap
Então você pode simplesmente passar o modelo para a função shap.Explainer e usar os shap_values para plotar os resultados.
Normalmente, as explicações são calculadas usando o conjunto de treinamento.
import shap
explainer = shap.Explainer(rf)
shap_values = explainer(X_train)
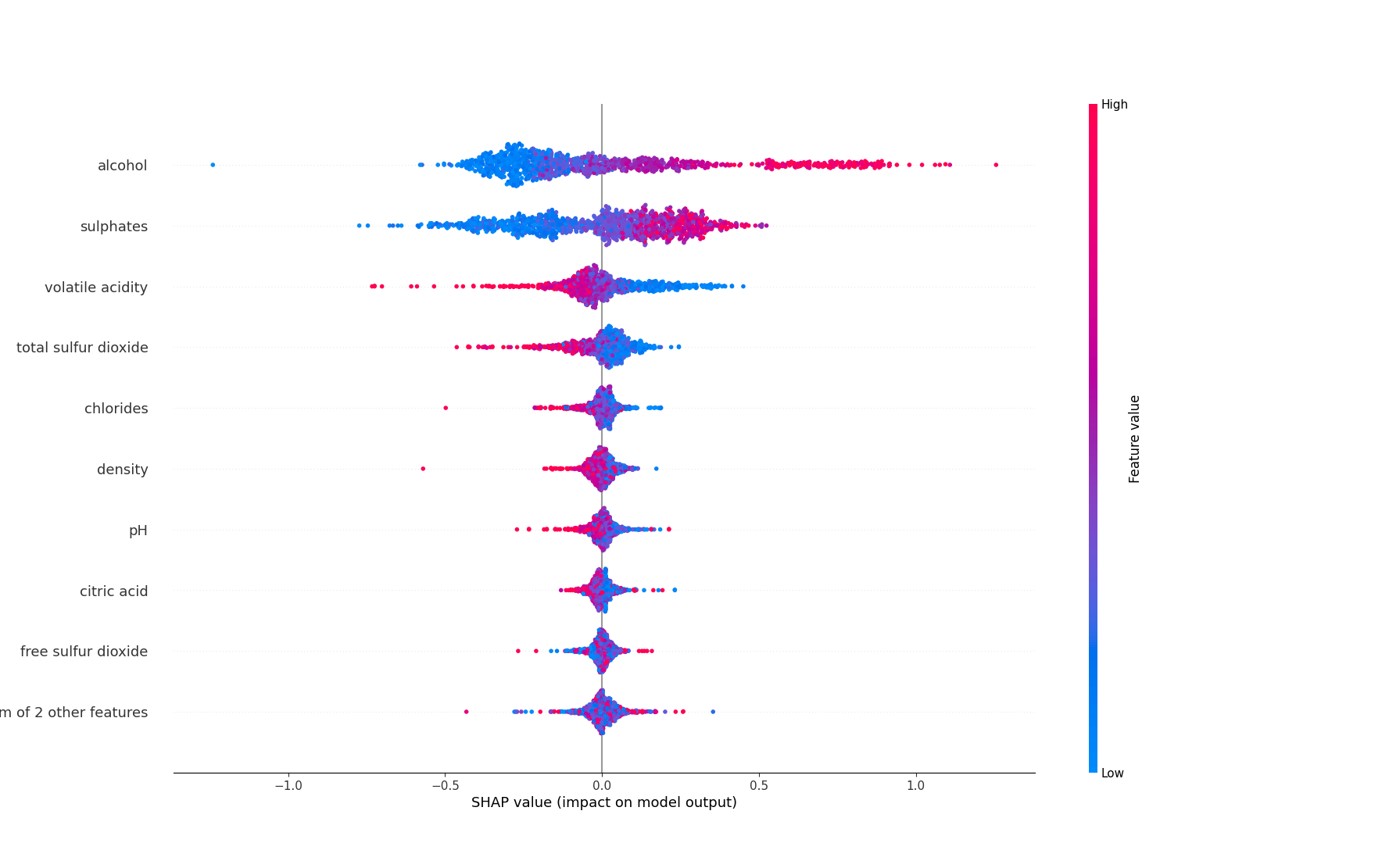
shap.plots.beeswarm(shap_values)

Além de mostrar a importância global da feature, ele também fornece a direção da relação entre a feature e o alvo.
Vamos pegar o álcool como exemplo.
