During a technical meeting a few weeks ago, we had a discussion about feature interactions, and how far we have to go with them so that we can capture possible relationships with our targets.
Should we create (and select) arithmetic interactions between our features?
A few years ago I remember visiting a website that showed how different models approximated these simple operations. It went from linear models to a complex Random Forest.
One of the most powerful and deployed complex model we have today is Gradient Boosted Decision Trees. We have LightGBM, XGBoost, CatBoost, SKLearn GBM, etc. Can this model find these interactions by itself?
As a rule of thumb, that I heard from a fellow Kaggle Grandmaster years ago, GBMs can approximate these interactions, but if they are very strong, we should specifically add them as another column in our input matrix.
It’s time to upgrade this rule, do an experiment and shed some light on how effective this class of models really are when dealing with arithmetic interactions.
What Do The Interactions Look Like?
Let’s use simple two-variable interactions for this experiment, and visually inspect how the model does. Here I want to try the four operations: addition, subtraction, multiplication and division.
This is what they look like on a -1 to 1 grid.
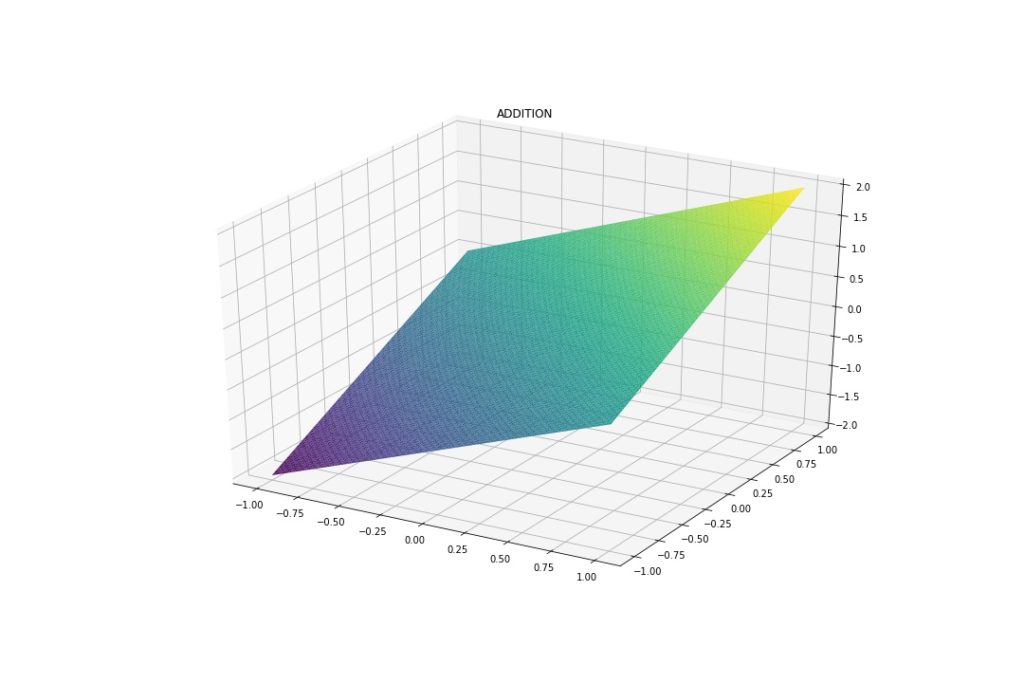
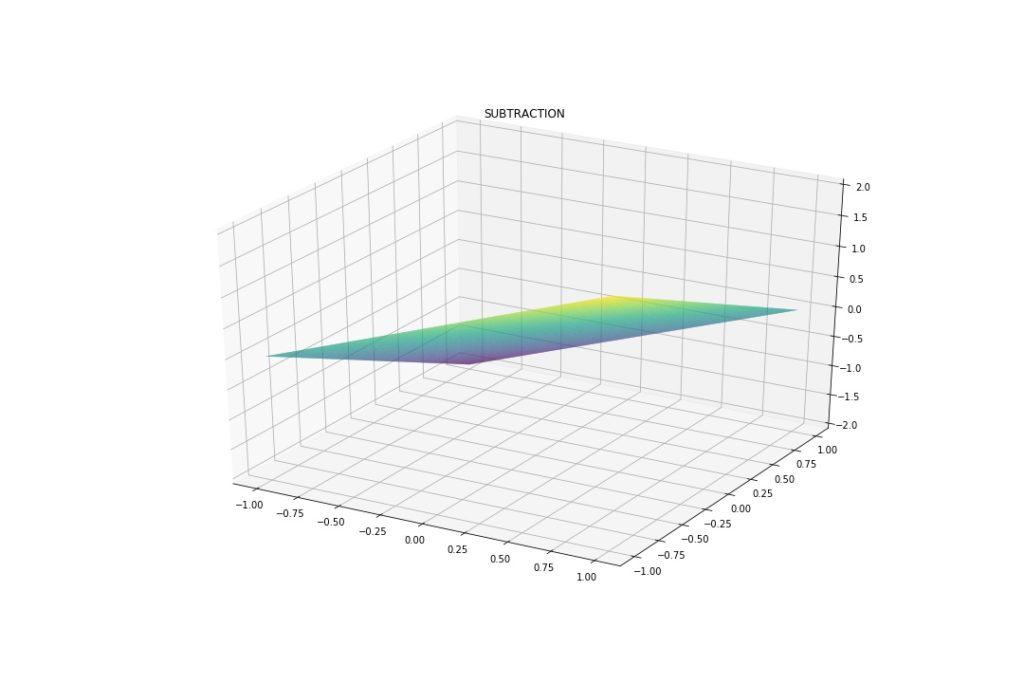
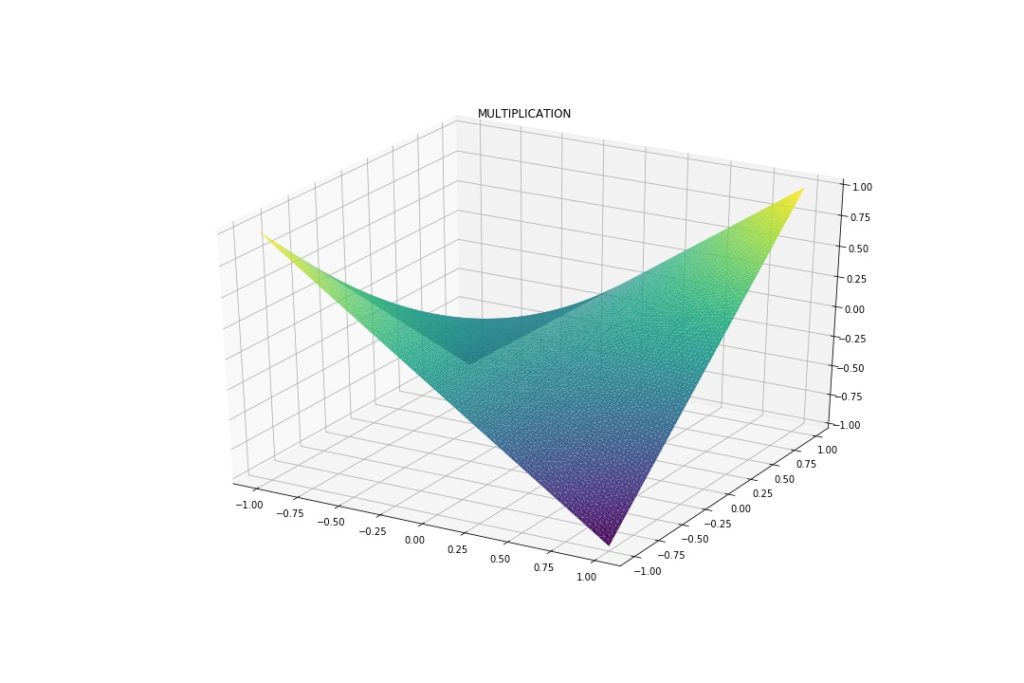
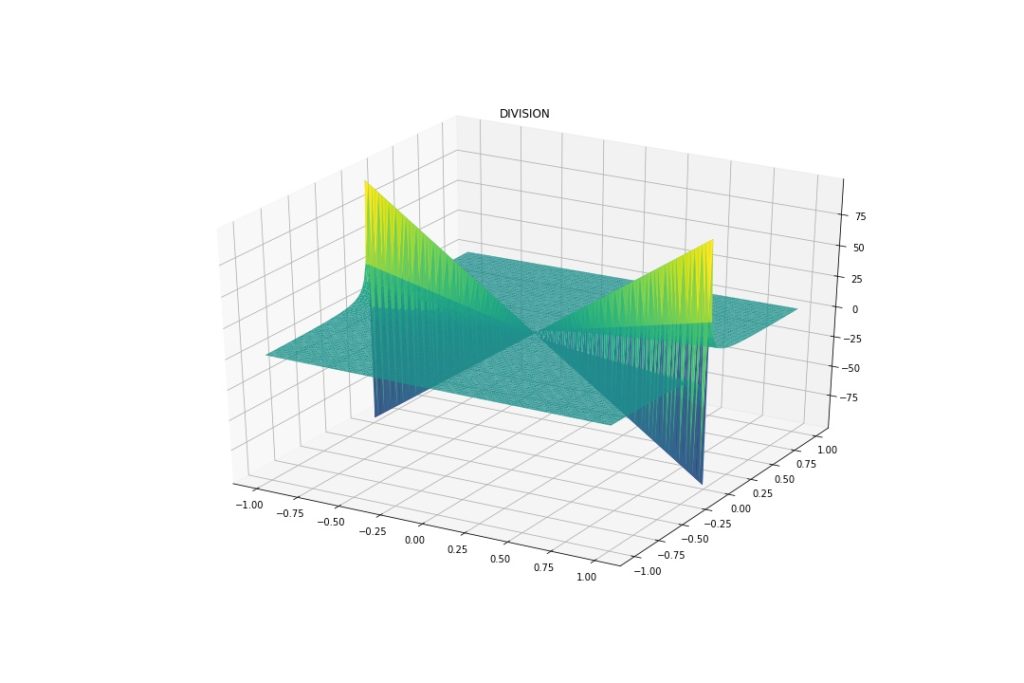
As expected, Addition and Subtraction are linear. Multiplication and Division have non-linear parts. These will serve as a reference.
