
A API do Claude, desenvolvida pela Anthropic, oferece uma alternativa poderosa aos modelos de linguagem da OpenAI.
Eu gosto bastante de usar o Claude, porque ele soa mais natural do que o GPT-4 e costuma me dar respostas melhores quando uso com tarefas de programação e ciência de dados.
Ele fez 90% do trabalho de criar esse app sobre active learning em machine learning, usando React, que eu nunca tinha estudado.
Ela não é tão conhecida quanto a API da OpenAI aqui no Brasil, então é uma vantagem competitiva para quem quer explorar novas possibilidades com modelos de linguagem avançados.
Este artigo guiará você através dos passos necessários para começar a usar a API do Anthropic Claude em Python.
O Que É O Claude?
No cenário atual da inteligência artificial generativa, diversas empresas oferecem modelos de linguagem avançados.
Enquanto a OpenAI é conhecida pelo GPT-4, a Anthropic se destaca com o Claude, a Cohere oferece o Command-R, e o Google apresenta o Gemini.
Cada empresa possui suas próprias abordagens para desenvolver e disponibilizar esses modelos.
O Claude, criado pela Anthropic, é um assistente de IA altamente capaz que teve sua mais recente família de modelos lançada em 2024.
A versão mais recente, Claude 3.5 Sonnet, representa um avanço significativo em termos de capacidades e desempenho.
Este modelo estabeleceu novos padrões na indústria para raciocínio, conhecimento de nível universitário e proficiência em programação.
Uma das características marcantes do Claude 3.5 Sonnet é sua compreensão aprimorada de nuances, humor e instruções complexas.
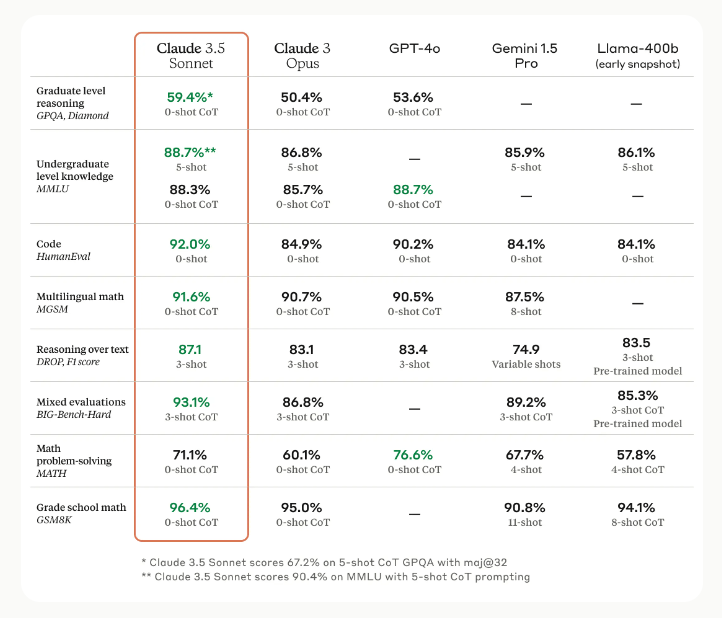
Isso se reflete em sua capacidade de produzir conteúdo de alta qualidade com um tom natural e envolvente.
Além disso, sua velocidade de operação, duas vezes maior que seu predecessor, o torna ideal para tarefas complexas como suporte ao cliente e orquestração de fluxos de trabalho.
Os modelos Claude 3, assim como seus concorrentes, são multimodais.
Isso significa que eles aceitam tanto texto quanto imagens como entrada, permitindo interações mais ricas e contextuais.
Uma das críticas à Anthropic é que sua política de segurança pode ser rigorosa demais e causar muitas falsos positivos expressados através da rejeição do modelo em responder em situações inofensivas.
Eles trabalham bastante para melhorar a precisão do modelo em reconhecer situações de risco real, mas ainda há espaço para melhorias.
Crie Uma Conta Na Anthropic
O primeiro passo para utilizar a API do Claude é criar uma conta na Anthropic.
Para criar sua conta, visite o site do Console da Anthropic e siga as instruções para se registrar.
Você pode se cadastrar com seu endereço de e-mail ou usar uma conta do Google para facilitar o processo de registro.
Eles também exigem a confirmação do cadastro via telefone, então esteja preparado para receber um código de verificação por SMS.