Os pontos que caem à direita da linha do meio têm um impacto positivo nas previsões, enquanto os pontos à esquerda têm um impacto negativo.
Os pontos rosa são instâncias onde o valor da feature é alto, os pontos azuis são instâncias onde o valor da feature é baixo.
O álcool tem muitos pontos rosa no lado direito, o que significa que tem um impacto positivo nas previsões.
Mais álcool está associado a um vinho de qualidade superior.
A acidez volátil é o oposto, tem muitos pontos rosa no lado esquerdo, o que significa que valores mais altos desta feature estão associados a um vinho de qualidade inferior.
O SHAP também é ótimo para obter explicações locais para previsões individuais.
Importância de Features por Caminho em Random Forest
Outra forma de entender como cada feature contribui para as previsões da Random Forest é observar os caminhos da árvore de decisão que cada instância percorre.
Ele calcula a diferença entre o valor da previsão no nó terminal e os valores da previsão nos nós que o precedem para obter a contribuição estimada de cada feature.
Há uma ótima explicação deste método pelo autor do pacote treeinterpreter.
Para usá-lo em Python, você precisa instalar o pacote treeinterpreter com pip.
pip install treeinterpreter
Então você pode usar o pacote treeinterpreter para calcular as importâncias das features.
from treeinterpreter import treeinterpreter as ti
prediction, bias, contributions = ti.predict(rf, X_train)
O primeiro argumento é o modelo treinado, o segundo é o conjunto de dados.
Usarei o conjunto de treinamento aqui para manter a consistência com os outros métodos.
Você pode receber muitos avisos X has feature names, but DecisionTreeRegressor was fitted without feature names, mas não se preocupe com eles.
contributions é um array 2D com a forma (n_instances, n_features).
Para dar um exemplo, para a primeira instância, o valor na posição 0 no array prediction é o valor da previsão para aquela instância.