Bring on XGBoost
Because of its popularity and mechanism close to the original implementation of GBM, I chose XGBoost. There should not be many differences to the results using other implementations.
I generated a dataset with 10.000 numbers, that covers the grid we plotted above. As we are studying the behavior of the model here, I didn’t care about a validation split. After all, if the model can’t capture the pattern on training, test is doomed anyway.
Zero Noise
Let’s start with an “easy” scenario. Zero noise, Y is exactly the operation applied on X1 and X2. E.g.: X1 + X2 = Y.
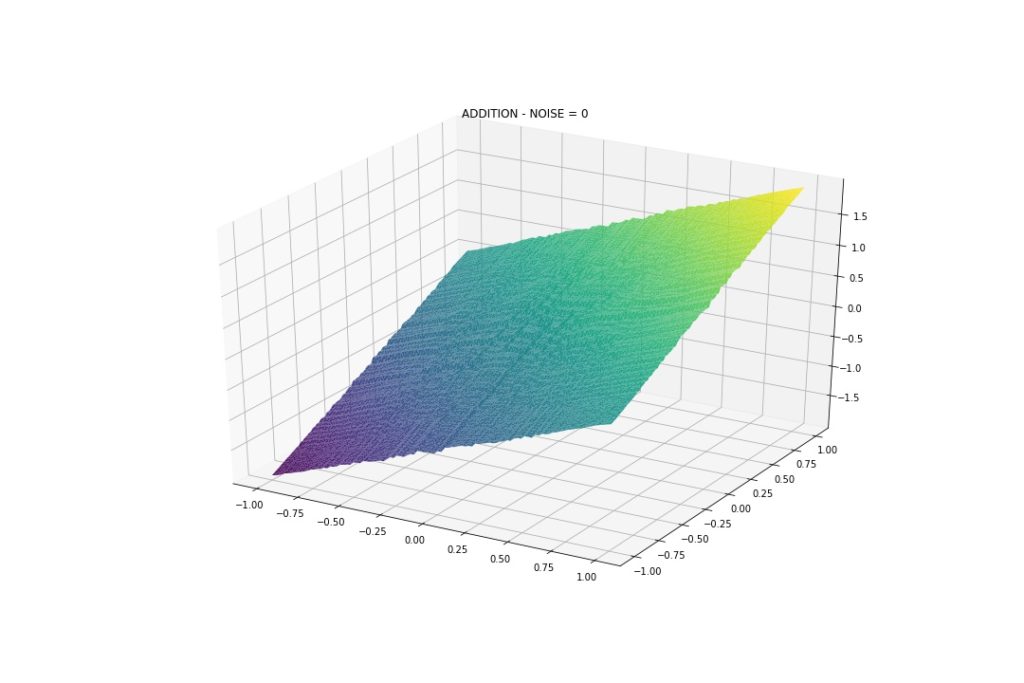
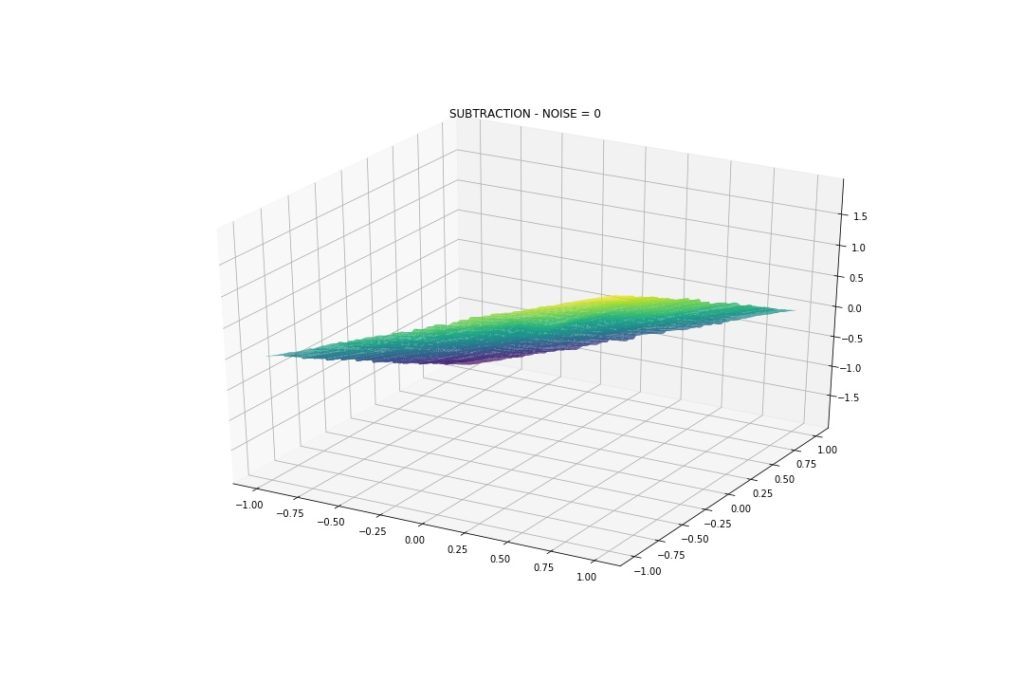
Addition and Subtraction have some wiggles, because we are approximating the interaction, not perfectly modeling it, but it seems fine. I would say the model did a good job.