Gere Uma API Key
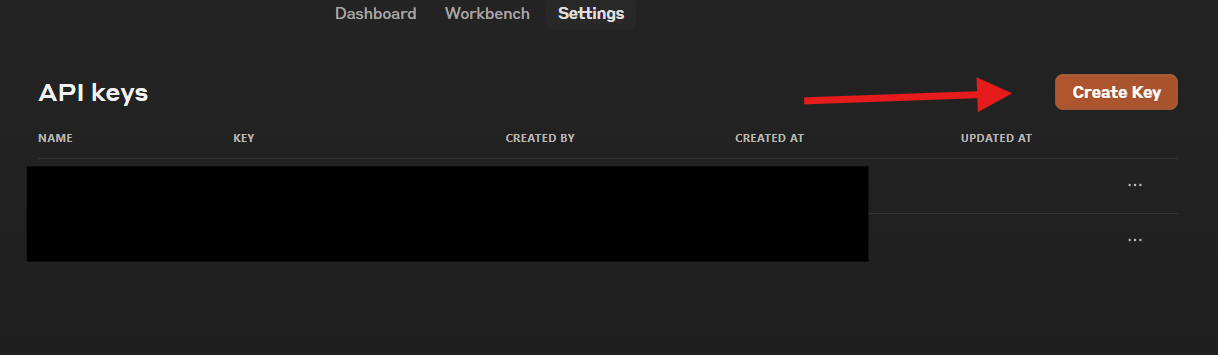
Depois de criada sua conta, você precisará gerar uma API key para autenticar suas solicitações à API do Claude.
Para gerar sua API key:
-
Visite a página de API keys no Console da Anthropic.
-
Clique no botão “Create Key”
- Digite um nome descritivo para sua chave e pressione “Create Key”.
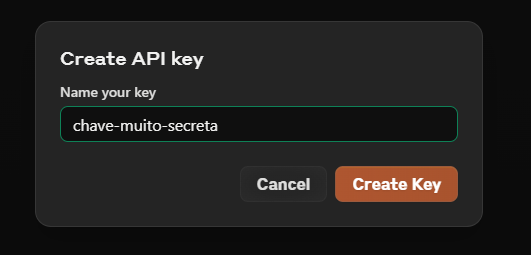
- Copie a chave gerada e armazene-a de forma segura. Se você perder a chave, precisará gerar uma nova.
IMPORTANTE: Trate sua API key como uma senha. Nunca a compartilhe publicamente ou a inclua diretamente no código-fonte que possa ser compartilhado ou versionado publicamente.
Configure a Variável de Ambiente
Configurar a API key como uma variável de ambiente é uma prática de segurança recomendada, pois evita que você acidentalmente exponha sua chave no código-fonte.
Para configurar a variável de ambiente:
No Linux ou macOS:
export ANTHROPIC_API_KEY='sua_api_key_aqui'
No Windows (Prompt de Comando):
setx ANTHROPIC_API_KEY=sua_api_key_aqui
No Windows (PowerShell):
$env:ANTHROPIC_API_KEY = 'sua_api_key_aqui'
Para tornar esta configuração permanente, você pode adicionar esta linha ao seu arquivo de perfil do shell (como .bashrc, .zshrc, ou o script de inicialização do PowerShell).
No Windows, você também pode definir variáveis de ambiente permanentes através do Painel de Controle.
Instale a Biblioteca da Anthropic para Python
A biblioteca oficial da Anthropic para Python simplifica significativamente a interação com a API do Claude.
Para instalar a biblioteca via pip, execute o seguinte comando:
pip install anthropic
Certifique-se de que você está usando uma versão recente do Python (recomenda-se Python 3.7 ou superior) e considere usar um ambiente virtual para isolar as dependências do projeto.
Exemplo Básico de Uso Para Gerar Texto Com o Claude
Aqui está um exemplo simples e explicado de como usar a API do Claude para gerar texto:
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-3-5-sonnet-20240620",
messages=[{
"role": "user",
"content": [{
"type": "text",
"text": "O que é inteligência artificial?"
}]
}]
)
print(response.content)
Inicialmente, o código importa a biblioteca Anthropic, que fornece uma interface para interagir com os modelos de IA da Anthropic.
Em seguida, cria-se uma instância do cliente Anthropic, que será utilizada para fazer chamadas à API.
A parte principal do código envolve a criação de uma mensagem para enviar ao modelo Claude.
Isso é feito usando o método messages.create do cliente.