No array bias, é o valor médio da previsão para todas as instâncias.
E os valores na primeira linha do array contributions são as contribuições estimadas de cada feature para o valor da previsão para aquela instância.
Podemos plotar a importância global da feature calculando a média das contribuições de cada feature em todas as instâncias.
pd.Series(np.mean(contributions, axis=0), index=X_train.columns).sort_values(ascending=True).plot.barh(color='green')
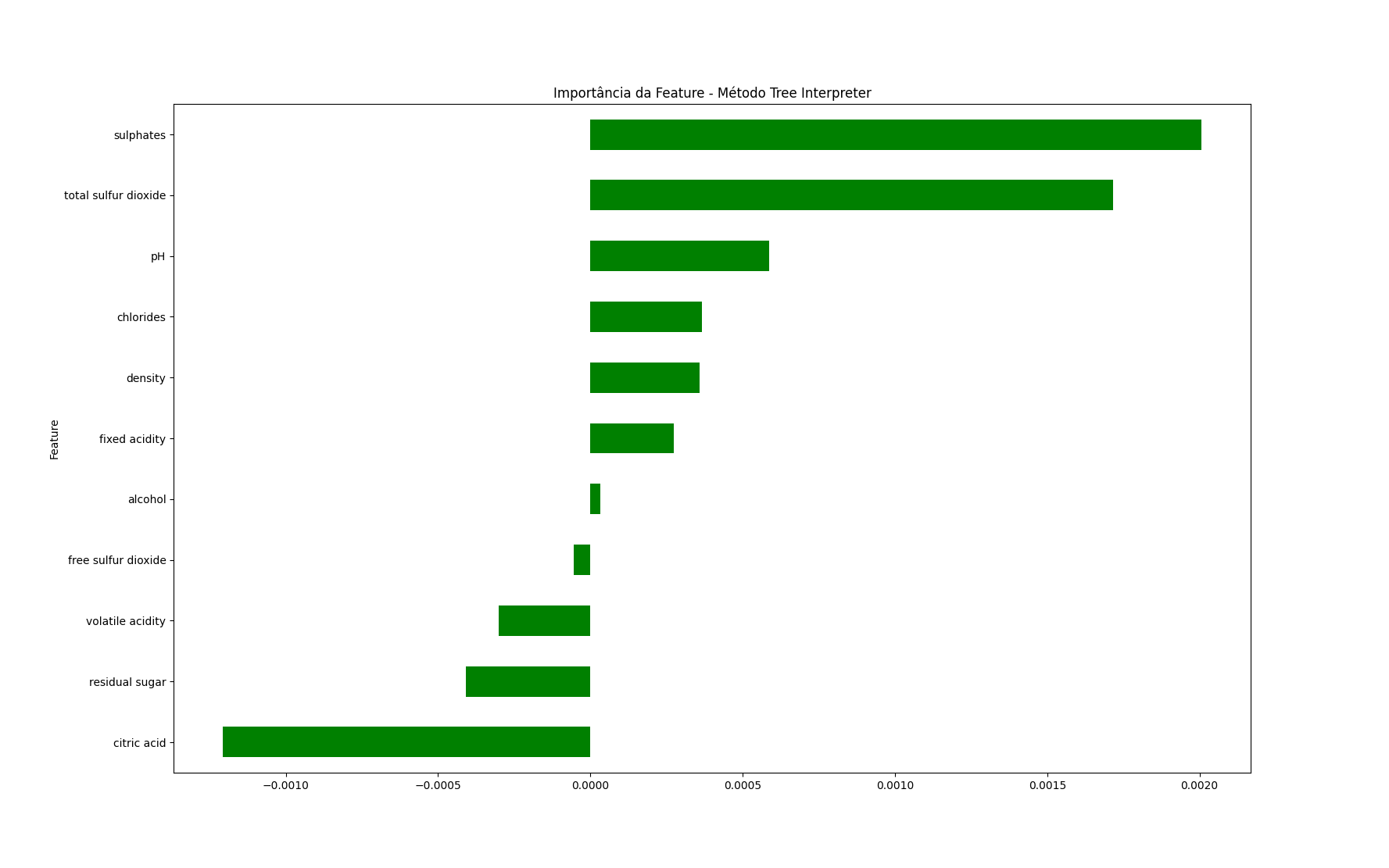
Agora suponha que queremos saber como cada feature contribui para o valor da previsão para uma instância específica para explicar por que o modelo fez uma determinada previsão.
Podemos pegar as contribuições para aquela instância e plotá-las.
prediction, bias, contributions = ti.predict(rf, X_test)
pd.Series(contributions[0], index=X_test.columns).sort_values(ascending=True).plot.barh(color='green')
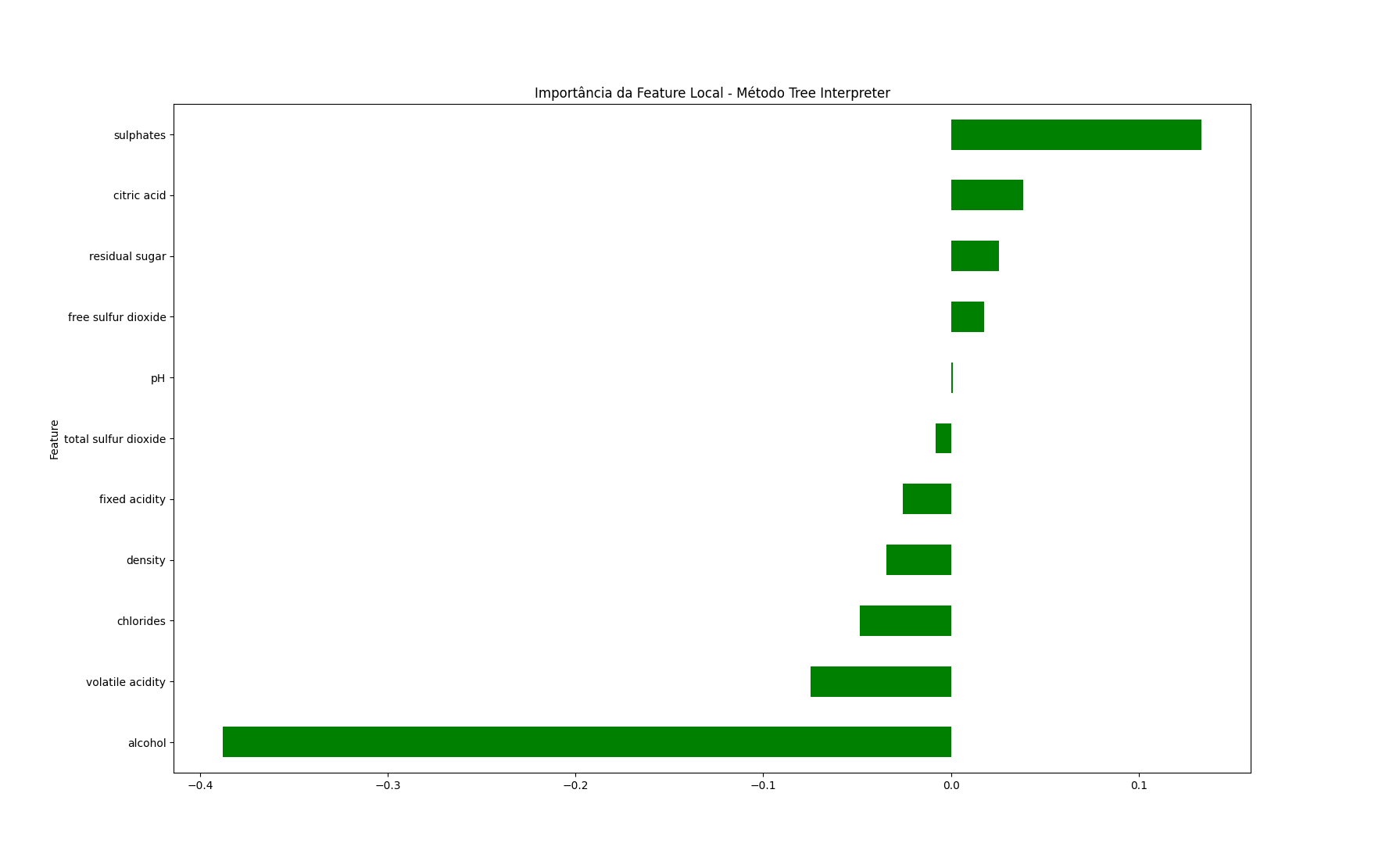
Para esta instância, a quantidade de álcool está diminuindo o valor da previsão, enquanto a quantidade de sulfatos está aumentando.
Perguntas Adicionais sobre Importância de Features em Random Forests
As técnicas descritas neste tutorial podem ser aplicadas a problemas de classificação?
Sim, as técnicas discutidas neste tutorial podem ser aplicadas a problemas de classificação também.
Como posso usar os resultados da análise de importância de features para melhorar o desempenho do meu modelo?
Você pode usar essas informações para melhorar seu modelo de várias maneiras:
- Remover features menos importantes para reduzir a complexidade do seu modelo, o que pode ajudar a evitar overfitting e melhorar a generalização.
- Encontrar novas features e fontes de dados relacionadas às features importantes.
- Tentar remover as features mais importantes para verificar se elas são realmente importantes ou vazamento de dados.
Posso usar as mesmas técnicas para outros modelos ensemble como Xgboost?