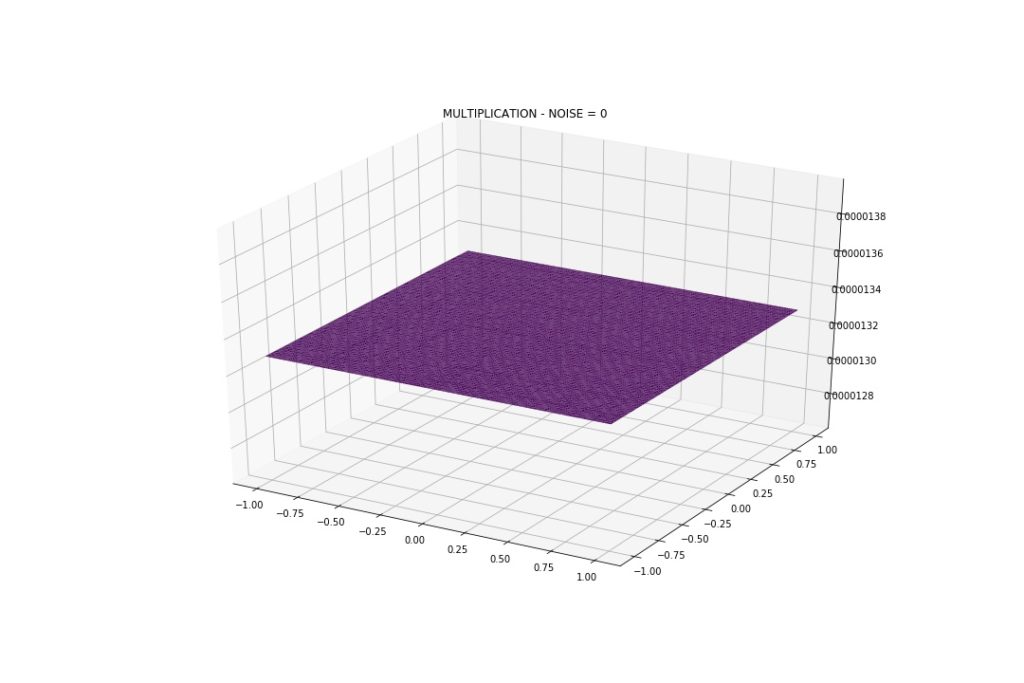
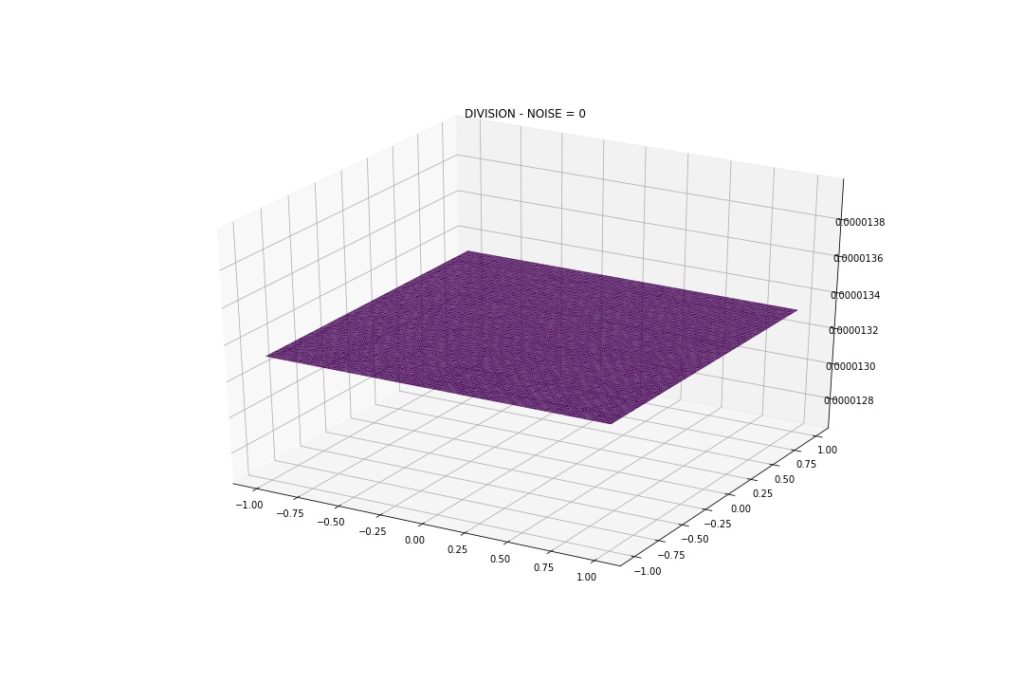
Now… what the heck is going on with Multiplication and Division?