O modelo especificado é claude-3-5-sonnet-20240620, que é a versão mais recente do Claude 3.5 Sonnet na data de publicação deste artigo.
A estrutura da mensagem é composta por uma lista de dicionários, onde cada dicionário representa uma parte da conversa.
Neste caso, há apenas uma mensagem do usuário.
O campo role indica se a mensagem é do usuário ou do assistente, e o campo content contém o conteúdo da mensagem.
O conteúdo, por sua vez, é uma lista com um único dicionário, especificando o tipo de conteúdo como text e o texto da pergunta: “O que é inteligência artificial?”.
Pode parecer estranho precisar especificar o tipo de conteúdo como text, mas isso é necessário porque podemos enviar outros tipos de conteúdo, como imagens, para o modelo Claude.
Após enviar a mensagem, o código armazena a resposta do modelo na variável response.
Finalmente, o conteúdo da resposta é impresso na tela usando a função print, acessando o atributo content do objeto de resposta.
Anatomia De Uma Resposta Da API
Vamos dar uma olhada mais detalhada na estrutura de uma resposta da API do Claude e entender os parâmetros mais importantes.
{
"id": "msg_01XFDUDYJgAACzvnptvVoYEL",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "Hello!"
}
],
"model": "claude-3-5-sonnet-20240620",
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 12,
"output_tokens": 6
}
}
Começamos com o campo id. Este é um identificador único para a mensagem gerada.
Ele pode ser muito útil se você precisar referenciar esta resposta específica no futuro, especialmente em aplicações que mantêm um log de mensagens.
Em seguida, temos o role, que indica quem enviou esta mensagem.
Aqui, é assistant, mostrando que esta é a resposta do Claude, não uma entrada do usuário.
O núcleo da resposta está no campo content.
É aqui que encontramos o texto real gerado pelo Claude.
Observe que o conteúdo é fornecido como uma lista, onde cada item é um objeto com um type e o conteúdo em si.
Neste exemplo, temos apenas texto, mas pode ser que no futuro o Claude retorne também imagens e outros tipos de conteúdo.
O campo model nos informa qual versão do Claude foi usada para gerar esta resposta.
Isso pode ser útil para rastrear o desempenho de diferentes modelos ou garantir consistência em suas aplicações.
stop_reason nos informa por que o Claude parou de gerar texto.
Neste caso, end_turn significa que o Claude considerou que completou sua resposta naturalmente.
Um outro valor comum é max_tokens, que indica que o Claude atingiu o limite máximo de tokens definido para a resposta ou o limite geral do modelo.
Por fim, temos o campo usage.
Ele nos fornece informações sobre os tokens usados tanto na entrada quanto na saída.
Isso é particularmente útil para monitorar o uso da API e os custos associados, já que muitos provedores de API cobram com base no número de tokens processados.
Parâmetros Mais Importantes Para a API do Claude
Mensagens
O parâmetro messages é uma lista de dicionários que representa a conversa.
Cada mensagem inclui uma role (que pode ser “user” ou “assistant”) e um content que representa o texto da mensagem.
messages=[
{"role": "user", "content": "Olá, pode me falar sobre inteligência artificial?"},
{"role": "assistant", "content": "Claro! A inteligência artificial (IA) é um campo da ciência da computação..."},
{"role": "user", "content": "Interessante. E quais são as aplicações práticas da IA?"}
]
Temperatura
A temperature é um parâmetro que controla a aleatoriedade ou “criatividade” das respostas do modelo. Varia de 0 a 1:
- Valores mais baixos (próximos a 0) produzem respostas mais determinísticas e focadas.
- Valores mais altos (próximos a 1) aumentam a variabilidade e potencial criatividade das respostas.
Exemplo:
response = client.completions.create(
model="claude-3-5-sonnet-20240620",
prompt="Gere um slogan criativo para uma empresa de tecnologia",
temperature=0.7 # Aumenta a criatividade da resposta
)
Escolha a temperatura com base no seu caso de uso: use valores baixos para tarefas que requerem precisão (como classificação de dados) e valores mais altos para tarefas criativas (como brainstorming).
Em termos técnicos, a temperatura mais alta suaviza a distribuição de probabilidade da resposta do modelo, tornando esta distribuição mais uniforme.
Max Tokens
max_tokens limita o número máximo de tokens na resposta gerada.
Isso é importante em casos como classificação binária, onde basta apenas um token para indicar se a resposta é positiva ou negativa.