Sim, você pode usar a maioria das técnicas descritas neste tutorial para outros modelos ensemble, como XGBoost ou LightGBM.
Os conceitos de importância de features, importância de permutação e tratamento de viés de alta cardinalidade são geralmente aplicáveis a diferentes modelos baseados em árvores.
No entanto, os detalhes de implementação podem diferir dependendo do modelo específico com o qual você está trabalhando, portanto, sempre certifique-se de seguir a documentação e as diretrizes apropriadas para o modelo em questão.
Como o vazamento de dados afeta as importâncias de features em Random Forests?
Quando ocorre vazamento de dados, informações da variável alvo ou do conjunto de teste são incorporadas involuntariamente ao conjunto de treinamento, fazendo com que o modelo tenha um desempenho excepcionalmente bom nos dados de treinamento, mas ruim em dados não vistos.
Se uma feature com vazamento estiver altamente correlacionada com a variável alvo, o modelo Random Forest pode atribuir alta importância a essa feature, mesmo que ela não seja genuinamente preditiva.
Isso pode levar a uma falsa sensação de confiança no desempenho do modelo e na importância da feature com vazamento.
Por outro lado, como a feature com vazamento domina o processo de tomada de decisão do modelo, outras features genuinamente preditivas podem receber menor importância, tornando difícil identificar suas verdadeiras contribuições para o desempenho do modelo.
Um truque que aprendi no Kaggle, conforme sugerido em uma pergunta anterior, é tentar remover as features mais importantes para verificar se elas são realmente importantes ou artefatos de vazamento de dados.
A lógica por trás dessa abordagem é que, se uma feature for genuinamente importante, removê-la deve levar a uma queda significativa no desempenho do modelo.
Se a remoção da feature melhorar o desempenho do modelo, é muito provável que não seja uma melhoria genuína, mas sim um resultado de vazamento de dados.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.