The model was not able to capture the pattern. Predictions are constant. I tried the following, without success:
- Changing the range
- Multiplying Y by a big constant
- Using XGBRegressor implementation vs xgb.train
- Changing hyperparameters
We should find why this happens. If anyone knows, please comment. I opened an issue on GitHub.
**ANSWER: **Jiaming Yuan and Vadim Khotilovich from the XGB team investigated the issue, and Vadim wrote: “it’s not a bug. But it’s a nice example of data with “perfect symmetry” with unstable balance. With such perfect dataset, when the algorithm is looking for a split, say in variable X1, the sums of residuals at each x1 location of it WRT X2 are always zero, thus it cannot find any split and is only able to approximate the total average. Any random disturbance, e.g., some noise or subsample=0.8 would help to kick it off the equilibrium and to start learning.”
Thank you for the answer. Now we can keep this in mind if the model is acting stubbornly.
Is There Life Without Noise?
It’s very, very hard for us to have a dataset with noise (that we know of or not). So let’s see how the model performs when we add a bit of random normal noise.
Gaussian Noise: Mean 0, StDev 0.5
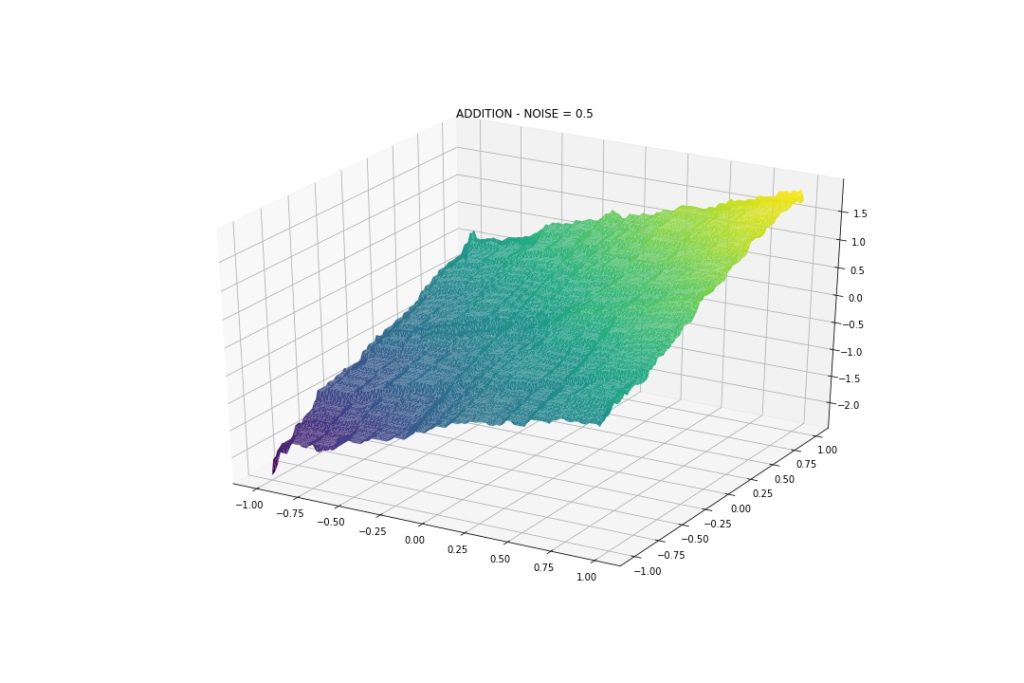
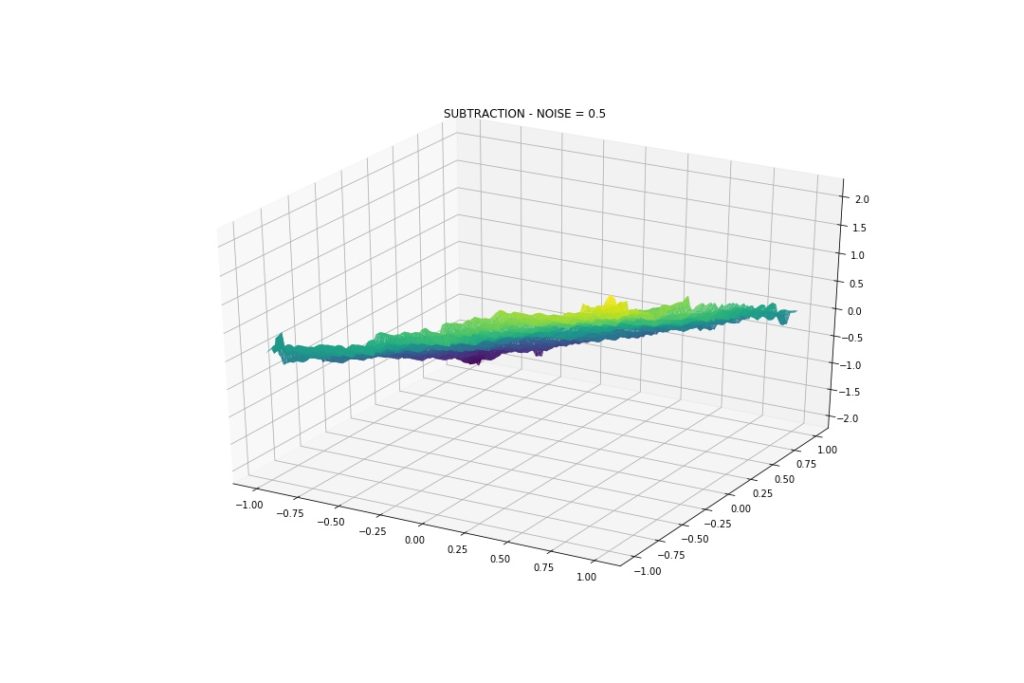
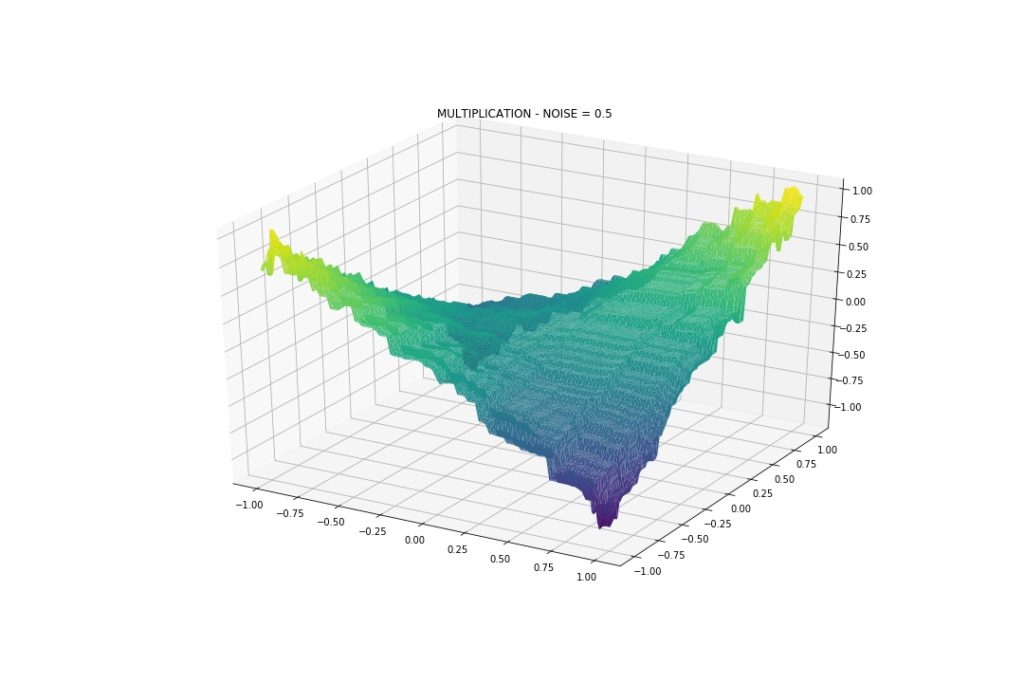
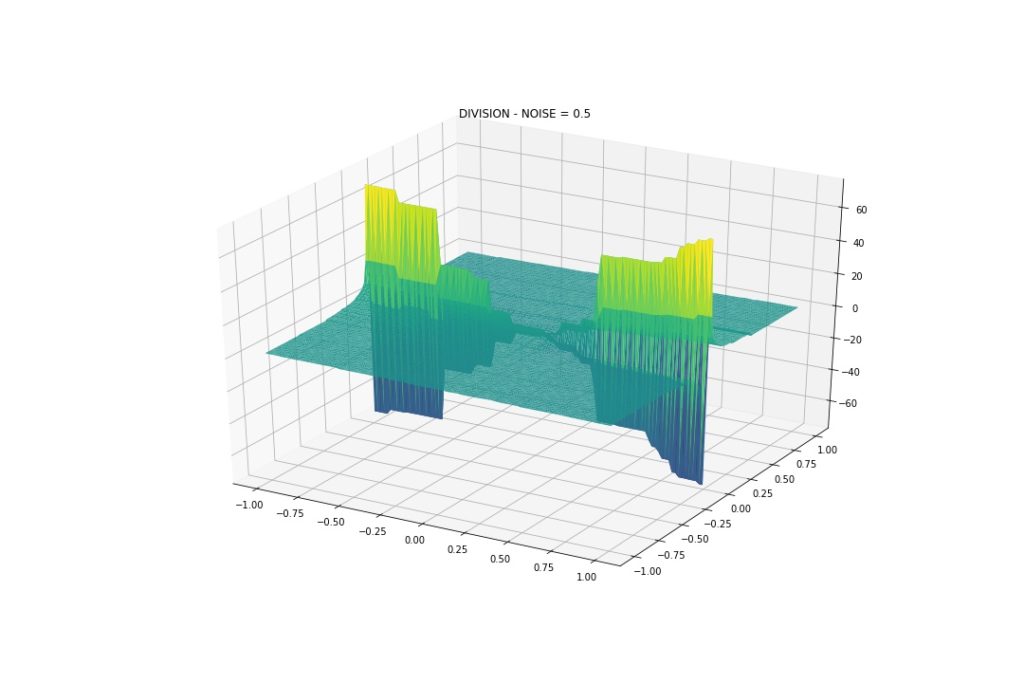
With this amount of noise we see that the model can approximate the interactions, even division and multiplication. Back to our topic, although wiggly, we see that the model indeed can capture such patterns.