Exemplo:
response = client.completions.create(
model="claude-3-5-sonnet-20240620",
prompt="Resuma a história da internet",
max_tokens=150 # Limita a resposta a aproximadamente 150 palavras
)
Conversas Com Múltiplas Mensagens (Multi-Turno)
No momento em que este artigo foi publicado, o Claude 3.5 Sonnet é o modelo com melhor avaliação para conversas multi-turno na LMSys Arena Leaderboard.
As conversas multi-turno são fundamentais para criar interações mais naturais e contextualizadas com modelos de IA.
Uma das principais vantagens é a contextualização aprimorada: o modelo pode se lembrar de informações fornecidas em mensagens anteriores, permitindo respostas mais precisas e relevantes ao longo da conversa.
Além disso, as conversas multi-turno permitem um refinamento progressivo das ideias.
Os usuários podem fazer novas perguntas ou pedir esclarecimentos, levando a respostas mais detalhadas e personalizadas.
Isso é especialmente valioso em cenários de atendimento ao cliente ou suporte técnico, onde a compreensão do contexto e a capacidade de fazer novas perguntas são cruciais.
Gosto de usar este recurso quando estou programando ou escrevendo um artigo mais longo (como este).
Em vez de tentar resolver o problema todo de uma vez, você pode dividir o problema em partes menores e trabalhar em um pedaço de cada vez, o que tende a funcionar melhor com modelos de linguagem.
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1000,
messages=[
{"role": "user", "content": "Olá, como você está?"},
{"role": "assistant", "content": "Olá! Estou bem, obrigado por perguntar. Como posso ajudar você hoje?"},
{"role": "user", "content": "Pode me explicar o que é machine learning?"},
{"role": "assistant", "content": "Claro! Machine Learning, ou Aprendizado de Máquina, é uma subárea da Inteligência Artificial..."},
{"role": "user", "content": "Interessante. Quais são algumas aplicações práticas do machine learning?"}
]
)
print(response.content)
Note que nossa lista de mensagens agora possui tanto as mensagens do usuário quanto as mensagens do assistente.
Num diálogo real, você vai acumulando mensagens do usuário e do assistente, e passando essa lista para a API.
Uma observação importante é que nem sempre precisamos usar o argumento type ao passar as mensagens, o que pode tornar o código um pouco mais limpo.
Moldando as Respostas do Claude com Pré-preenchimento
O pré-preenchimento é uma técnica poderosa que permite direcionar as respostas do Claude de forma mais precisa.
Este método te permite fornecer o início da resposta do Claude na mensagem do assistant, orientando-o sobre como continuar a resposta.
Vamos ver como isso pode ser usado para “garantir” que o Claude responda em um formato específico, como JSON.
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=1024,
messages=[
{"role": "user", "content": "Descreva um carro esportivo."},
{"role": "assistant", "content": '{\n "tipo": "carro esportivo",\n "características": {'} # Pré-preenchimento aqui
]
)
print(response.content[0].text)
Neste exemplo, o pré-preenchimento faz duas coisas importantes:
- Inicia a resposta com uma estrutura JSON válida
- Define as chaves iniciais, orientando o Claude sobre o tipo de informação esperada
Ao usar o pré-preenchimento desta forma, você praticamente garante que o Claude continuará a resposta no formato JSON, fornecendo detalhes sobre o carro esportivo dentro da estrutura estabelecida.
(Nada é realmente garantido com esses modelos, mas vamos dizer que isso reduz bastante a frequência de respostas mal formatadas.)
Esta técnica pode ser adaptada para diversos cenários onde um formato de saída específico é necessário, como geração de dados estruturados, criação de configurações ou qualquer situação onde uma resposta em formato livre não seja adequada.
Estruturando Seus Prompts com Tags XML
Outra técnica útil para estruturar seus prompts para o Claude é o uso de tags XML.
Isso ajuda a delimitar claramente diferentes partes do seu prompt, tornando mais fácil para o Claude entender e processar a informação.
Veja um exemplo:
import anthropic
client = anthropic.Anthropic()
prompt = """
<instrução>
Analise o seguinte texto e forneça um resumo dos principais pontos em formato de lista.
</instrução>
<texto>
A inteligência artificial (IA) tem revolucionado diversos setores da sociedade. Na medicina,
sistemas de IA auxiliam no diagnóstico precoce de doenças. Na indústria, robôs inteligentes
otimizam a produção. No setor financeiro, algoritmos de aprendizado de máquina preveem
tendências de mercado. Apesar dos benefícios, a IA também levanta questões éticas sobre
privacidade e substituição de empregos humanos.
</texto>
<formato>
Ponto 1
Ponto 2
Ponto 3
...
</formato>
"""
response = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=300,
messages=[
{"role": "user", "content": prompt}
]
)
print(response.content[0].text)
Neste exemplo, usamos tags XML para separar claramente a instrução, o texto a ser analisado e o formato desejado da resposta.
A tag <instrução> contém orientações específicas para o Claude sobre o que fazer com o texto.
A tag <texto> delimita o conteúdo que deve ser analisado, enquanto a tag <formato> indica como a resposta deve ser estruturada.
Ao usar esta abordagem, você melhora a clareza do seu prompt, tornando mais fácil para o Claude entender exatamente o que você está pedindo.
Além disso, facilita a modificação e reutilização de partes específicas do prompt.
Isso também aumenta a consistência das respostas, especialmente quando você precisa de um formato específico.
Estabelecendo um Papel para o Claude (System Prompt)
Role Prompting é uma técnica usada em engenharia de prompts onde você define um papel ou persona específica para o modelo assumir durante a interação.
No exemplo abaixo, o papel atribuído é o de um cientista de dados experiente em uma empresa Fortune 500.
Esta técnica é particularmente útil quando você deseja que o modelo responda de uma maneira específica, com um conjunto particular de conhecimentos, habilidades ou perspectivas.
Ao definir o papel, você está essencialmente moldando o contexto no qual o modelo interpretará e responderá às entradas subsequentes.
No código exemplo, o Role Prompting é implementado através do parâmetro “system” na chamada da API.
A linha system="Você é um cientista de dados experiente em uma empresa Fortune 500" instrui o modelo Claude a assumir o papel de um cientista de dados experiente.
import anthropic
client = anthropic.Anthropic()
resposta = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=2048,
system="Você é um cientista de dados experiente em uma empresa Fortune 500.", # <-- role prompt
messages=[
{"role": "user", "content": "Analise este conjunto de dados em busca de anomalias: <dataset>{{CONJUNTO_DE_DADOS}}</dataset>"}
]
)
print(resposta.content)
Ao usar o Role Prompting desta maneira, você está incentivando o modelo a responder como um cientista de dados experiente faria.
Isso significa que a análise do conjunto de dados em busca de anomalias será realizada com o nível de expertise e o tipo de insights que se esperaria de um profissional altamente qualificado nessa área.
Esta abordagem pode resultar em respostas mais relevantes e específicas para o domínio em questão.
O modelo pode usar terminologia mais técnica, focar em aspectos importantes para cientistas de dados e fornecer uma análise mais aprofundada e sofisticada do que faria sem essa instrução de papel.
Em alguns casos ela também melhora a qualidade das respostas.
Lidando Com Erros e Exceções
A biblioteca da Anthropic possui exceções específicas que você deve capturar e tratar adequadamente.
Estas são as mais importantes em geral:
try:
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=1000,
messages=[{"role": "user", "content": "Olá Claude!"}]
)
print(response.content)
except APIConnectionError as e:
print(f"Erro de conexão com a API: {e}")
# Aqui você pode implementar uma lógica de retry ou notificar o usuário sobre problemas de conectividade
except APITimeoutError as e:
print(f"A requisição excedeu o tempo limite: {e}")
# Considere aumentar o timeout ou dividir a tarefa em partes menores
except RateLimitError as e:
print(f"Limite de requisições excedido: {e}")
# Implemente uma lógica de backoff ou informe o usuário sobre o limite atingido
Neste exemplo, diferentes tipos de exceções são tratados de forma específica.
O APIConnectionError é utilizado para lidar com problemas de conectividade de rede, permitindo que você implemente lógicas de retry ou notifique o usuário sobre problemas de conexão.
O APITimeoutError trata casos onde a requisição leva muito tempo para ser processada.
Eles tendem a ser maiores nos dias após o lançamento de modelos novos, por causa do novo interesse de várias pessoas em testá-los em suas aplicações.
Nessas situações, você pode considerar aumentar o timeout.
Para situações onde o limite de requisições foi atingido, o RateLimitError é utilizado.
Este limite muda conforme você vai usando (e pagando) a API.
Seja o primeiro a saber das novidades em Machine Learning. Me siga no LinkedIn.