Gaussian Noise: Mean 0, StDev 1
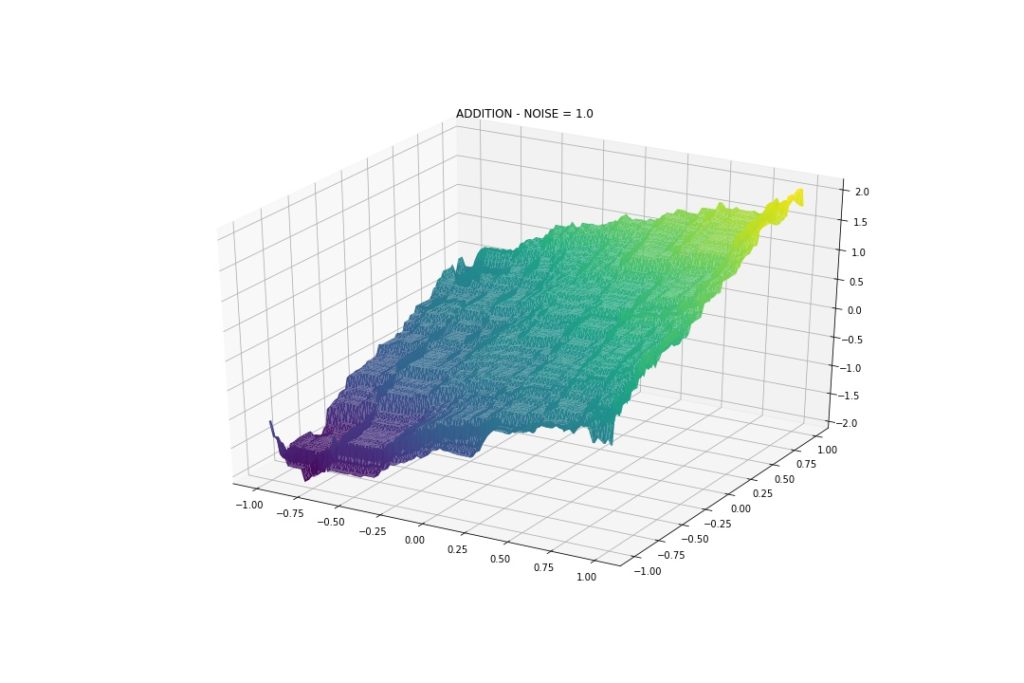
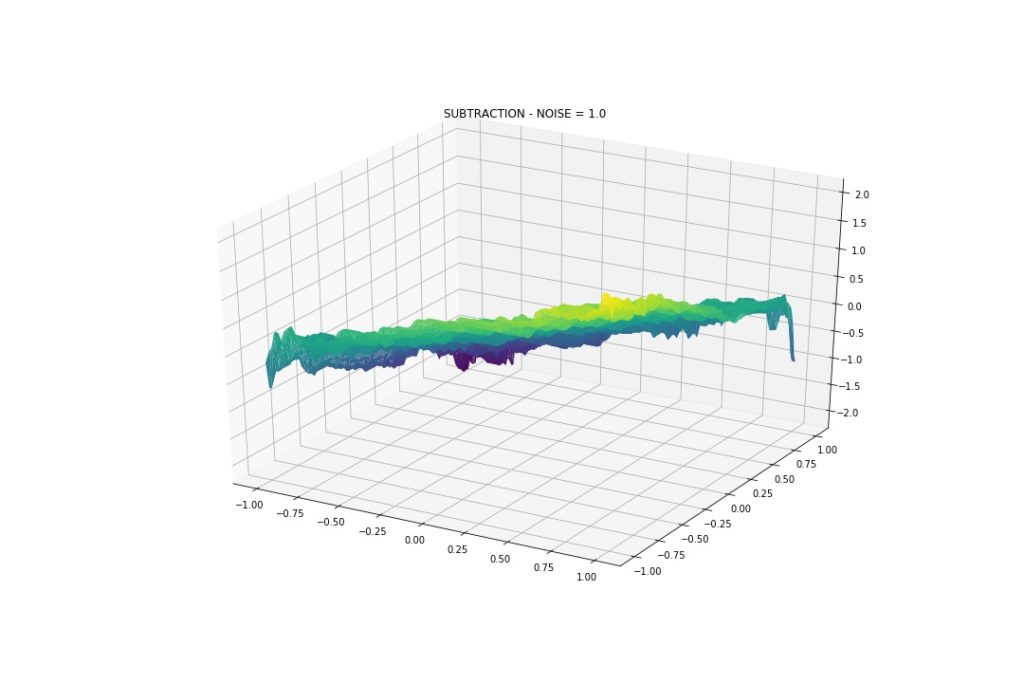
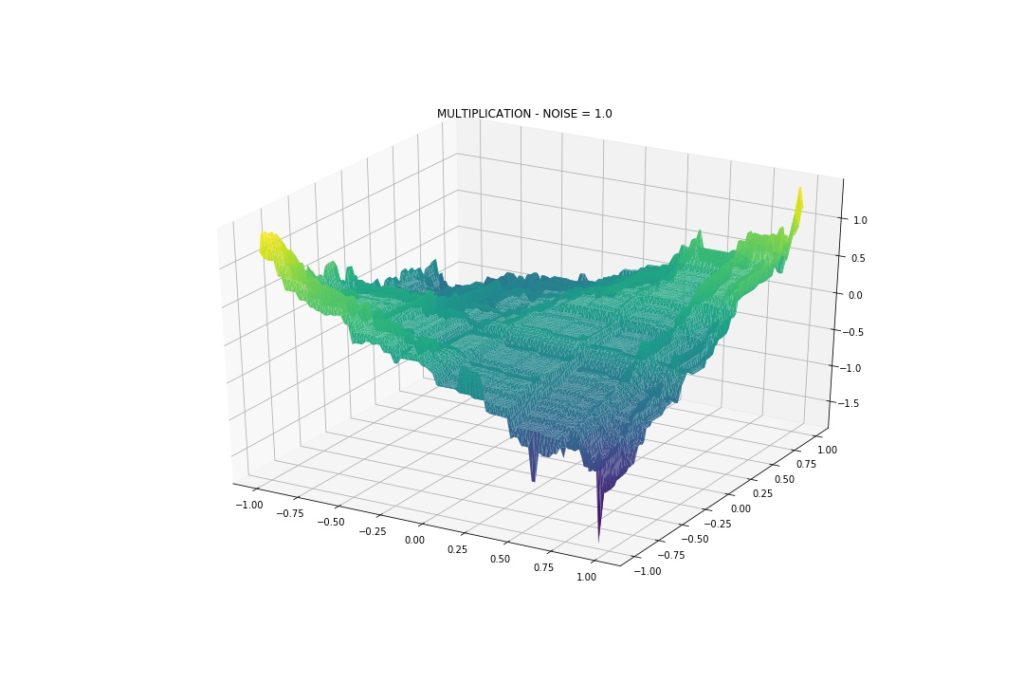
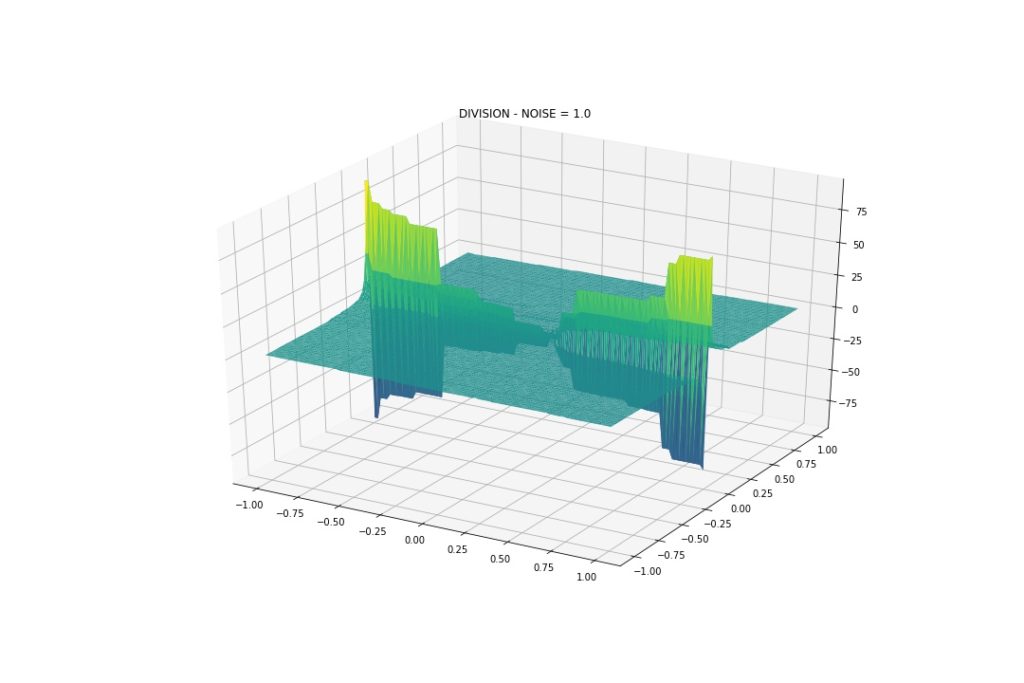
Even more wiggly! But again, it can approximate the interactions.
Updated Rule of Thumb
So, what all this means for our day-to-day modeling? Can GBMs do simple arithmetic? The answer is YES.
The original comment still applies. If you want to really capture all the performance, and you know the interactions really apply, you should **EXPLICITLY **create them features. This way the model doesn’t have to struggle so much to find the splits and thread through noise.
Now, if you really don’t want to create the interactions, here are some ideas that may help the model approximate it better:
- Adding more examples
- Tuning the hyperparameters
- Use a model that is more adequate to the known form of the interaction